 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: A Benchmark for Programmatic Spatial-Temporal Reasoning
May 19, 2026Programmatic video generation through code offers geometric precision and temporal coherence beyond pixel-level diffusion models, yet rigorously evaluating whether language models can produce spatially correct animated outputs remains an open problem. We introduce PRISM, a large-scale benchmark of 10,372 human-calibrated instruction-code pairs (20 times larger than prior programmatic video generation benchmarks), grounded in real-world knowledge visualization scenarios across English and Chinese and spanning 437 subject categories. We further propose a funnel-style evaluation framework with four complementary metrics: Code-Level Reliability for executability, Spatial Reasoning for layout correctness over full animation sequences, and Prompt-Aware Dynamic Visual Complexity (PADVC) and Temporal Density (TD) for diagnosing dynamic expression and temporal activity. Systematic evaluation of seven mainstream LLMs reveals a striking Execution-Spatial Gap: the average drop from execution success rate to spatial pass rate is approximately 41%, showing that runnable code does not necessarily yield spatially coherent visual output. These findings show that programmatic video generation evaluation should go beyond executability. PRISM provides a principled benchmark for advancing spatially coherent code generation.
AgentXRay: White-Boxing Agentic Systems via Workflow Reconstruction
Feb 05, 2026Large Language Models have shown strong capabilities in complex problem solving, yet many agentic systems remain difficult to interpret and control due to opaque internal workflows. While some frameworks offer explicit architectures for collaboration, many deployed agentic systems operate as black boxes to users. We address this by introducing Agentic Workflow Reconstruction (AWR), a new task aiming to synthesize an explicit, interpretable stand-in workflow that approximates a black-box system using only input--output access. We propose AgentXRay, a search-based framework that formulates AWR as a combinatorial optimization problem over discrete agent roles and tool invocations in a chain-structured workflow space. Unlike model distillation, AgentXRay produces editable white-box workflows that match target outputs under an observable, output-based proxy metric, without accessing model parameters. To navigate the vast search space, AgentXRay employs Monte Carlo Tree Search enhanced by a scoring-based Red-Black Pruning mechanism, which dynamically integrates proxy quality with search depth. Experiments across diverse domains demonstrate that AgentXRay achieves higher proxy similarity and reduces token consumption compared to unpruned search, enabling deeper workflow exploration under fixed iteration budgets.
Towards Building a Real Time Mobile Device Bird Counting System Through Synthetic Data Training and Model Compression
Dec 28, 2019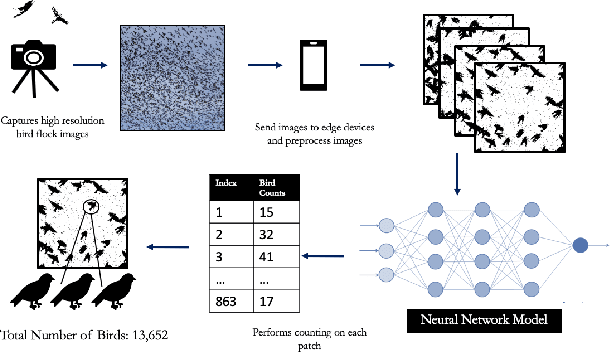

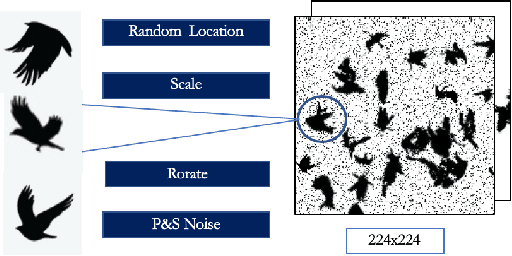
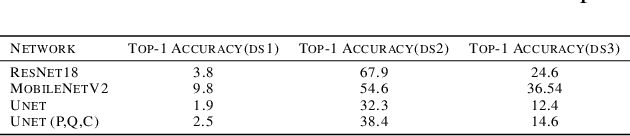
Counting the number of birds in an open sky setting has been an challenging problem due to the large number of bird flocks and the birds can overlap. Another difficulty is the lack of accurate training samples since the cost of labeling images of bird flocks can be extremely high and each sample picture can contain thousands of birds in a high resolution image. Inspired by recent work on training with synthetic data to perform crowd counting, we design a mechanism to generate synthetic bird dataset with precise bird count and the corresponding density maps. We then train a Unet model on the synthetic dataset to perform density map estimation that produces the count for each input. Our method is able to achieve MSE of approximately 12.4 on real dataset. In order to build a scalable system for fast bird counting under storage and computational constraints, we use model compression techniques and efficient model structures to increase the inference speed and save storage cost. We are able to reduce storage cost from 55MB to less than 5MB for the model with minimum loss of accuracy. This paper describes the pipelines of building an efficient bird counting system.
Not All Features Are Equal: Feature Leveling Deep Neural Networks for Better Interpretation
May 29, 2019
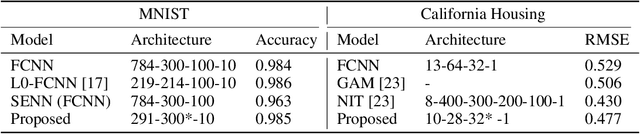
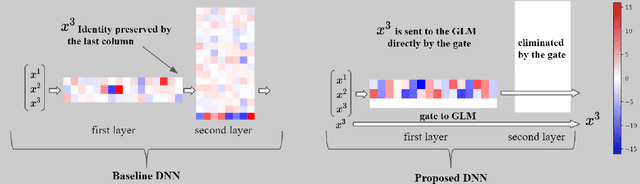
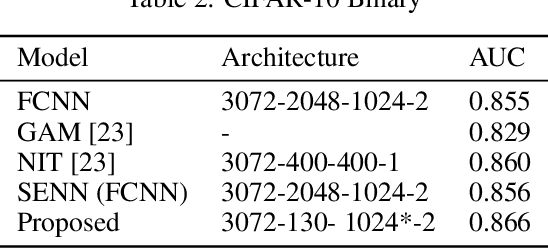
Self-explaining models are models that reveal decision making parameters in an interpretable manner so that the model reasoning process can be directly understood by human beings. General Linear Models (GLMs) are self-explaining because the model weights directly show how each feature contributes to the output value. However, deep neural networks (DNNs) are in general not self-explaining due to the non-linearity of the activation functions, complex architectures, obscure feature extraction and transformation process. In this work, we illustrate the fact that existing deep architectures are hard to interpret because each hidden layer carries a mix of low level features and high level features. As a solution, we propose a novel feature leveling architecture that isolates low level features from high level features on a per-layer basis to better utilize the GLM layer in the proposed architecture for interpretation. Experimental results show that our modified models are able to achieve competitive results comparing to main-stream architectures on standard datasets while being more self-explainable. Our implementations and configurations are publicly available for reproductions