 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-Driven Proactive Assistive Manipulation with Grounded Vision-Language Planning
Mar 25, 2026Assistance in collaborative manipulation is often initiated by user instructions, making high-level reasoning request-driven. In fluent human teamwork, however, partners often infer the next helpful step from the observed outcome of an action rather than waiting for instructions. Motivated by this, we introduce a shift from request-driven assistance to event-driven proactive assistance, where robot actions are initiated by workspace state transitions induced by human--object interactions rather than user-provided task instructions. To this end, we propose an event-driven framework that tracks interaction progress with an event monitor and, upon event completion, extracts stabilized pre/post snapshots that characterize the resulting state transition. Given the stabilized snapshots, the planner analyzes the implied state transition to infer a task-level goal and decide whether to intervene; if so, it generates a sequence of assistive actions. To make outputs executable and verifiable, we restrict actions to a set of action primitives and reference objects via integer IDs. We evaluate the framework on a real tabletop number-block collaboration task, demonstrating that explicit pre/post state-change evidence improves proactive completion on solvable scenes and appropriate waiting on unsolvable ones.
An improved helmet detection method for YOLOv3 on an unbalanced dataset
Nov 09, 2020
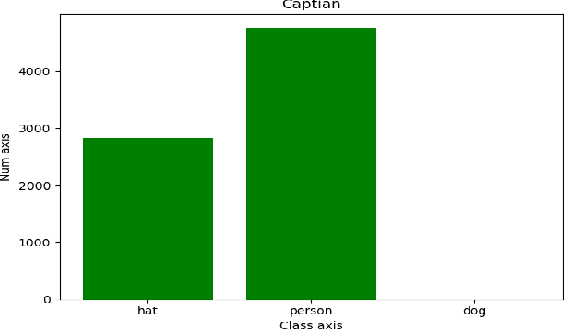
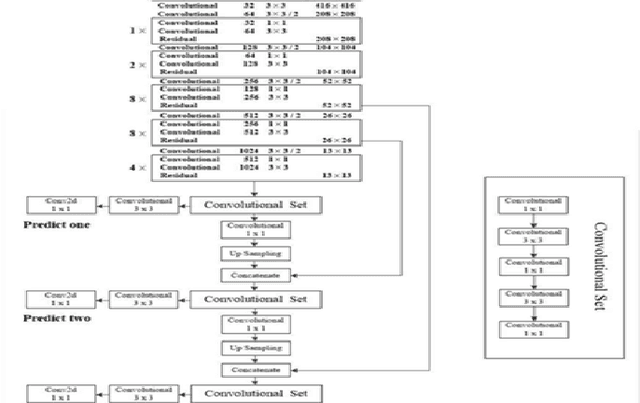

The YOLOv3 target detection algorithm is widely used in industry due to its high speed and high accuracy, but it has some limitations, such as the accuracy degradation of unbalanced datasets. The YOLOv3 target detection algorithm is based on a Gaussian fuzzy data augmentation approach to pre-process the data set and improve the YOLOv3 target detection algorithm. Through the efficient pre-processing, the confidence level of YOLOv3 is generally improved by 0.01-0.02 without changing the recognition speed of YOLOv3, and the processed images also perform better in image localization due to effective feature fusion, which is more in line with the requirement of recognition speed and accuracy in production.
Approaches of large-scale images recognition with more than 50,000 categoris
Jul 26, 2020

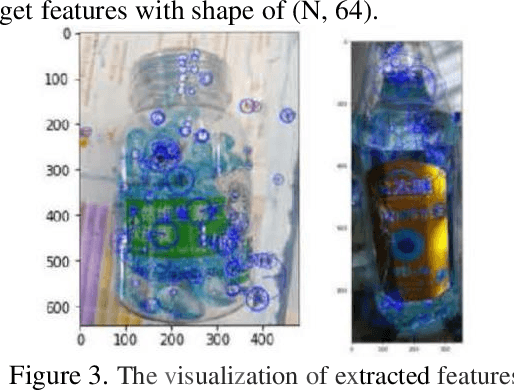
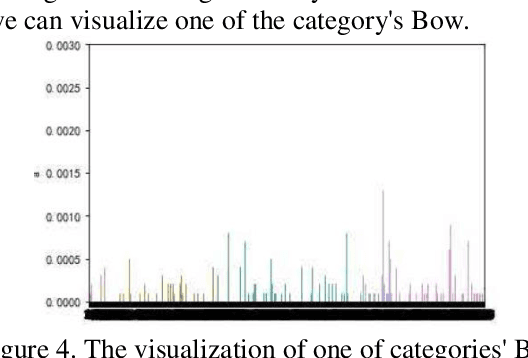
Though current CV models have been able to achieve high levels of accuracy on small-scale images classification dataset with hundreds or thousands of categories, many models become infeasible in computational or space consumption when it comes to large-scale dataset with more than 50,000 categories. In this paper, we provide a viable solution for classifying large-scale species datasets using traditional CV techniques such as.features extraction and processing, BOVW(Bag of Visual Words) and some statistical learning technics like Mini-Batch K-Means,SVM which are used in our works. And then mixed with a neural network model. When applying these techniques, we have done some optimization in time and memory consumption, so that it can be feasible for large-scale dataset. And we also use some technics to reduce the impact of mislabeling data. We use a dataset with more than 50, 000 categories, and all operations are done on common computer with l 6GB RAM and a CPU of 3. OGHz. Our contributions are: 1) analysis what problems may meet in the training processes, and presents several feasible ways to solve these problems. 2) Make traditional CV models combined with neural network models provide some feasible scenarios for training large-scale classified datasets within the constraints of time and spatial resources.