 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS. V. N. Vishwanathan
Totally Corrective Boosting with Cardinality Penalization
Apr 07, 2015
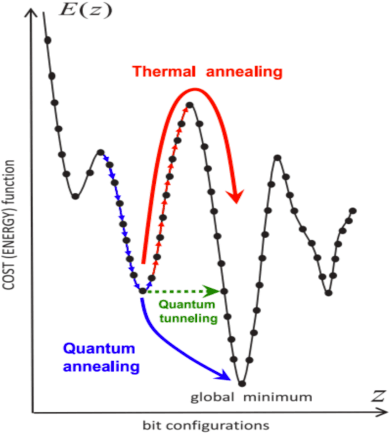
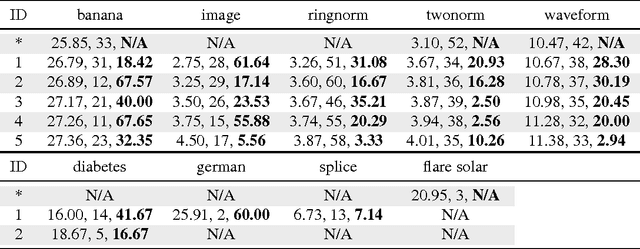

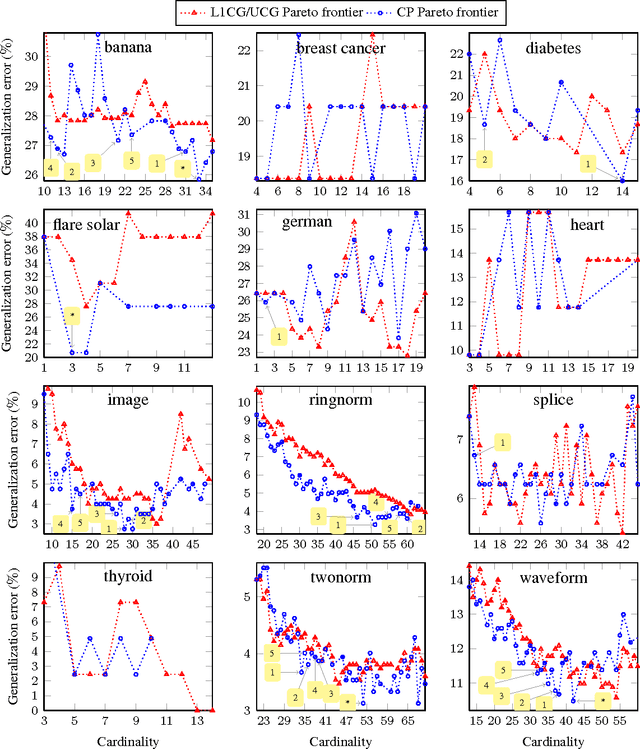
We propose a totally corrective boosting algorithm with explicit cardinality regularization. The resulting combinatorial optimization problems are not known to be efficiently solvable with existing classical methods, but emerging quantum optimization technology gives hope for achieving sparser models in practice. In order to demonstrate the utility of our algorithm, we use a distributed classical heuristic optimizer as a stand-in for quantum hardware. Even though this evaluation methodology incurs large time and resource costs on classical computing machinery, it allows us to gauge the potential gains in generalization performance and sparsity of the resulting boosted ensembles. Our experimental results on public data sets commonly used for benchmarking of boosting algorithms decidedly demonstrate the existence of such advantages. If actual quantum optimization were to be used with this algorithm in the future, we would expect equivalent or superior results at much smaller time and energy costs during training. Moreover, studying cardinality-penalized boosting also sheds light on why unregularized boosting algorithms with early stopping often yield better results than their counterparts with explicit convex regularization: Early stopping performs suboptimal cardinality regularization. The results that we present here indicate it is beneficial to explicitly solve the combinatorial problem still left open at early termination.
Ranking via Robust Binary Classification and Parallel Parameter Estimation in Large-Scale Data
Aug 21, 2014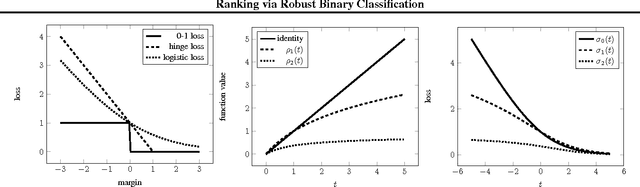
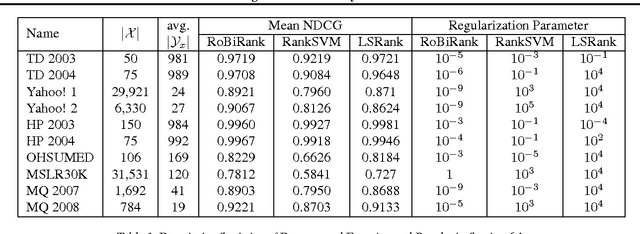
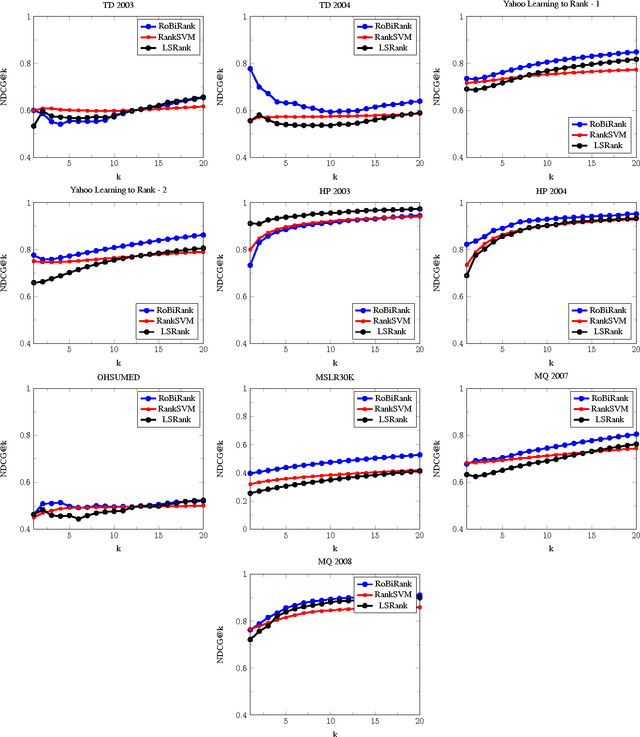
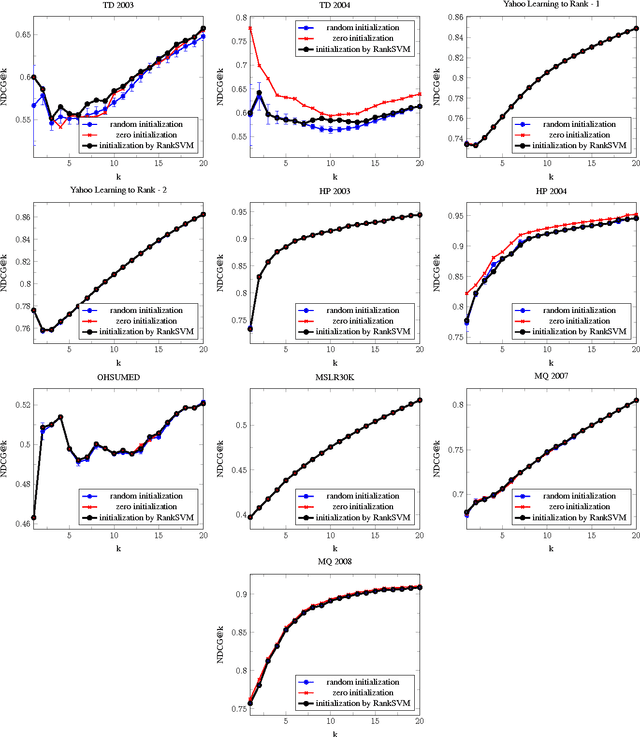
We propose RoBiRank, a ranking algorithm that is motivated by observing a close connection between evaluation metrics for learning to rank and loss functions for robust classification. The algorithm shows a very competitive performance on standard benchmark datasets against other representative algorithms in the literature. On the other hand, in large scale problems where explicit feature vectors and scores are not given, our algorithm can be efficiently parallelized across a large number of machines; for a task that requires 386,133 x 49,824,519 pairwise interactions between items to be ranked, our algorithm finds solutions that are of dramatically higher quality than that can be found by a state-of-the-art competitor algorithm, given the same amount of wall-clock time for computation.
DFacTo: Distributed Factorization of Tensors
Jun 17, 2014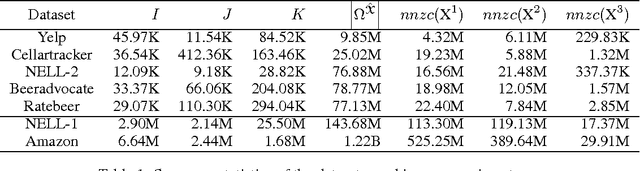
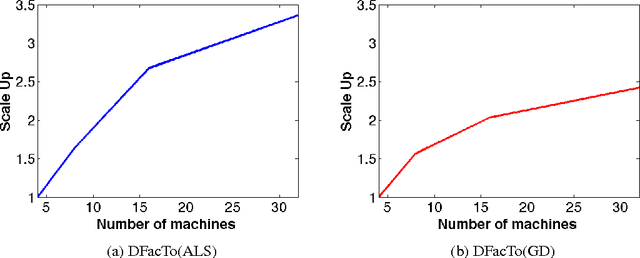
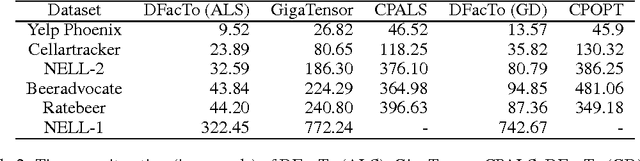
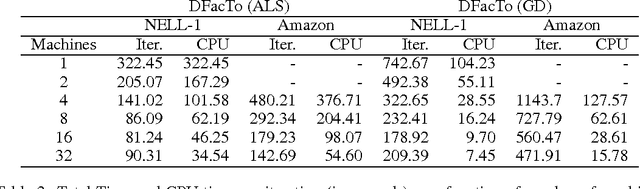
We present a technique for significantly speeding up Alternating Least Squares (ALS) and Gradient Descent (GD), two widely used algorithms for tensor factorization. By exploiting properties of the Khatri-Rao product, we show how to efficiently address a computationally challenging sub-step of both algorithms. Our algorithm, DFacTo, only requires two sparse matrix-vector products and is easy to parallelize. DFacTo is not only scalable but also on average 4 to 10 times faster than competing algorithms on a variety of datasets. For instance, DFacTo only takes 480 seconds on 4 machines to perform one iteration of the ALS algorithm and 1,143 seconds to perform one iteration of the GD algorithm on a 6.5 million x 2.5 million x 1.5 million dimensional tensor with 1.2 billion non-zero entries.
The Structurally Smoothed Graphlet Kernel
Mar 03, 2014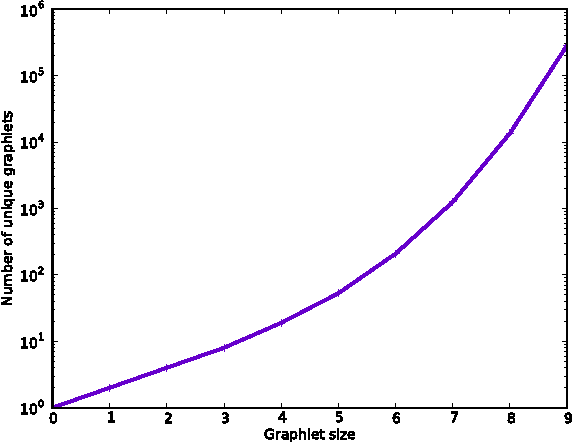
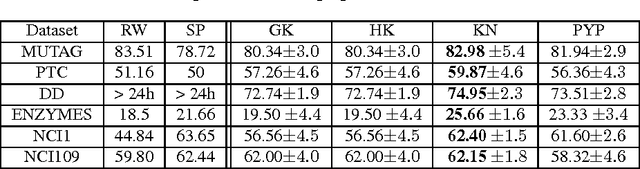
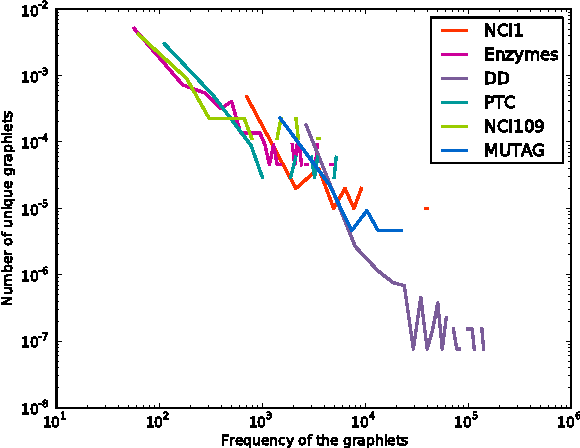
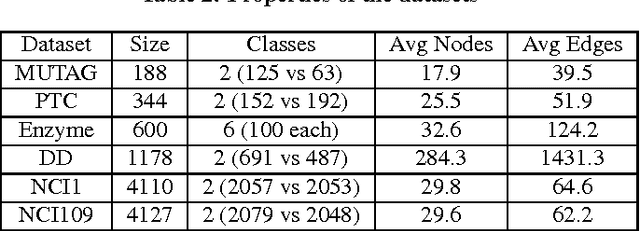
A commonly used paradigm for representing graphs is to use a vector that contains normalized frequencies of occurrence of certain motifs or sub-graphs. This vector representation can be used in a variety of applications, such as, for computing similarity between graphs. The graphlet kernel of Shervashidze et al. [32] uses induced sub-graphs of k nodes (christened as graphlets by Przulj [28]) as motifs in the vector representation, and computes the kernel via a dot product between these vectors. One can easily show that this is a valid kernel between graphs. However, such a vector representation suffers from a few drawbacks. As k becomes larger we encounter the sparsity problem; most higher order graphlets will not occur in a given graph. This leads to diagonal dominance, that is, a given graph is similar to itself but not to any other graph in the dataset. On the other hand, since lower order graphlets tend to be more numerous, using lower values of k does not provide enough discrimination ability. We propose a smoothing technique to tackle the above problems. Our method is based on a novel extension of Kneser-Ney and Pitman-Yor smoothing techniques from natural language processing to graphs. We use the relationships between lower order and higher order graphlets in order to derive our method. Consequently, our smoothing algorithm not only respects the dependency between sub-graphs but also tackles the diagonal dominance problem by distributing the probability mass across graphlets. In our experiments, the smoothed graphlet kernel outperforms graph kernels based on raw frequency counts.
Modeling Attractiveness and Multiple Clicks in Sponsored Search Results
Jan 01, 2014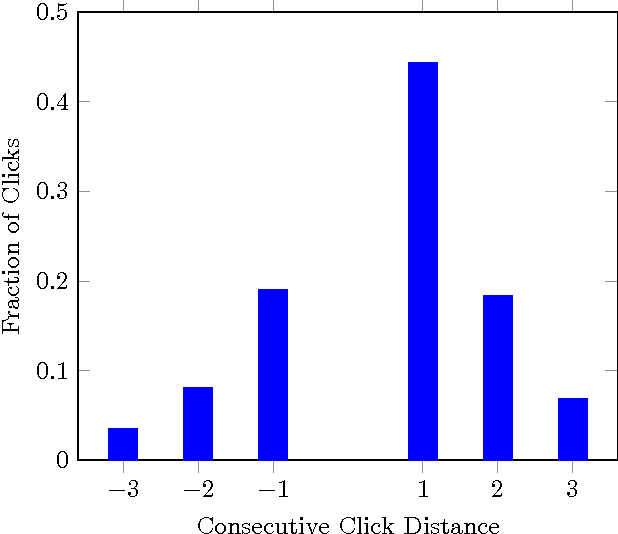
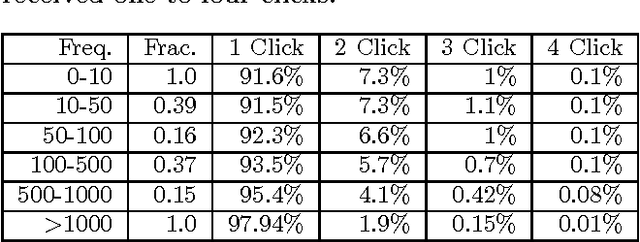
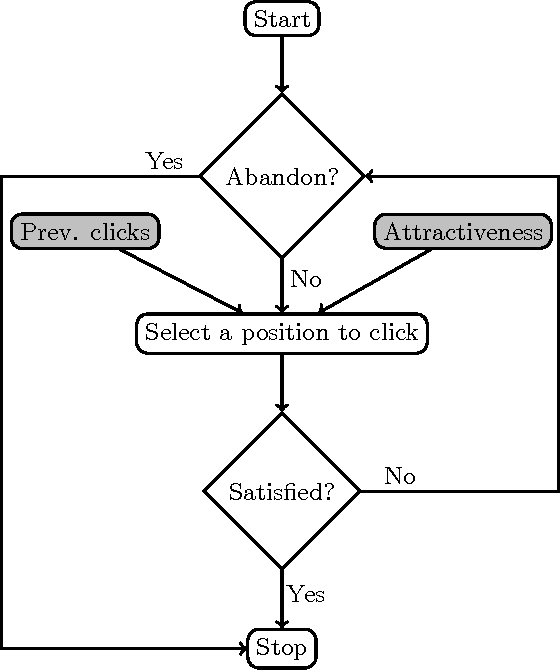
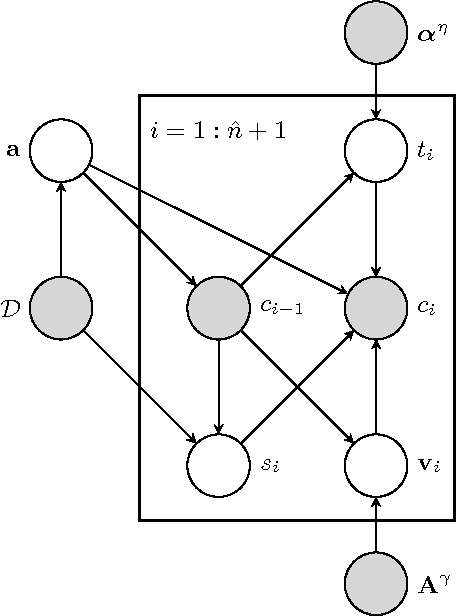
Click models are an important tool for leveraging user feedback, and are used by commercial search engines for surfacing relevant search results. However, existing click models are lacking in two aspects. First, they do not share information across search results when computing attractiveness. Second, they assume that users interact with the search results sequentially. Based on our analysis of the click logs of a commercial search engine, we observe that the sequential scan assumption does not always hold, especially for sponsored search results. To overcome the above two limitations, we propose a new click model. Our key insight is that sharing information across search results helps in identifying important words or key-phrases which can then be used to accurately compute attractiveness of a search result. Furthermore, we argue that the click probability of a position as well as its attractiveness changes during a user session and depends on the user's past click experience. Our model seamlessly incorporates the effect of externalities (quality of other search results displayed in response to a user query), user fatigue, as well as pre and post-click relevance of a sponsored search result. We propose an efficient one-pass inference scheme and empirically evaluate the performance of our model via extensive experiments using the click logs of a large commercial search engine.
Efficiently Sampling Multiplicative Attribute Graphs Using a Ball-Dropping Process
Feb 28, 2012
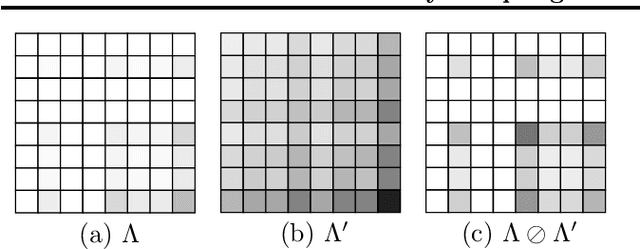
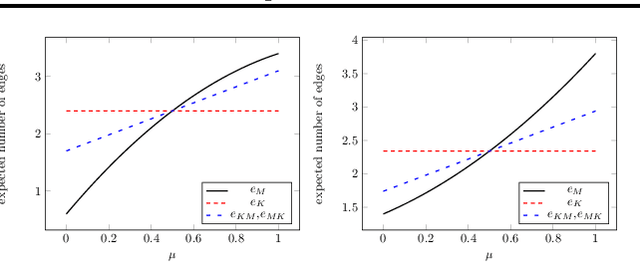
We introduce a novel and efficient sampling algorithm for the Multiplicative Attribute Graph Model (MAGM - Kim and Leskovec (2010)}). Our algorithm is \emph{strictly} more efficient than the algorithm proposed by Yun and Vishwanathan (2012), in the sense that our method extends the \emph{best} time complexity guarantee of their algorithm to a larger fraction of parameter space. Both in theory and in empirical evaluation on sparse graphs, our new algorithm outperforms the previous one. To design our algorithm, we first define a stochastic \emph{ball-dropping process} (BDP). Although a special case of this process was introduced as an efficient approximate sampling algorithm for the Kronecker Product Graph Model (KPGM - Leskovec et al. (2010)}), neither \emph{why} such an approximation works nor \emph{what} is the actual distribution this process is sampling from has been addressed so far to the best of our knowledge. Our rigorous treatment of the BDP enables us to clarify the rational behind a BDP approximation of KPGM, and design an efficient sampling algorithm for the MAGM.
Quilting Stochastic Kronecker Product Graphs to Generate Multiplicative Attribute Graphs
Feb 09, 2012
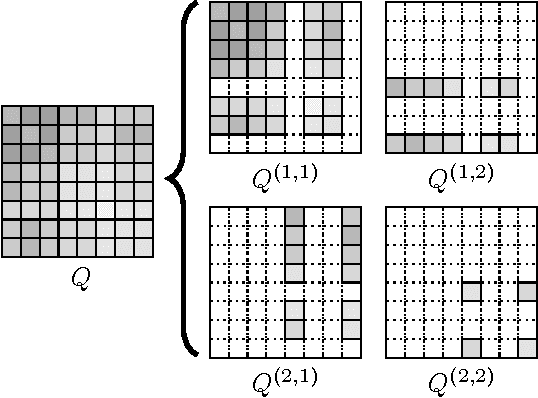
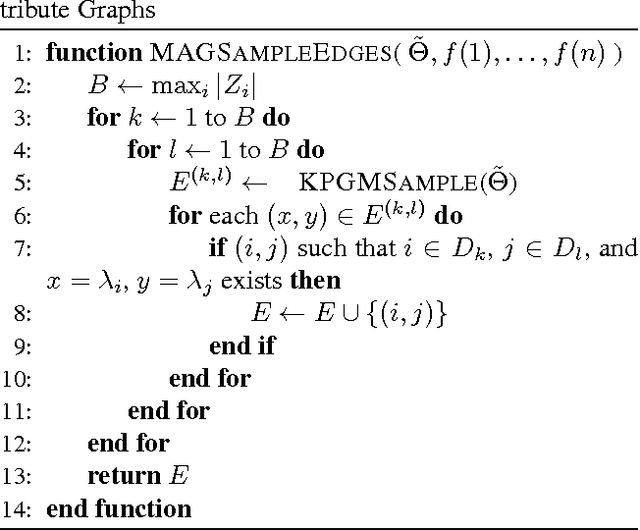
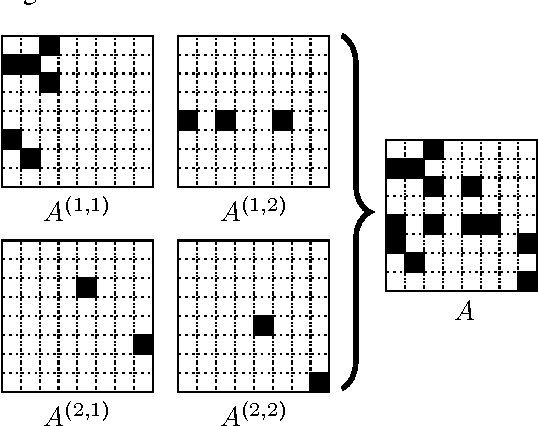
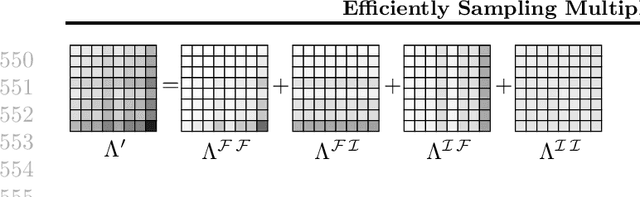
We describe the first sub-quadratic sampling algorithm for the Multiplicative Attribute Graph Model (MAGM) of Kim and Leskovec (2010). We exploit the close connection between MAGM and the Kronecker Product Graph Model (KPGM) of Leskovec et al. (2010), and show that to sample a graph from a MAGM it suffices to sample small number of KPGM graphs and \emph{quilt} them together. Under a restricted set of technical conditions our algorithm runs in $O((\log_2(n))^3 |E|)$ time, where $n$ is the number of nodes and $|E|$ is the number of edges in the sampled graph. We demonstrate the scalability of our algorithm via extensive empirical evaluation; we can sample a MAGM graph with 8 million nodes and 20 billion edges in under 6 hours.
Distributed Autonomous Online Learning: Regrets and Intrinsic Privacy-Preserving Properties
Feb 04, 2011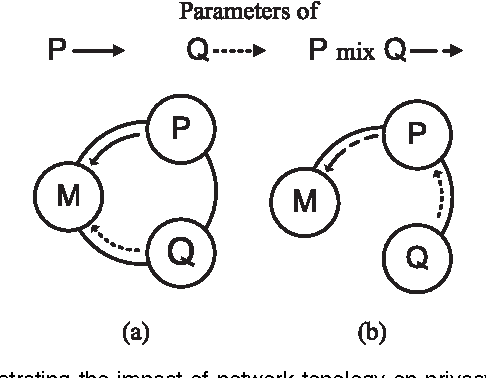
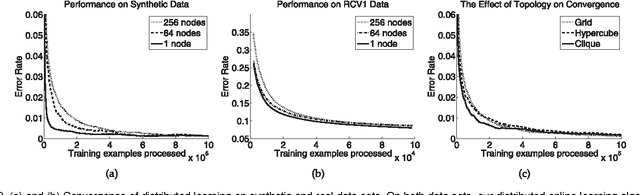
Online learning has become increasingly popular on handling massive data. The sequential nature of online learning, however, requires a centralized learner to store data and update parameters. In this paper, we consider online learning with {\em distributed} data sources. The autonomous learners update local parameters based on local data sources and periodically exchange information with a small subset of neighbors in a communication network. We derive the regret bound for strongly convex functions that generalizes the work by Ram et al. (2010) for convex functions. Most importantly, we show that our algorithm has \emph{intrinsic} privacy-preserving properties, and we prove the sufficient and necessary conditions for privacy preservation in the network. These conditions imply that for networks with greater-than-one connectivity, a malicious learner cannot reconstruct the subgradients (and sensitive raw data) of other learners, which makes our algorithm appealing in privacy sensitive applications.
Regularized Risk Minimization by Nesterov's Accelerated Gradient Methods: Algorithmic Extensions and Empirical Studies
Nov 01, 2010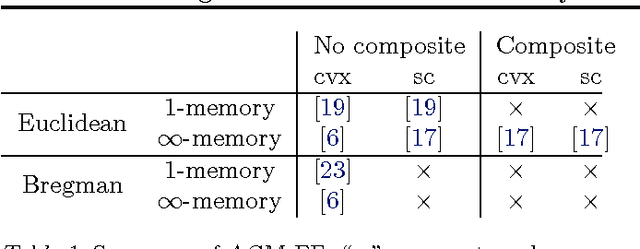
Nesterov's accelerated gradient methods (AGM) have been successfully applied in many machine learning areas. However, their empirical performance on training max-margin models has been inferior to existing specialized solvers. In this paper, we first extend AGM to strongly convex and composite objective functions with Bregman style prox-functions. Our unifying framework covers both the $\infty$-memory and 1-memory styles of AGM, tunes the Lipschiz constant adaptively, and bounds the duality gap. Then we demonstrate various ways to apply this framework of methods to a wide range of machine learning problems. Emphasis will be given on their rate of convergence and how to efficiently compute the gradient and optimize the models. The experimental results show that with our extensions AGM outperforms state-of-the-art solvers on max-margin models.
New Approximation Algorithms for Minimum Enclosing Convex Shapes
Sep 15, 2010
Given $n$ points in a $d$ dimensional Euclidean space, the Minimum Enclosing Ball (MEB) problem is to find the ball with the smallest radius which contains all $n$ points. We give a $O(nd\Qcal/\sqrt{\epsilon})$ approximation algorithm for producing an enclosing ball whose radius is at most $\epsilon$ away from the optimum (where $\Qcal$ is an upper bound on the norm of the points). This improves existing results using \emph{coresets}, which yield a $O(nd/\epsilon)$ greedy algorithm. Finding the Minimum Enclosing Convex Polytope (MECP) is a related problem wherein a convex polytope of a fixed shape is given and the aim is to find the smallest magnification of the polytope which encloses the given points. For this problem we present a $O(mnd\Qcal/\epsilon)$ approximation algorithm, where $m$ is the number of faces of the polytope. Our algorithms borrow heavily from convex duality and recently developed techniques in non-smooth optimization, and are in contrast with existing methods which rely on geometric arguments. In particular, we specialize the excessive gap framework of \citet{Nesterov05a} to obtain our results.