 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising Implicit Feedback for Cold-start Recommendation
Jun 17, 2026Implicit feedback is widely used in recommender systems due to its accessibility and generality, yet it usually presents noisy samples (e.g., clickbait, position bias). Meanwhile, recommenders inevitably face the item cold-start problem due to the continuous influx of new items. We identify that cold items are more prone to noisy samples due to the aforementioned factors, and researchers often overlook the significance of denoising implicit feedback for cold items. Previous denoising studies usually identify noisy samples based on heuristic patterns, such as higher loss values, and mitigate noise through sample selection or re-weighting. However, these methods have limited adaptability and are ineffective in cold-start scenarios. To achieve denoising implicit feedback for cold-start recommendation, we propose a model-agnostic denoising method called DIF. First, user preferences for content remain stable, which allows us to infer pseudo-labels indicating whether a user is interested in a cold item through content-similar warm items. Furthermore, to improve pseudo-label accuracy, we model the confidence of pseudo-labels based on the content similarity between the cold item and warm items, and then aggregate multiple pseudo-labels for each sample. Finally, we explicitly estimate the uncertainty of the noisy sample label by considering its relative entropy and the cold-start status of the item, which adaptively guides the role of pseudo-labels to correct the noisy labels at the sample level. DIF's superiority is supported by both theoretical justification and extensive experiments on real-world datasets. The method has been deployed on a billion-user scale short video application Kuaishou and has significantly improved various commercial metrics within cold-start scenarios.
IBMEA: Exploring Variational Information Bottleneck for Multi-modal Entity Alignment
Jul 27, 2024



Multi-modal entity alignment (MMEA) aims to identify equivalent entities between multi-modal knowledge graphs (MMKGs), where the entities can be associated with related images. Most existing studies integrate multi-modal information heavily relying on the automatically-learned fusion module, rarely suppressing the redundant information for MMEA explicitly. To this end, we explore variational information bottleneck for multi-modal entity alignment (IBMEA), which emphasizes the alignment-relevant information and suppresses the alignment-irrelevant information in generating entity representations. Specifically, we devise multi-modal variational encoders to generate modal-specific entity representations as probability distributions. Then, we propose four modal-specific information bottleneck regularizers, limiting the misleading clues in refining modal-specific entity representations. Finally, we propose a modal-hybrid information contrastive regularizer to integrate all the refined modal-specific representations, enhancing the entity similarity between MMKGs to achieve MMEA. We conduct extensive experiments on two cross-KG and three bilingual MMEA datasets. Experimental results demonstrate that our model consistently outperforms previous state-of-the-art methods, and also shows promising and robust performance in low-resource and high-noise data scenarios.
In-plane prestressed hair clip mechanism for the fastest untethered compliant fish robot
Jul 18, 2022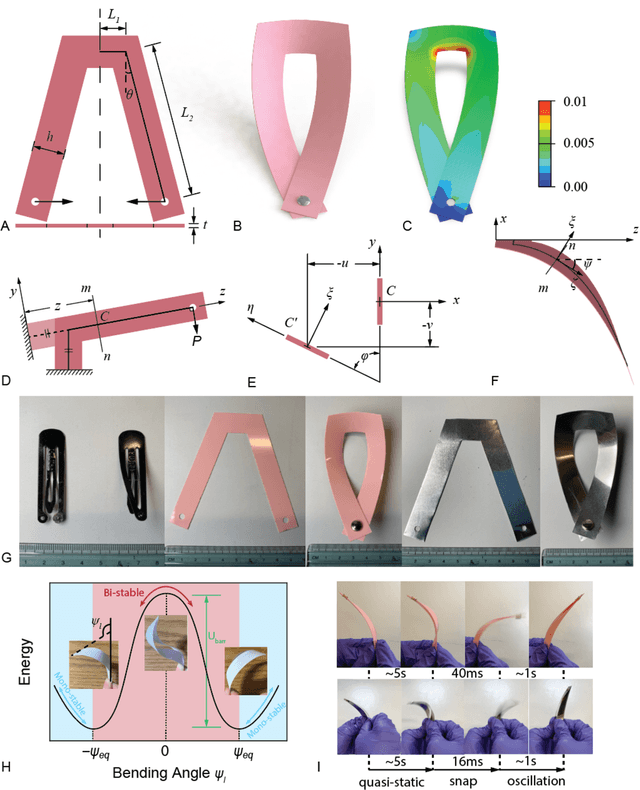
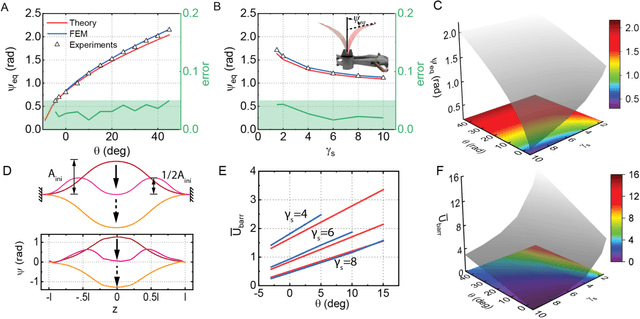
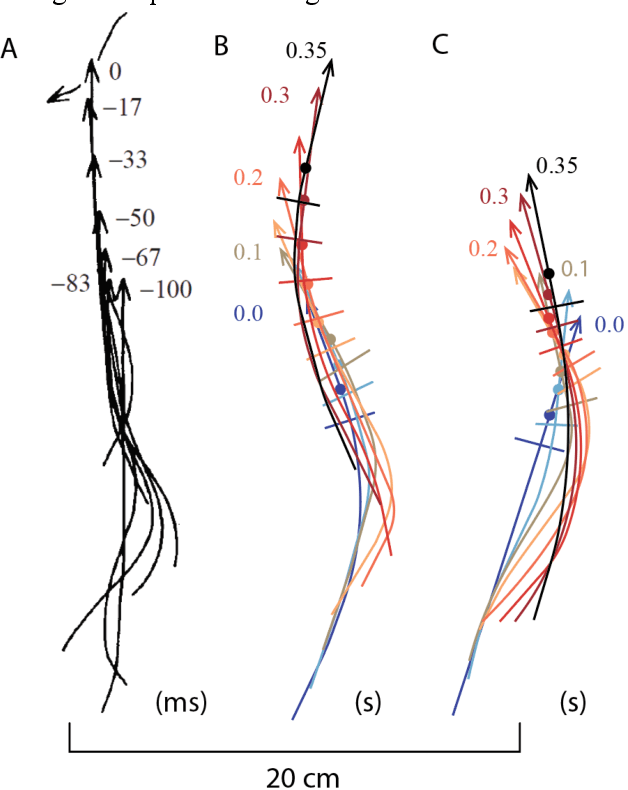

A trend has emerged over the past decades pointing to the harnessing of structural instability in movable, programmable, and transformable mechanisms. Inspired by a steel hair clip, we combine the in-plane assembly with a bistable structure and build a compliant flapping mechanism using semi-rigid plastic sheets and installed it on both a tethered pneumatic soft robotic fish and an untethered motor-driven one to demonstrate its unprecedented advantages. Designing rules are proposed following the theories and verification. A two-fold increase in the swimming speed of the pneumatic fish compared to the reference is observed and the further study of the untether fish demonstrates a record-breaking velocity of 2.03 BL/s (43.6 cm/s) for the untethered compliant swimmer, outperforming the previously report fastest one with a significant margin of 194%. This work probably heralds a structural revolution for next-generation compliant robotics.
Road-network-based Rapid Geolocalization
Jun 25, 2019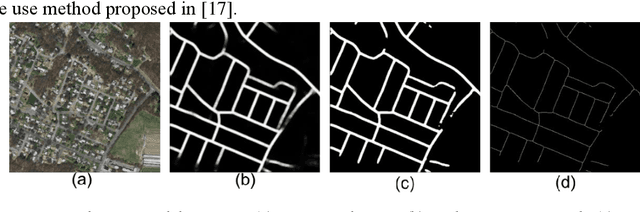
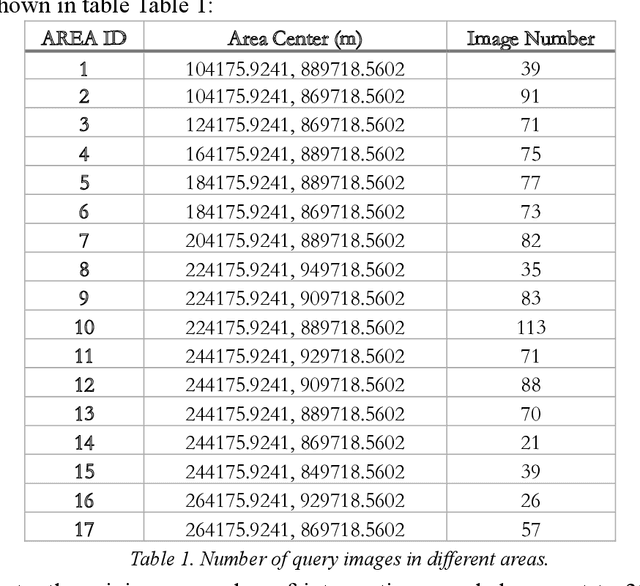

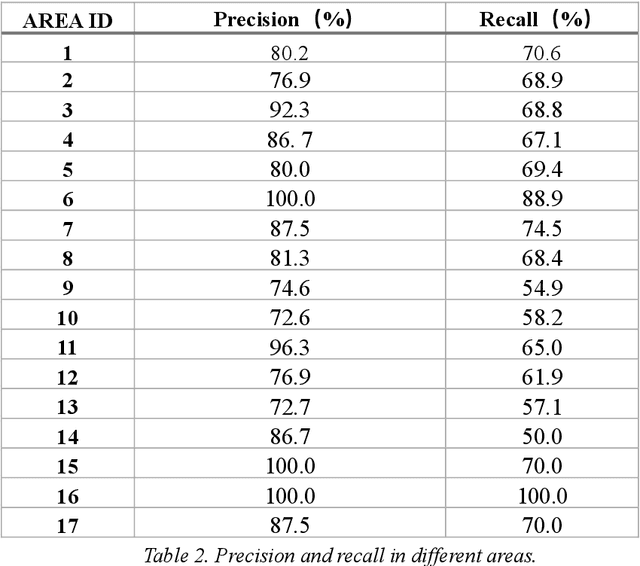
It has always been a research hotspot to use geographic information to assist the navigation of unmanned aerial vehicles. In this paper, a road-network-based localization method is proposed. We match roads in the measurement images to the reference road vector map, and realize successful localization on areas as large as a whole city. The road network matching problem is treated as a point cloud registration problem under two-dimensional projective transformation, and solved under a hypothesise-and-test framework. To deal with the projective point cloud registration problem, a global projective invariant feature is proposed, which consists of two road intersections augmented with the information of their tangents. We call it two road intersections tuple. We deduce the closed-form solution for determining the alignment transformation from a pair of matching two road intersections tuples. In addition, we propose the necessary conditions for the tuples to match. This can reduce the candidate matching tuples, thus accelerating the search to a great extent. We test all the candidate matching tuples under a hypothesise-and-test framework to search for the best match. The experiments show that our method can localize the target area over an area of 400 within 1 second on a single cpu.