 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-Driven Quantitative Spectroscopic Photoacoustic Imaging for Segmentation and Oxygen Saturation Estimation
Dec 17, 2025Spectroscopic photoacoustic (sPA) imaging can potentially estimate blood oxygenation saturation (sO2) in vivo noninvasively. However, quantitatively accurate results require accurate optical fluence estimates. Robust modeling in heterogeneous tissue, where light with different wavelengths can experience significantly different absorption and scattering, is difficult. In this work, we developed a deep neural network (Hybrid-Net) for sPA imaging to simultaneously estimate sO2 in blood vessels and segment those vessels from surrounding background tissue. sO2 error was minimized only in blood vessels segmented in Hybrid-Net, resulting in more accurate predictions. Hybrid-Net was first trained on simulated sPA data (at 700 nm and 850 nm) representing initial pressure distributions from three-dimensional Monte Carlo simulations of light transport in breast tissue. Then, for experimental verification, the network was retrained on experimental sPA data (at 700 nm and 850 nm) acquired from simple tissue mimicking phantoms with an embedded blood pool. Quantitative measures were used to evaluate Hybrid-Net performance with an averaged segmentation accuracy of >= 0.978 in simulations with varying noise levels (0dB-35dB) and 0.998 in the experiment, and an averaged sO2 mean squared error of <= 0.048 in simulations with varying noise levels (0dB-35dB) and 0.003 in the experiment. Overall, these results show that Hybrid-Net can provide accurate blood oxygenation without estimating the optical fluence, and this study could lead to improvements in in-vivo sO2 estimation.
Combined fluorescence and photoacoustic imaging of tozuleristide in muscle tissue in vitro -- toward optically-guided solid tumor surgery: feasibility studies
Oct 31, 2025Near-infrared fluorescence (NIRF) can deliver high-contrast, video-rate, non-contact imaging of tumor-targeted contrast agents with the potential to guide surgeries excising solid tumors. However, it has been met with skepticism for wide-margin excision due to sensitivity and resolution limitations at depths larger than ~5 mm in tissue. To address this limitation, fast-sweep photoacoustic-ultrasound (PAUS) imaging is proposed to complement NIRF. In an exploratory in vitro feasibility study using dark-red bovine muscle tissue, we observed that PAUS scanning can identify tozuleristide, a clinical stage investigational imaging agent, at a concentration of 20 uM from the background at depths of up to ~34 mm, highly extending the capabilities of NIRF alone. The capability of spectroscopic PAUS imaging was tested by direct injection of 20 uM tozuleristide into bovine muscle tissue at a depth of ~ 8 mm. It is shown that laser-fluence compensation and strong clutter suppression enabled by the unique capabilities of the fast-sweep approach greatly improve spectroscopic accuracy and the PA detection limit, and strongly reduce image artifacts. Thus, the combined NIRF-PAUS approach can be promising for comprehensive pre- (with PA) and intra- (with NIRF) operative solid tumor detection and wide-margin excision in optically guided solid tumor surgery.
Joint Segmentation and Image Reconstruction with Error Prediction in Photoacoustic Imaging using Deep Learning
Jul 02, 2024Deep learning has been used to improve photoacoustic (PA) image reconstruction. One major challenge is that errors cannot be quantified to validate predictions when ground truth is unknown. Validation is key to quantitative applications, especially using limited-bandwidth ultrasonic linear detector arrays. Here, we propose a hybrid Bayesian convolutional neural network (Hybrid-BCNN) to jointly predict PA image and segmentation with error (uncertainty) predictions. Each output pixel represents a probability distribution where error can be quantified. The Hybrid-BCNN was trained with simulated PA data and applied to both simulations and experiments. Due to the sparsity of PA images, segmentation focuses Hybrid-BCNN on minimizing the loss function in regions with PA signals for better predictions. The results show that accurate PA segmentations and images are obtained, and error predictions are highly statistically correlated to actual errors. To leverage error predictions, confidence processing created PA images above a specific confidence level.
Deep-learning-driven Reliable Single-pixel Imaging with Uncertainty Approximation
Jul 24, 2021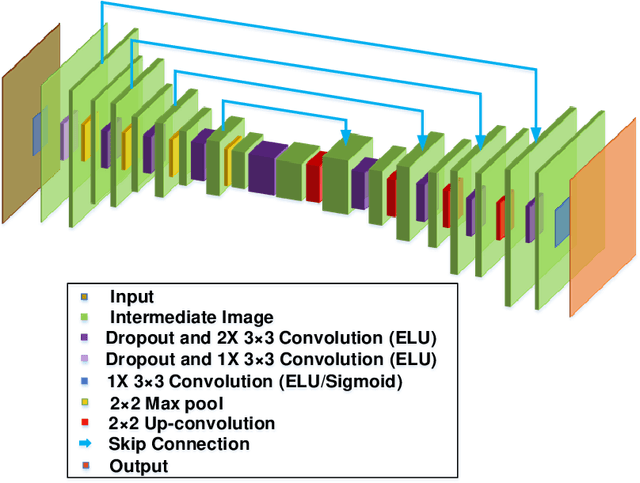
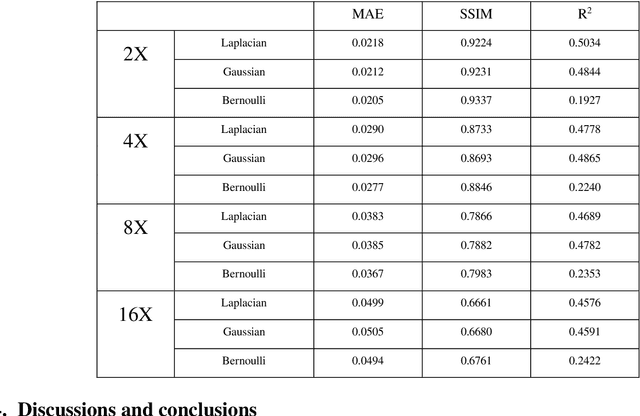
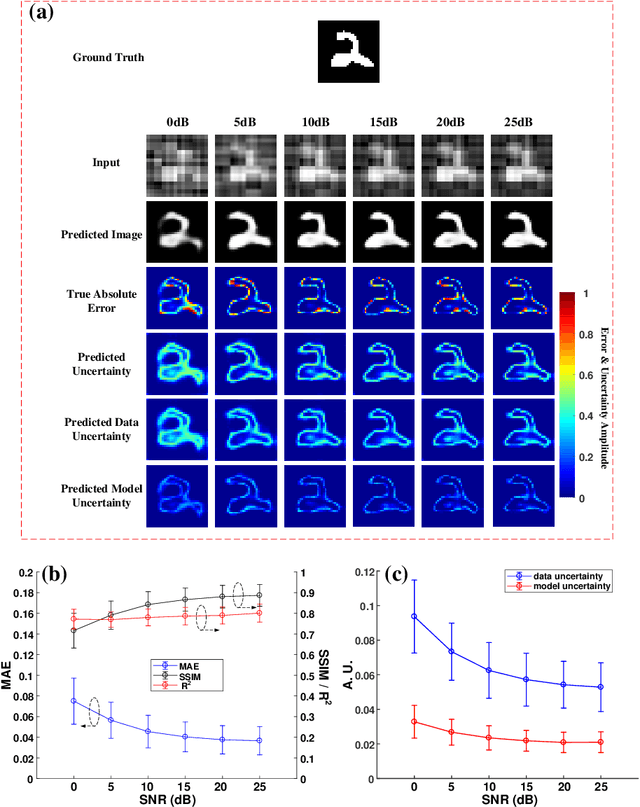
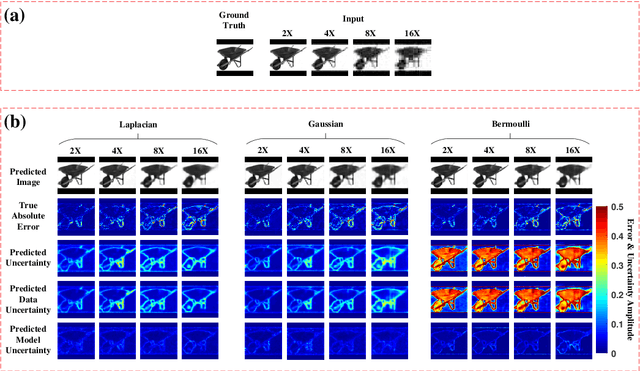
Single-pixel imaging (SPI) has the advantages of high-speed acquisition over a broad wavelength range and system compactness, which are difficult to achieve by conventional imaging sensors. However, a common challenge is low image quality arising from undersampling. Deep learning (DL) is an emerging and powerful tool in computational imaging for many applications and researchers have applied DL in SPI to achieve higher image quality than conventional reconstruction approaches. One outstanding challenge, however, is that the accuracy of DL predictions in SPI cannot be assessed in practical applications where the ground truths are unknown. Here, we propose the use of the Bayesian convolutional neural network (BCNN) to approximate the uncertainty (coming from finite training data and network model) of the DL predictions in SPI. Each pixel in the predicted result from BCNN represents the parameter of a probability distribution rather than the image intensity value. Then, the uncertainty can be approximated with BCNN by minimizing a negative log-likelihood loss function in the training stage and Monte Carlo dropout in the prediction stage. The results show that the BCNN can reliably approximate the uncertainty of the DL predictions in SPI with varying compression ratios and noise levels. The predicted uncertainty from BCNN in SPI reveals that most of the reconstruction errors in deep-learning-based SPI come from the edges of the image features. The results show that the proposed BCNN can provide a reliable tool to approximate the uncertainty of DL predictions in SPI and can be widely used in many applications of SPI.
A Two-step-training Deep Learning Framework for Real-time Computational Imaging without Physics Priors
Jan 10, 2020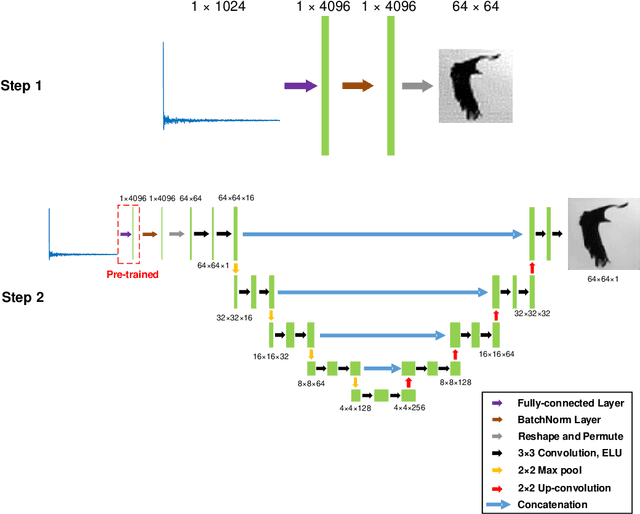
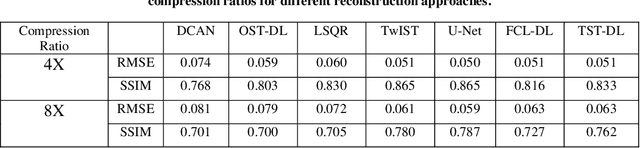

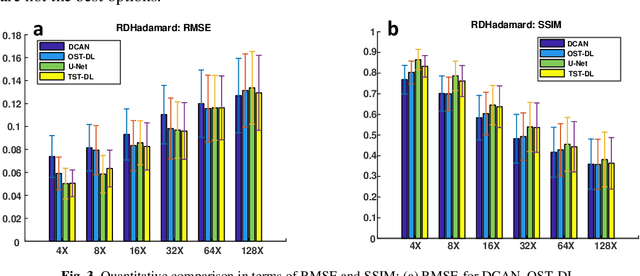
Deep learning (DL) is a powerful tool in computational imaging for many applications. A common strategy is to reconstruct a preliminary image as the input of a neural network to achieve an optimized image. Usually, the preliminary image is acquired with the prior knowledge of the model. One outstanding challenge, however, is that the model is sometimes difficult to acquire with high accuracy. In this work, a two-step-training DL (TST-DL) framework is proposed for real-time computational imaging without prior knowledge of the model. A single fully-connected layer (FCL) is trained to directly learn the model with the raw measurement data as input and the image as output. Then, this pre-trained FCL is fixed and connected with an un-trained deep convolutional network for a second-step training to improve the output image fidelity. This approach has three main advantages. First, no prior knowledge of the model is required since the first-step training is to directly learn the model. Second, real-time imaging can be achieved since the raw measurement data is directly used as the input to the model. Third, it can handle any dimension of the network input and solve the input-output dimension mismatch issues which arise in convolutional neural networks. We demonstrate this framework in the applications of single-pixel imaging and photoacoustic imaging for linear model cases. The results are quantitatively compared with those from other DL frameworks and model-based optimization approaches. Noise robustness and the required size of the training dataset are studied for this framework. We further extend this concept to nonlinear models in the application of image de-autocorrelation by using multiple FCLs in the first-step training. Overall, this TST-DL framework is widely applicable to many computational imaging techniques for real-time image reconstruction without the physics priors.