 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs It Novel and Why? Fine-Grained Patent Novelty Prediction Based on Passage Retrieval
May 04, 2026Novelty assessment is a critical yet complex task in the examination process for patent acceptance, requiring examiners to determine whether an invention is disclosed in a prior art document. The process involves intricate matching between specific features of a patent claim and passages in the prior art. While prior work has approached novelty prediction primarily as a binary classification task at the claim level, we argue that this formulation is susceptible to spurious correlations and lacks the granularity required for practical application. In this work, we introduce FiNE-Patents (Fine-grained Novelty Examination of Patents), a novel dataset comprising 3,658 first patent claims annotated with fine-grained, feature-level prior art references extracted from European Search Opinion (ESOP) documents. We propose shifting the evaluation paradigm from simple binary classification to a joint retrieval and abstract reasoning task at the feature level, requiring models to identify specific passages from a prior art document that disclose individual claim features, and to identify which features of a claim make it novel. We implement and evaluate LLM-based workflows that decompose claims into features, analyze each feature against prior art, and finally derive a claim-level novelty prediction. Our experiments demonstrate that these workflows outperform embedding-based baselines on passage retrieval and novel feature identification. Furthermore, we show that unlike trained classifiers, LLMs are robust against spurious correlations present in the claim-level novelty classification task. We release the dataset and code to foster further research into transparent and granular patent analysis.
PEDANTIC: A Dataset for the Automatic Examination of Definiteness in Patent Claims
May 28, 2025



Patent claims define the scope of protection for an invention. If there are ambiguities in a claim, it is rejected by the patent office. In the US, this is referred to as indefiniteness (35 U.S.C {\S} 112(b)) and is among the most frequent reasons for patent application rejection. The development of automatic methods for patent definiteness examination has the potential to make patent drafting and examination more efficient, but no annotated dataset has been published to date. We introduce PEDANTIC (Patent Definiteness Examination Corpus), a novel dataset of 14k US patent claims from patent applications relating to Natural Language Processing (NLP), annotated with reasons for indefiniteness. We construct PEDANTIC using a fully automatic pipeline that retrieves office action documents from the USPTO and uses Large Language Models (LLMs) to extract the reasons for indefiniteness. A human validation study confirms the pipeline's accuracy in generating high-quality annotations. To gain insight beyond binary classification metrics, we implement an LLM-as-Judge evaluation that compares the free-form reasoning of every model-cited reason with every examiner-cited reason. We show that LLM agents based on Qwen 2.5 32B and 72B struggle to outperform logistic regression baselines on definiteness prediction, even though they often correctly identify the underlying reasons. PEDANTIC provides a valuable resource for patent AI researchers, enabling the development of advanced examination models. We will publicly release the dataset and code.
Pap2Pat: Towards Automated Paper-to-Patent Drafting using Chunk-based Outline-guided Generation
Oct 09, 2024



The patent domain is gaining attention in natural language processing research, offering practical applications in streamlining the patenting process and providing challenging benchmarks for large language models (LLMs). However, the generation of the description sections of patents, which constitute more than 90% of the patent document, has not been studied to date. We address this gap by introducing the task of outline-guided paper-to-patent generation, where an academic paper provides the technical specification of the invention and an outline conveys the desired patent structure. We present PAP2PAT, a new challenging benchmark of 1.8k patent-paper pairs with document outlines, collected using heuristics that reflect typical research lab practices. Our experiments with current open-weight LLMs and outline-guided chunk-based generation show that they can effectively use information from the paper but struggle with repetitions, likely due to the inherent repetitiveness of patent language. We release our data and code.
A Wind of Change: Detecting and Evaluating Lexical Semantic Change across Times and Domains
Jun 07, 2019
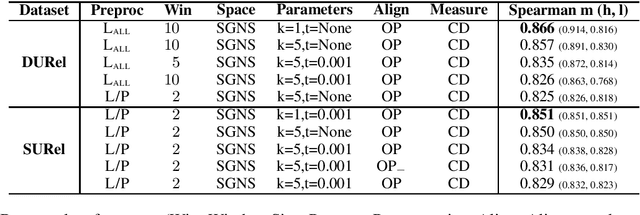
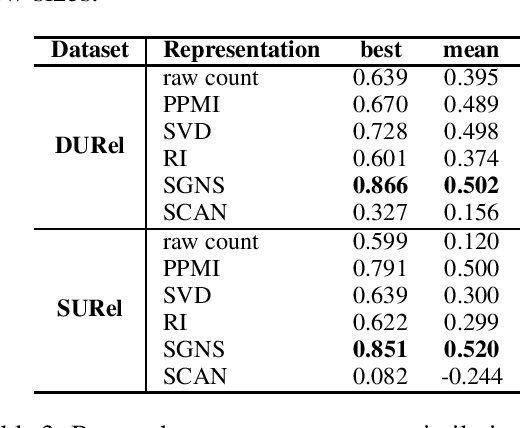
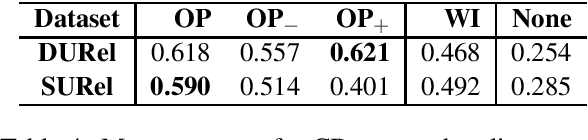
We perform an interdisciplinary large-scale evaluation for detecting lexical semantic divergences in a diachronic and in a synchronic task: semantic sense changes across time, and semantic sense changes across domains. Our work addresses the superficialness and lack of comparison in assessing models of diachronic lexical change, by bringing together and extending benchmark models on a common state-of-the-art evaluation task. In addition, we demonstrate that the same evaluation task and modelling approaches can successfully be utilised for the synchronic detection of domain-specific sense divergences in the field of term extraction.