 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal e-prediction in the presence of confounding
Mar 11, 2026This note extends conformal e-prediction to cover the case where there is observed confounding between the random object $X$ and its label $Y$. We consider both the case where the observed data is IID and a case where some dependence between observations is permitted.
Adaptive Window Selection for Financial Risk Forecasting
Mar 01, 2026Risk forecasts in financial regulation and internal management are calculated through historical data. The unknown structural changes of financial data poses a substantial challenge in selecting an appropriate look-back window for risk modeling and forecasting. We develop a data-driven online learning method, called the bootstrap-based adaptive window selection (BAWS), that adaptively determines the window size in a sequential manner. A central component of BAWS is to compare the realized scores against a data-dependent threshold, which is evaluate based on an idea of bootstrap. The proposed method is applicable to the forecast of risk measures that are elicitable individually or jointly, such as the Value-at-Risk (VaR) and the pair of the VaR and the corresponding Expected Shortfall. Through simulation studies and empirical analyses, we demonstrate that BAWS generally outperforms the standard rolling window approach and the recently developed method of stability-based adaptive window selection, especially when there are structural changes in the data-generating process.
Online LLM watermark detection via e-processes
Feb 15, 2026Watermarking for large language models (LLMs) has emerged as an effective tool for distinguishing AI-generated text from human-written content. Statistically, watermark schemes induce dependence between generated tokens and a pseudo-random sequence, reducing watermark detection to a hypothesis testing problem on independence. We develop a unified framework for LLM watermark detection based on e-processes, providing anytime-valid guarantees for online testing. We propose various methods to construct empirically adaptive e-processes that can enhance the detection power. In addition, theoretical results are established to characterize the power properties of the proposed procedures. Some experiments demonstrate that the proposed framework achieves competitive performance compared to existing watermark detection methods.
Online monotone density estimation and log-optimal calibration
Feb 09, 2026We study the problem of online monotone density estimation, where density estimators must be constructed in a predictable manner from sequentially observed data. We propose two online estimators: an online analogue of the classical Grenander estimator, and an expert aggregation estimator inspired by exponential weighting methods from the online learning literature. In the well-specified stochastic setting, where the underlying density is monotone, we show that the expected cumulative log-likelihood gap between the online estimators and the true density admits an $O(n^{1/3})$ bound. We further establish a $\sqrt{n\log{n}}$ pathwise regret bound for the expert aggregation estimator relative to the best offline monotone estimator chosen in hindsight, under minimal regularity assumptions on the observed sequence. As an application of independent interest, we show that the problem of constructing log-optimal p-to-e calibrators for sequential hypothesis testing can be formulated as an online monotone density estimation problem. We adapt the proposed estimators to build empirically adaptive p-to-e calibrators and establish their optimality. Numerical experiments illustrate the theoretical results.
Choquet regularization for reinforcement learning
Aug 17, 2022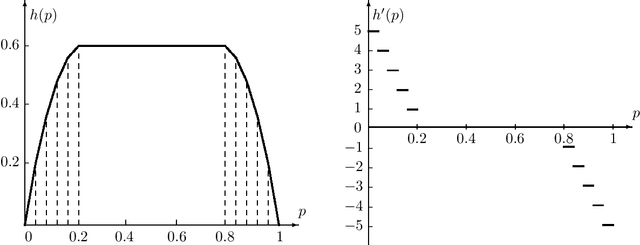
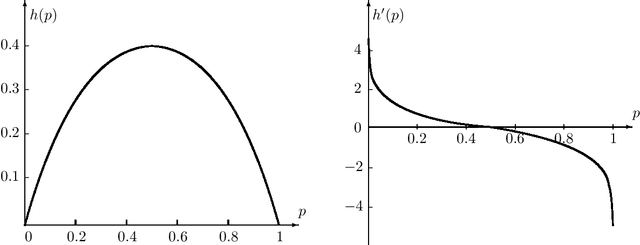
We propose \emph{Choquet regularizers} to measure and manage the level of exploration for reinforcement learning (RL), and reformulate the continuous-time entropy-regularized RL problem of Wang et al. (2020, JMLR, 21(198)) in which we replace the differential entropy used for regularization with a Choquet regularizer. We derive the Hamilton--Jacobi--Bellman equation of the problem, and solve it explicitly in the linear--quadratic (LQ) case via maximizing statically a mean--variance constrained Choquet regularizer. Under the LQ setting, we derive explicit optimal distributions for several specific Choquet regularizers, and conversely identify the Choquet regularizers that generate a number of broadly used exploratory samplers such as $\epsilon$-greedy, exponential, uniform and Gaussian.
A unified framework for bandit multiple testing
Jul 15, 2021
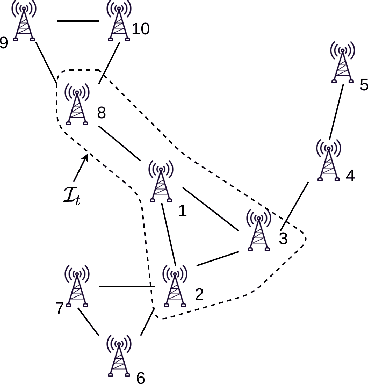
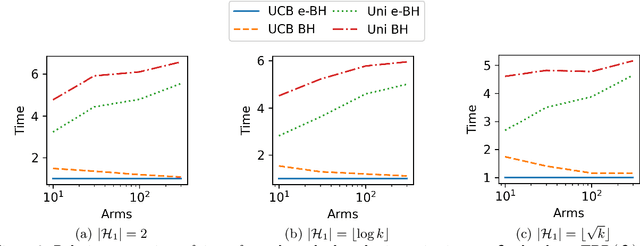

In bandit multiple hypothesis testing, each arm corresponds to a different null hypothesis that we wish to test, and the goal is to design adaptive algorithms that correctly identify large set of interesting arms (true discoveries), while only mistakenly identifying a few uninteresting ones (false discoveries). One common metric in non-bandit multiple testing is the false discovery rate (FDR). We propose a unified, modular framework for bandit FDR control that emphasizes the decoupling of exploration and summarization of evidence. We utilize the powerful martingale-based concept of ``e-processes'' to ensure FDR control for arbitrary composite nulls, exploration rules and stopping times in generic problem settings. In particular, valid FDR control holds even if the reward distributions of the arms could be dependent, multiple arms may be queried simultaneously, and multiple (cooperating or competing) agents may be querying arms, covering combinatorial semi-bandit type settings as well. Prior work has considered in great detail the setting where each arm's reward distribution is independent and sub-Gaussian, and a single arm is queried at each step. Our framework recovers matching sample complexity guarantees in this special case, and performs comparably or better in practice. For other settings, sample complexities will depend on the finer details of the problem (composite nulls being tested, exploration algorithm, data dependence structure, stopping rule) and we do not explore these; our contribution is to show that the FDR guarantee is clean and entirely agnostic to these details.