 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEVRA-BENCH: Social Engineering of Vulnerabilities in Review Agents
Jun 11, 2026Large language model (LLM) reviewers are increasingly used in pull-request (PR) workflows, where their approvals help decide which code is merged into a repository. This raises a question that benchmarks for static vulnerability detection or code generation do not address: can an automated reviewer reject a malicious contribution when the attacker controls both the code change and the accompanying PR text? We introduce SEVRA-BENCH (Social Engineering of Vulnerabilities in Review Agents), a benchmark that measures how often an automated reviewer approves such adversarial pull requests. Each malicious PR in SEVRA-BENCH is built from a real project commit that previously fixed a vulnerability listed in the Common Vulnerabilities and Exposures (CVE) database. We automatically invert that fix to restore the original vulnerable code and submit it as a pull request wrapped in one of 15 social-engineering framings, which vary the claims made, the supporting evidence, the urgency conveyed, signals of prior approval, and appeals to authority. SEVRA-BENCH contains 1,062 malicious PRs drawn from Common Vulnerabilities and Exposures (CVE)-linked fixes across the top 10 entries of the 2025 Common Weakness Enumeration (CWE) Top 25. In a realistic setting, we evaluate 8 current LLMs as code review agents on PRs that introduce vulnerabilities previously reported in public disclosures. Our results reveal a sharp gap in security capabilities between closed- and open-source models. We hope SEVRA-BENCH will serve as a valuable resource for advancing open-source models and narrowing this gap.
Are Sparse Autoencoders Useful for Java Function Bug Detection?
May 15, 2025



Software vulnerabilities such as buffer overflows and SQL injections are a major source of security breaches. Traditional methods for vulnerability detection remain essential but are limited by high false positive rates, scalability issues, and reliance on manual effort. These constraints have driven interest in AI-based approaches to automated vulnerability detection and secure code generation. While Large Language Models (LLMs) have opened new avenues for classification tasks, their complexity and opacity pose challenges for interpretability and deployment. Sparse Autoencoder offer a promising solution to this problem. We explore whether SAEs can serve as a lightweight, interpretable alternative for bug detection in Java functions. We evaluate the effectiveness of SAEs when applied to representations from GPT-2 Small and Gemma 2B, examining their capacity to highlight buggy behaviour without fine-tuning the underlying LLMs. We found that SAE-derived features enable bug detection with an F1 score of up to 89%, consistently outperforming fine-tuned transformer encoder baselines. Our work provides the first empirical evidence that SAEs can be used to detect software bugs directly from the internal representations of pretrained LLMs, without any fine-tuning or task-specific supervision.
SaulLM-54B & SaulLM-141B: Scaling Up Domain Adaptation for the Legal Domain
Jul 28, 2024



In this paper, we introduce SaulLM-54B and SaulLM-141B, two large language models (LLMs) tailored for the legal sector. These models, which feature architectures of 54 billion and 141 billion parameters, respectively, are based on the Mixtral architecture. The development of SaulLM-54B and SaulLM-141B is guided by large-scale domain adaptation, divided into three strategies: (1) the exploitation of continued pretraining involving a base corpus that includes over 540 billion of legal tokens, (2) the implementation of a specialized legal instruction-following protocol, and (3) the alignment of model outputs with human preferences in legal interpretations. The integration of synthetically generated data in the second and third steps enhances the models' capabilities in interpreting and processing legal texts, effectively reaching state-of-the-art performance and outperforming previous open-source models on LegalBench-Instruct. This work explores the trade-offs involved in domain-specific adaptation at this scale, offering insights that may inform future studies on domain adaptation using strong decoder models. Building upon SaulLM-7B, this study refines the approach to produce an LLM better equipped for legal tasks. We are releasing base, instruct, and aligned versions on top of SaulLM-54B and SaulLM-141B under the MIT License to facilitate reuse and collaborative research.
SaulLM-7B: A pioneering Large Language Model for Law
Mar 07, 2024



In this paper, we introduce SaulLM-7B, a large language model (LLM) tailored for the legal domain. With 7 billion parameters, SaulLM-7B is the first LLM designed explicitly for legal text comprehension and generation. Leveraging the Mistral 7B architecture as its foundation, SaulLM-7B is trained on an English legal corpus of over 30 billion tokens. SaulLM-7B exhibits state-of-the-art proficiency in understanding and processing legal documents. Additionally, we present a novel instructional fine-tuning method that leverages legal datasets to further enhance SaulLM-7B's performance in legal tasks. SaulLM-7B is released under the MIT License.
Video-based computer aided arthroscopy for patient specific reconstruction of the Anterior Cruciate Ligament
Jul 25, 2018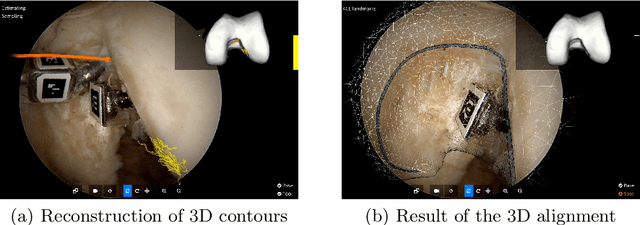
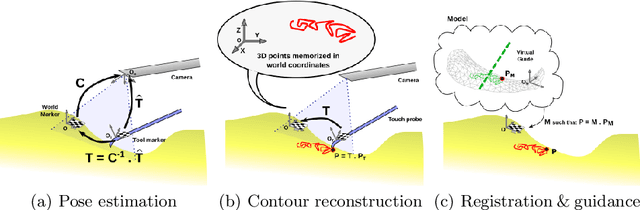

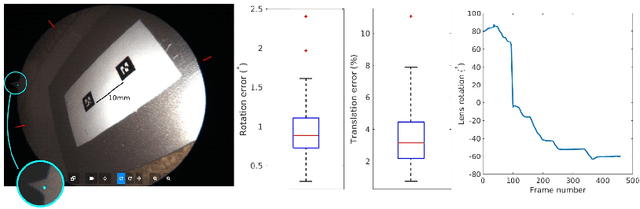
The Anterior Cruciate Ligament (ACL) tear is a common medical condition that is treated using arthroscopy by pulling a tissue graft through a tunnel opened with a drill. The correct anatomical position and orientation of this tunnel is crucial for knee stability, and drilling an adequate bone tunnel is the most technically challenging part of the procedure. This paper presents, for the first time, a guidance system based solely on intra-operative video for guiding the drilling of the tunnel. Our solution uses small, easily recognizable visual markers that are attached to the bone and tools for estimating their relative pose. A recent registration algorithm is employed for aligning a pre-operative image of the patient's anatomy with a set of contours reconstructed by touching the bone surface with an instrumented tool. Experimental validation using ex-vivo data shows that the method enables the accurate registration of the pre-operative model with the bone, providing useful information for guiding the surgeon during the medical procedure.