 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUBLLM: A Novel Efficient Architecture with Token Sequence Subsampling for LLM
Jun 03, 2024While Large Language Models (LLMs) have achieved remarkable success in various fields, the efficiency of training and inference remains a major challenge. To address this issue, we propose SUBLLM, short for Subsampling-Upsampling-Bypass Large Language Model, an innovative architecture that extends the core decoder-only framework by incorporating subsampling, upsampling, and bypass modules. The subsampling modules are responsible for shortening the sequence, while the upsampling modules restore the sequence length, and the bypass modules enhance convergence. In comparison to LLaMA, the proposed SUBLLM exhibits significant enhancements in both training and inference speeds as well as memory usage, while maintaining competitive few-shot performance. During training, SUBLLM increases speeds by 26% and cuts memory by 10GB per GPU. In inference, it boosts speeds by up to 37% and reduces memory by 1GB per GPU. The training and inference speeds can be enhanced by 34% and 52% respectively when the context window is expanded to 8192. We shall release the source code of the proposed architecture in the published version.
Spiking Variational Graph Auto-Encoders for Efficient Graph Representation Learning
Oct 24, 2022



Graph representation learning is a fundamental research issue and benefits a wide range of applications on graph-structured data. Conventional artificial neural network-based methods such as graph neural networks (GNNs) and variational graph auto-encoders (VGAEs) have achieved promising results in learning on graphs, but they suffer from extremely high energy consumption during training and inference stages. Inspired by the bio-fidelity and energy-efficiency of spiking neural networks (SNNs), recent methods attempt to adapt GNNs to the SNN framework by substituting spiking neurons for the activation functions. However, existing SNN-based GNN methods cannot be applied to the more general multi-node representation learning problem represented by link prediction. Moreover, these methods did not fully exploit the bio-fidelity of SNNs, as they still require costly multiply-accumulate (MAC) operations, which severely harm the energy efficiency. To address the above issues and improve energy efficiency, in this paper, we propose an SNN-based deep generative method, namely the Spiking Variational Graph Auto-Encoders (S-VGAE) for efficient graph representation learning. To deal with the multi-node problem, we propose a probabilistic decoder that generates binary latent variables as spiking node representations and reconstructs graphs via the weighted inner product. To avoid the MAC operations for energy efficiency, we further decouple the propagation and transformation layers of conventional GNN aggregators. We conduct link prediction experiments on multiple benchmark graph datasets, and the results demonstrate that our model consumes significantly lower energy with the performances superior or comparable to other ANN- and SNN-based methods for graph representation learning.
AnANet: Modeling Association and Alignment for Cross-modal Correlation Classification
Sep 02, 2021
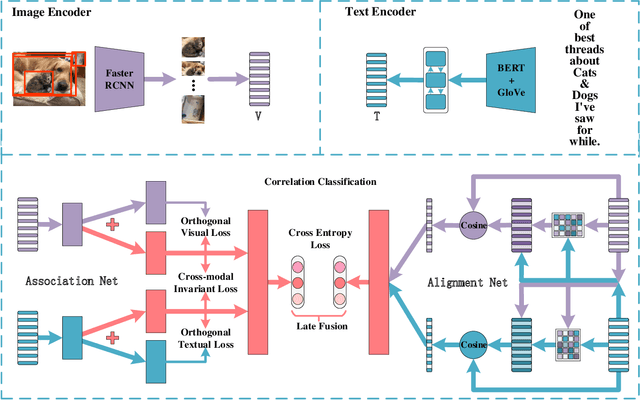

The explosive increase of multimodal data makes a great demand in many cross-modal applications that follow the strict prior related assumption. Thus researchers study the definition of cross-modal correlation category and construct various classification systems and predictive models. However, those systems pay more attention to the fine-grained relevant types of cross-modal correlation, ignoring lots of implicit relevant data which are often divided into irrelevant types. What's worse is that none of previous predictive models manifest the essence of cross-modal correlation according to their definition at the modeling stage. In this paper, we present a comprehensive analysis of the image-text correlation and redefine a new classification system based on implicit association and explicit alignment. To predict the type of image-text correlation, we propose the Association and Alignment Network according to our proposed definition (namely AnANet) which implicitly represents the global discrepancy and commonality between image and text and explicitly captures the cross-modal local relevance. The experimental results on our constructed new image-text correlation dataset show the effectiveness of our model.