 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attempt to Devise a Pairwise Ising-Type Maximum Entropy Model Integrated Cost Function for Optimizing SNN Deployment
Jul 11, 2024The deployment process of a spiking neural network (SNN) often involves partitioning the neural network and mapping these partitions onto processing units within the neuromorphic hardware. Finding optimal deployment schemes is an NP-hard problem. Optimizing these schemes presents challenges, particular in devising computationally effective cost functions optimization objectives such as communication time consumption and energy efficiency. These objectives require consideration of network dynamics shaped by neuron activity patterns, demanding intricate mathematical analyses or simulations for integrating them into a cost model for SNN development. Our approach focuses on network dynamics, which are hardware-independent and can be modeled separately from specific hardware configurations. We employ a pairwise Ising-type maximum entropy model, which is a model show effective in accurately capturing pairwise correlations among system components in a collaborative system. On top of this model, we incorporates hardware and network structure-specific factors to devise a cost function. We conducted an extremely preliminary investigation using the SpiNNaker machine. We show that the ising model training can also be computationally complex. Currently, we lack sufficient evidence to substantiate the effectiveness of our proposed methods. Further efforts is needed to explore integrating network dynamics into SNN deployment.
An improved helmet detection method for YOLOv3 on an unbalanced dataset
Nov 09, 2020
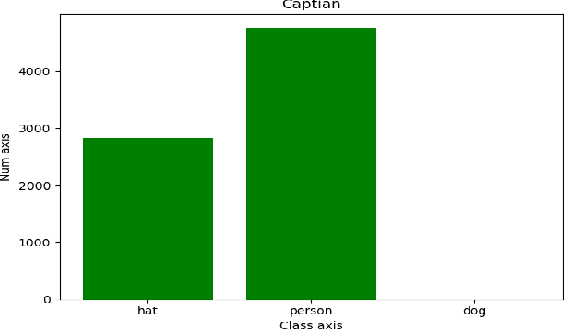
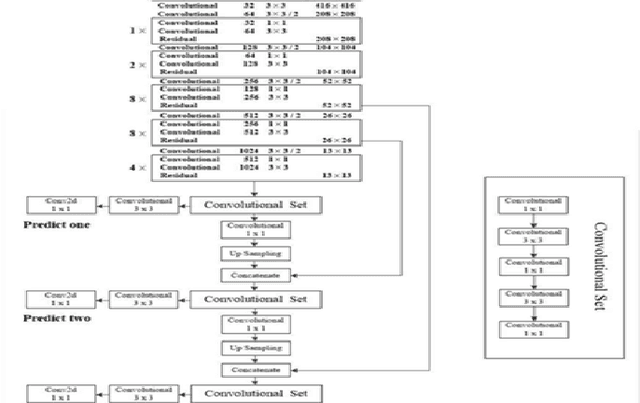

The YOLOv3 target detection algorithm is widely used in industry due to its high speed and high accuracy, but it has some limitations, such as the accuracy degradation of unbalanced datasets. The YOLOv3 target detection algorithm is based on a Gaussian fuzzy data augmentation approach to pre-process the data set and improve the YOLOv3 target detection algorithm. Through the efficient pre-processing, the confidence level of YOLOv3 is generally improved by 0.01-0.02 without changing the recognition speed of YOLOv3, and the processed images also perform better in image localization due to effective feature fusion, which is more in line with the requirement of recognition speed and accuracy in production.
Machine learning approach of Japanese composition scoring and writing aided system's design
Aug 26, 2020
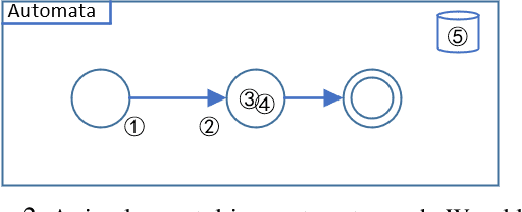
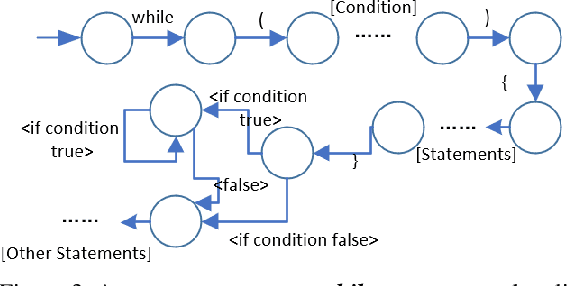
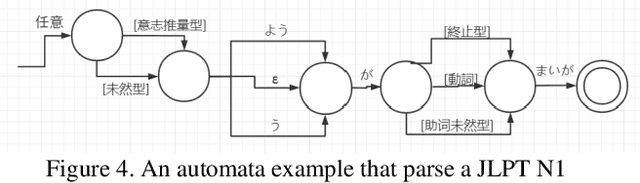
Automatic scoring system is extremely complex for any language. Because natural language itself is a complex model. When we evaluate articles generated by natural language, we need to view the articles from many dimensions such as word features, grammatical features, semantic features, text structure and so on. Even human beings sometimes can't accurately grade a composition because different people have different opinions about the same article. But a composition scoring system can greatly assist language learners. It can make language leaner improve themselves in the process of output something. Though it is still difficult for machines to directly evaluate a composition at the semantic and pragmatic levels, especially for Japanese, Chinese and other language in high context cultures, we can make machine evaluate a passage in word and grammar levels, which can as an assistance of composition rater or language learner. Especially for foreign language learners, lexical and syntactic content are usually what they are more concerned about. In our experiments, we did the follows works: 1) We use word segmentation tools and dictionaries to achieve word segmentation of an article, and extract word features, as well as generate a words' complexity feature of an article. And Bow technique are used to extract the theme features. 2) We designed a Turing-complete automata model and create 300+ automatons for the grammars that appear in the JLPT examination. And extract grammars features by using these automatons. 3) We propose a statistical approach for scoring a specify theme of composition, the final score will depend on all the writings that submitted to the system. 4) We design an grammar hint function for language leaner, so that they can know currently what grammars they can use.
Approaches of large-scale images recognition with more than 50,000 categoris
Jul 26, 2020

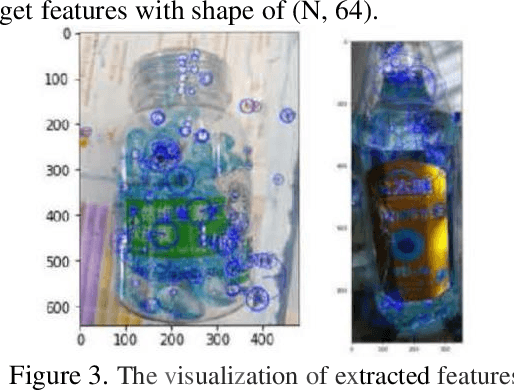
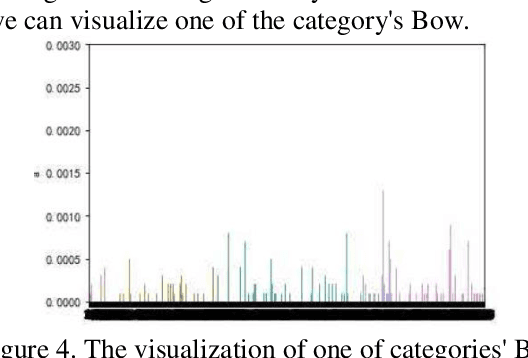
Though current CV models have been able to achieve high levels of accuracy on small-scale images classification dataset with hundreds or thousands of categories, many models become infeasible in computational or space consumption when it comes to large-scale dataset with more than 50,000 categories. In this paper, we provide a viable solution for classifying large-scale species datasets using traditional CV techniques such as.features extraction and processing, BOVW(Bag of Visual Words) and some statistical learning technics like Mini-Batch K-Means,SVM which are used in our works. And then mixed with a neural network model. When applying these techniques, we have done some optimization in time and memory consumption, so that it can be feasible for large-scale dataset. And we also use some technics to reduce the impact of mislabeling data. We use a dataset with more than 50, 000 categories, and all operations are done on common computer with l 6GB RAM and a CPU of 3. OGHz. Our contributions are: 1) analysis what problems may meet in the training processes, and presents several feasible ways to solve these problems. 2) Make traditional CV models combined with neural network models provide some feasible scenarios for training large-scale classified datasets within the constraints of time and spatial resources.
Spine Landmark Localization with combining of Heatmap Regression and Direct Coordinate Regression
Jul 10, 2020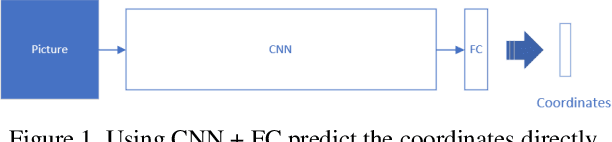
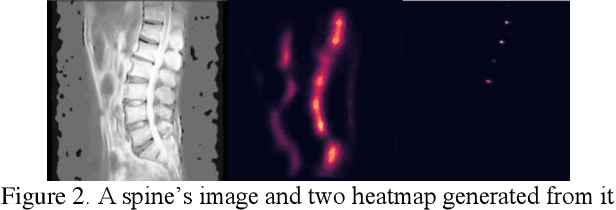
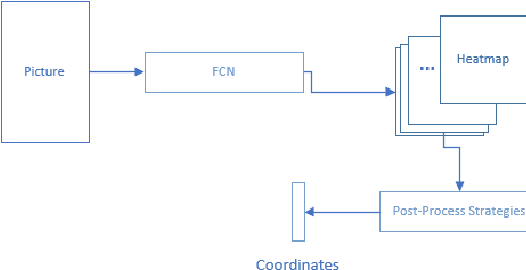
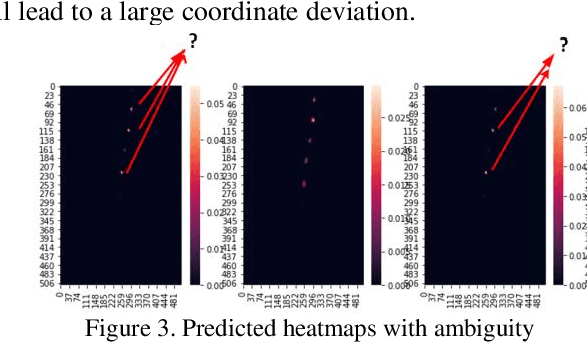
Landmark Localization plays a very important role in processing medical images as well as in disease identification. However, In medical field, it's a challenging task because of the complexity of medical images and the high requirement of accuracy for disease identification and treatment.There are two dominant ways to regress landmark coordination, one using the full convolutional network to regress the heatmaps of landmarks , which is a complex way and heatmap post-process strategies are needed, and the other way is to regress the coordination using CNN + Full Connective Network directly, which is very simple and faster training , but larger dataset and deeper model are needed to achieve higher accuracy. Though with data augmentation and deeper network it can reach a reasonable accuracy, but the accuracy still not reach the requirement of medical field. In addition, a deeper networks also means larger space consumption. To achieve a higher accuracy, we contrived a new landmark regression method which combing heatmap regression and direct coordinate regression base on probability methods and system control theory.