 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPF: Aligning and Debiasing Language Models post Deployment via Multi Perspective Fusion
Jul 03, 2025Multiperspective Fusion (MPF) is a novel posttraining alignment framework for large language models (LLMs) developed in response to the growing need for easy bias mitigation. Built on top of the SAGED pipeline, an automated system for constructing bias benchmarks and extracting interpretable baseline distributions, MPF leverages multiperspective generations to expose and align biases in LLM outputs with nuanced, humanlike baselines. By decomposing baseline, such as sentiment distributions from HR professionals, into interpretable perspective components, MPF guides generation through sampling and balancing of responses, weighted by the probabilities obtained in the decomposition. Empirically, we demonstrate its ability to align LLM sentiment distributions with both counterfactual baselines (absolute equality) and the HR baseline (biased for Top Univeristy), resulting in small KL divergence, reduction of calibration error and generalization to unseen questions. This shows that MPF offers a scalable and interpretable method for alignment and bias mitigation, compatible with deployed LLMs and requiring no extensive prompt engineering or finetuning.
REFINED (REpresentation of Features as Images with NEighborhood Dependencies): A novel feature representation for Convolutional Neural Networks
Dec 11, 2019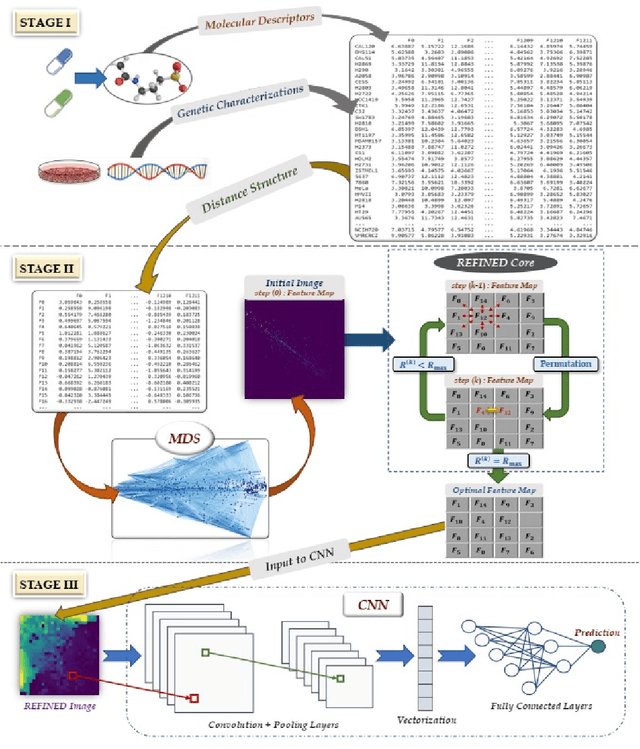
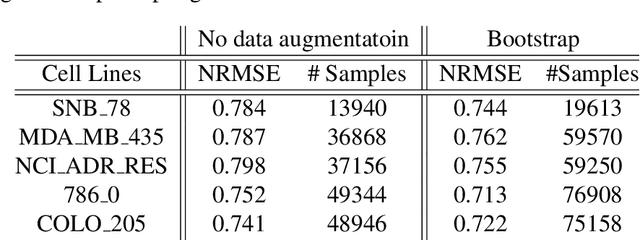
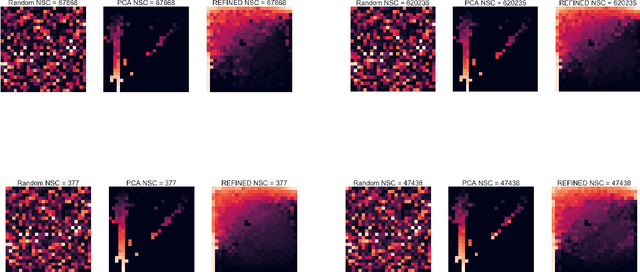

Deep learning with Convolutional Neural Networks has shown great promise in various areas of image-based classification and enhancement but is often unsuitable for predictive modeling involving non-image based features or features without spatial correlations. We present a novel approach for representation of high dimensional feature vector in a compact image form, termed REFINED (REpresentation of Features as Images with NEighborhood Dependencies), that is conducible for convolutional neural network based deep learning. We consider the correlations between features to generate a compact representation of the features in the form of a two-dimensional image using minimization of pairwise distances similar to multi-dimensional scaling. We hypothesize that this approach enables embedded feature selection and integrated with Convolutional Neural Network based Deep Learning can produce more accurate predictions as compared to Artificial Neural Networks, Random Forests and Support Vector Regression. We illustrate the superior predictive performance of the proposed representation, as compared to existing approaches, using synthetic datasets, cell line efficacy prediction based on drug chemical descriptors for NCI60 dataset and drug sensitivity prediction based on transcriptomic data and chemical descriptors using GDSC dataset. Results illustrated on both synthetic and biological datasets shows the higher prediction accuracy of the proposed framework as compared to existing methodologies while maintaining desirable properties in terms of bias and feature extraction.