 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Features Are Equal: Feature Leveling Deep Neural Networks for Better Interpretation
May 29, 2019
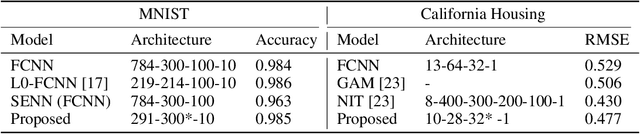
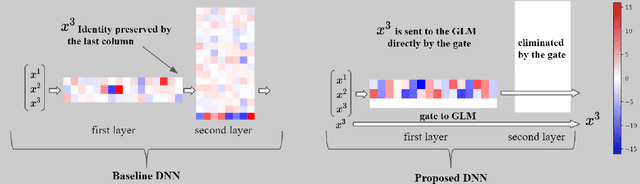
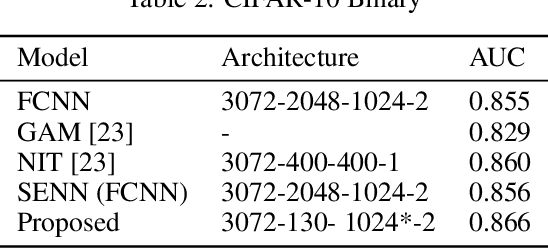
Self-explaining models are models that reveal decision making parameters in an interpretable manner so that the model reasoning process can be directly understood by human beings. General Linear Models (GLMs) are self-explaining because the model weights directly show how each feature contributes to the output value. However, deep neural networks (DNNs) are in general not self-explaining due to the non-linearity of the activation functions, complex architectures, obscure feature extraction and transformation process. In this work, we illustrate the fact that existing deep architectures are hard to interpret because each hidden layer carries a mix of low level features and high level features. As a solution, we propose a novel feature leveling architecture that isolates low level features from high level features on a per-layer basis to better utilize the GLM layer in the proposed architecture for interpretation. Experimental results show that our modified models are able to achieve competitive results comparing to main-stream architectures on standard datasets while being more self-explainable. Our implementations and configurations are publicly available for reproductions
The Level Weighted Structural Similarity Loss: A Step Away from the MSE
Apr 30, 2019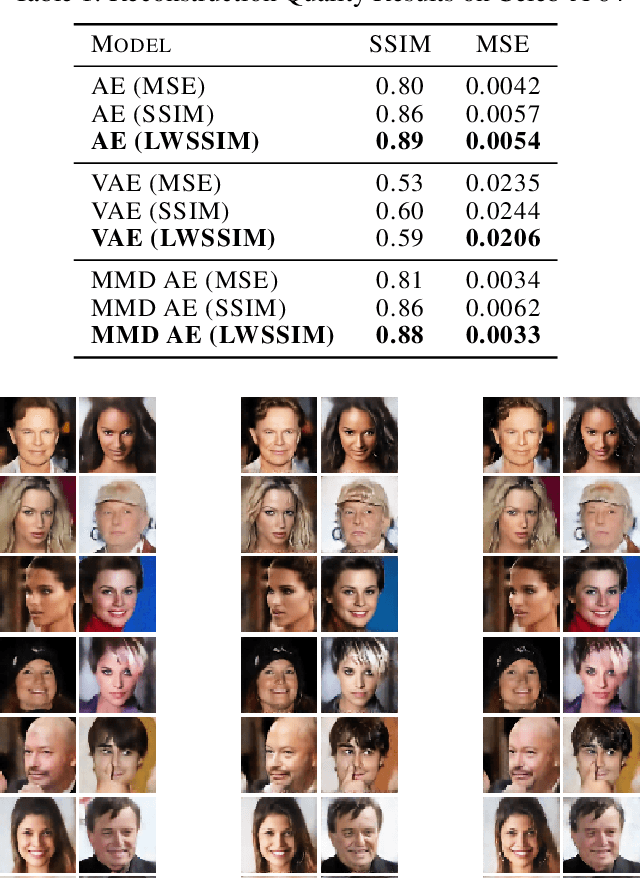
The Mean Square Error (MSE) has shown its strength when applied in deep generative models such as Auto-Encoders to model reconstruction loss. However, in image domain especially, the limitation of MSE is obvious: it assumes pixel independence and ignores spatial relationships of samples. This contradicts most architectures of Auto-Encoders which use convolutional layers to extract spatial dependent features. We base on the structural similarity metric (SSIM) and propose a novel level weighted structural similarity (LWSSIM) loss for convolutional Auto-Encoders. Experiments on common datasets on various Auto-Encoder variants show that our loss is able to outperform the MSE loss and the Vanilla SSIM loss. We also provide reasons why our model is able to succeed in cases where the standard SSIM loss fails.
Cross Domain Image Generation through Latent Space Exploration with Adversarial Loss
May 24, 2018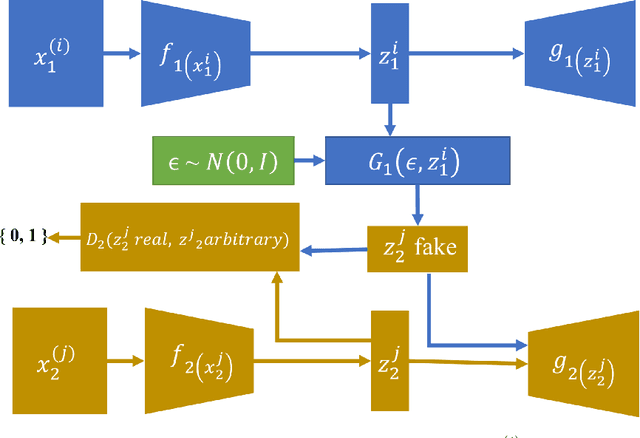
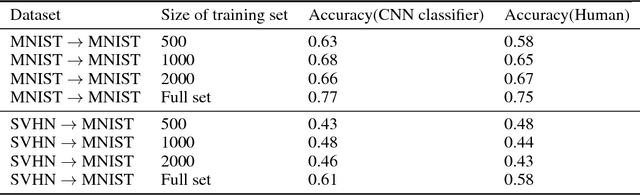
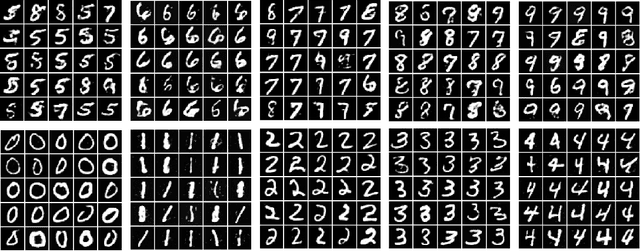

Conditional domain generation is a good way to interactively control sample generation process of deep generative models. However, once a conditional generative model has been created, it is often expensive to allow it to adapt to new conditional controls, especially the network structure is relatively deep. We propose a conditioned latent domain transfer framework across latent spaces of unconditional variational autoencoders(VAE). With this framework, we can allow unconditionally trained VAEs to generate images in its domain with conditionals provided by a latent representation of another domain. This framework does not assume commonalities between two domains. We demonstrate effectiveness and robustness of our model under widely used image datasets.