 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Camera Self-Calibration in Sports Motion Capture: Leveraging Human and Stick Poses
Apr 19, 2026Multi-camera systems are widely employed in sports to capture the 3D motion of athletes and equipment, yet calibrating their extrinsic parameters remains costly and labor-intensive. We introduce an efficient, tool-free method for multi-camera extrinsic calibration tailored to sports involving stick-like implements (e.g., golf clubs, bats, hockey sticks). Our approach jointly exploits two complementary cues from synchronized multi-camera videos: (i) human body keypoints with unknown metric scale and (ii) a rigid stick-like implement of known length. We formulate a three-stage optimization pipeline that refines camera extrinsics, reconstructs human and stick trajectories, and resolves global scale via the stick-length constraint. Our method achieves accurate extrinsic calibration without dedicated calibration tools. To benchmark this task, we present the first dataset for multi-camera self-calibration in stick-based sports, consisting of synthetic sequences across four sports categories with 3 to 10 cameras. Comprehensive experiments demonstrate that our method delivers SOTA performance, achieving low rotation and translation errors. Our project page: https://fandulu.github.io/sport_stick_multi_cam_calib/.
Enhancing Ambiguous Dynamic Facial Expression Recognition with Soft Label-based Data Augmentation
Jun 25, 2025



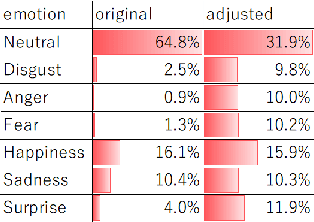
Dynamic facial expression recognition (DFER) is a task that estimates emotions from facial expression video sequences. For practical applications, accurately recognizing ambiguous facial expressions -- frequently encountered in in-the-wild data -- is essential. In this study, we propose MIDAS, a data augmentation method designed to enhance DFER performance for ambiguous facial expression data using soft labels representing probabilities of multiple emotion classes. MIDAS augments training data by convexly combining pairs of video frames and their corresponding emotion class labels. This approach extends mixup to soft-labeled video data, offering a simple yet highly effective method for handling ambiguity in DFER. To evaluate MIDAS, we conducted experiments on both the DFEW dataset and FERV39k-Plus, a newly constructed dataset that assigns soft labels to an existing DFER dataset. The results demonstrate that models trained with MIDAS-augmented data achieve superior performance compared to the state-of-the-art method trained on the original dataset.
Action Units Recognition by Pairwise Deep Architecture
Oct 02, 2020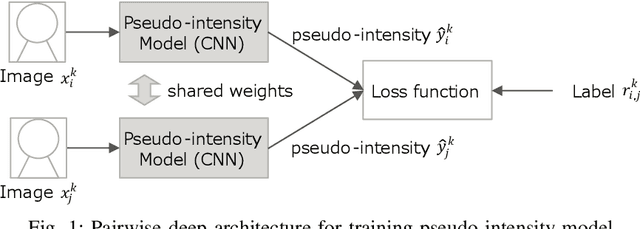

In this paper, we propose a new automatic Action Units (AUs) recognition method used in a competition, Affective Behavior Analysis in-the-wild (ABAW). Our method tackles a problem of AUs label inconsistency among subjects by using pairwise deep architecture. While the baseline score is 0.31, our method achieved 0.67 in validation dataset of the competition.
A Multi-term and Multi-task Analyzing Framework for Affective Analysis in-the-wild
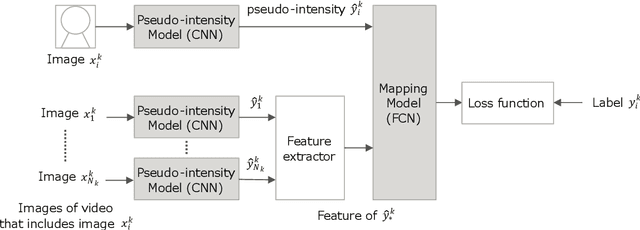
Oct 02, 2020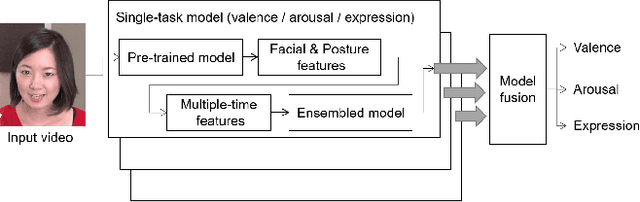
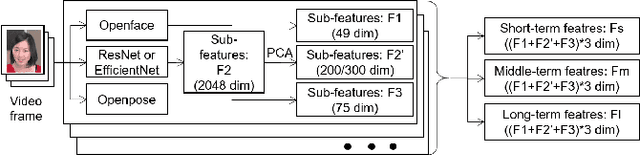
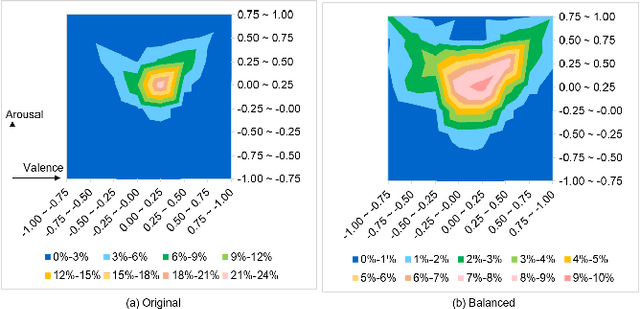
Human affective recognition is an important factor in human-computer interaction. However, the method development with in-the-wild data is not yet accurate enough for practical usage. In this paper, we introduce the affective recognition method focusing on valence-arousal (VA) and expression (EXP) that was submitted to the Affective Behavior Analysis in-the-wild (ABAW) 2020 Contest. Since we considered that affective behaviors have many observable features that have their own time frames, we introduced multiple optimized time windows (short-term, middle-term, and long-term) into our analyzing framework for extracting feature parameters from video data. Moreover, multiple modality data are used, including action units, head poses, gaze, posture, and ResNet 50 or Efficient NET features, and are optimized during the extraction of these features. Then, we generated affective recognition models for each time window and ensembled these models together. Also, we fussed the valence, arousal, and expression models together to enable the multi-task learning, considering the fact that the basic psychological states behind facial expressions are closely related to each another. In the validation set, our model achieved a valence-arousal score of 0.498 and a facial expression score of 0.471. These verification results reveal that our proposed framework can improve estimation accuracy and robustness effectively.