 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising Implicit Feedback for Cold-start Recommendation
Jun 17, 2026Implicit feedback is widely used in recommender systems due to its accessibility and generality, yet it usually presents noisy samples (e.g., clickbait, position bias). Meanwhile, recommenders inevitably face the item cold-start problem due to the continuous influx of new items. We identify that cold items are more prone to noisy samples due to the aforementioned factors, and researchers often overlook the significance of denoising implicit feedback for cold items. Previous denoising studies usually identify noisy samples based on heuristic patterns, such as higher loss values, and mitigate noise through sample selection or re-weighting. However, these methods have limited adaptability and are ineffective in cold-start scenarios. To achieve denoising implicit feedback for cold-start recommendation, we propose a model-agnostic denoising method called DIF. First, user preferences for content remain stable, which allows us to infer pseudo-labels indicating whether a user is interested in a cold item through content-similar warm items. Furthermore, to improve pseudo-label accuracy, we model the confidence of pseudo-labels based on the content similarity between the cold item and warm items, and then aggregate multiple pseudo-labels for each sample. Finally, we explicitly estimate the uncertainty of the noisy sample label by considering its relative entropy and the cold-start status of the item, which adaptively guides the role of pseudo-labels to correct the noisy labels at the sample level. DIF's superiority is supported by both theoretical justification and extensive experiments on real-world datasets. The method has been deployed on a billion-user scale short video application Kuaishou and has significantly improved various commercial metrics within cold-start scenarios.
Efficient Lung Cancer Image Classification and Segmentation Algorithm Based on Improved Swin Transformer
Jul 04, 2022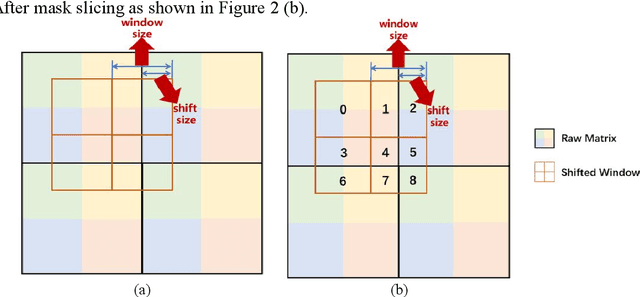
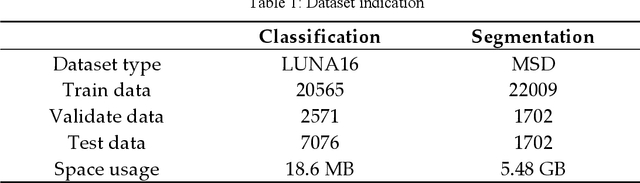
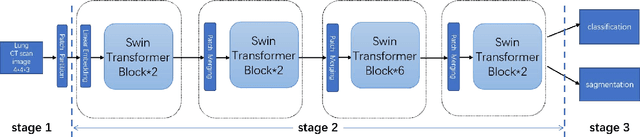
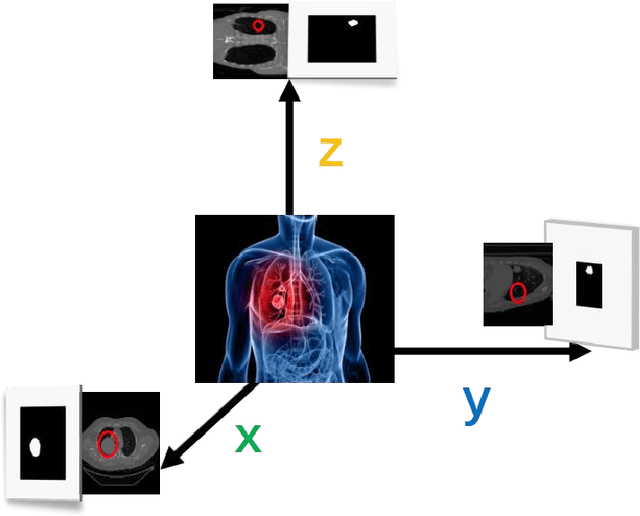
With the development of computer technology, various models have emerged in artificial intelligence. The transformer model has been applied to the field of computer vision (CV) after its success in natural language processing (NLP). Radiologists continue to face multiple challenges in today's rapidly evolving medical field, such as increased workload and increased diagnostic demands. Although there are some conventional methods for lung cancer detection before, their accuracy still needs to be improved, especially in realistic diagnostic scenarios. This paper creatively proposes a segmentation method based on efficient transformer and applies it to medical image analysis. The algorithm completes the task of lung cancer classification and segmentation by analyzing lung cancer data, and aims to provide efficient technical support for medical staff. In addition, we evaluated and compared the results in various aspects. For the classification mission, the max accuracy of Swin-T by regular training and Swin-B in two resolutions by pre-training can be up to 82.3%. For the segmentation mission, we use pre-training to help the model improve the accuracy of our experiments. The accuracy of the three models reaches over 95%. The experiments demonstrate that the algorithm can be well applied to lung cancer classification and segmentation missions.