 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinoGAViL: Gamified Association Benchmark to Challenge Vision-and-Language Models
Jul 25, 2022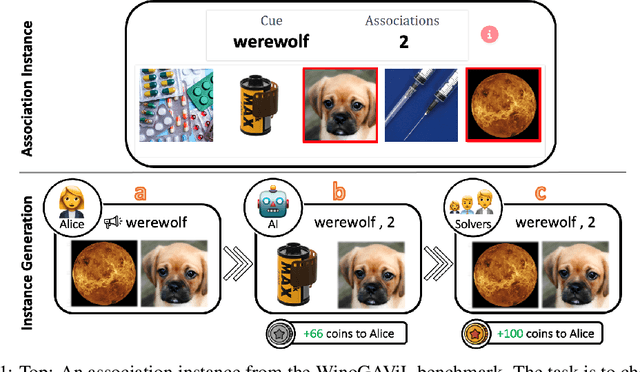
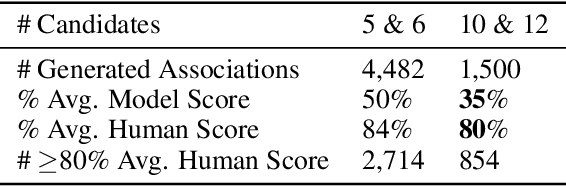

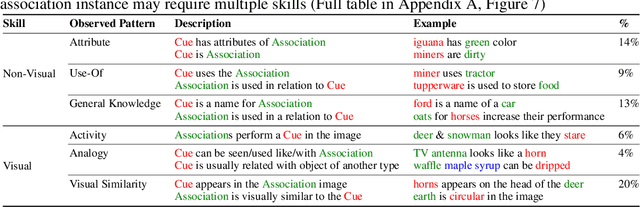
While vision-and-language models perform well on tasks such as visual question answering, they struggle when it comes to basic human commonsense reasoning skills. In this work, we introduce WinoGAViL: an online game to collect vision-and-language associations, (e.g., werewolves to a full moon), used as a dynamic benchmark to evaluate state-of-the-art models. Inspired by the popular card game Codenames, a spymaster gives a textual cue related to several visual candidates, and another player has to identify them. Human players are rewarded for creating associations that are challenging for a rival AI model but still solvable by other human players. We use the game to collect 3.5K instances, finding that they are intuitive for humans (>90% Jaccard index) but challenging for state-of-the-art AI models, where the best model (ViLT) achieves a score of 52%, succeeding mostly where the cue is visually salient. Our analysis as well as the feedback we collect from players indicate that the collected associations require diverse reasoning skills, including general knowledge, common sense, abstraction, and more. We release the dataset, the code and the interactive game, aiming to allow future data collection that can be used to develop models with better association abilities.
Fewer Errors, but More Stereotypes? The Effect of Model Size on Gender Bias
Jun 20, 2022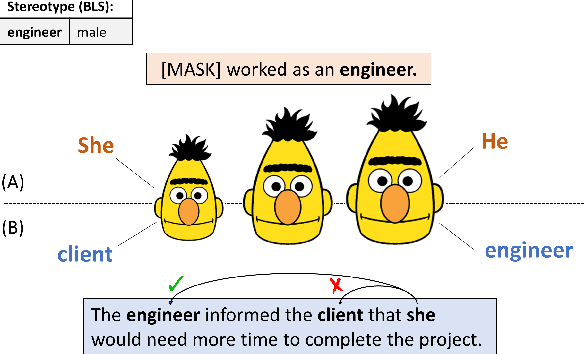

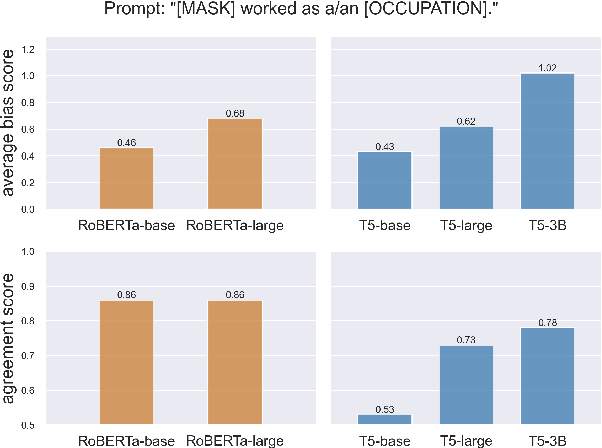
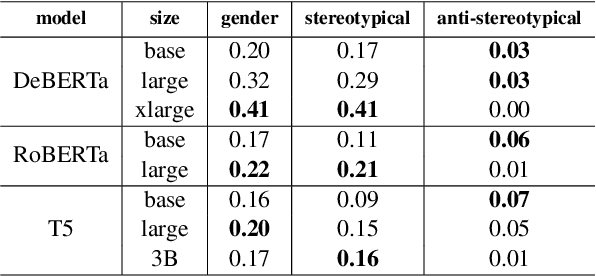
The size of pretrained models is increasing, and so is their performance on a variety of NLP tasks. However, as their memorization capacity grows, they might pick up more social biases. In this work, we examine the connection between model size and its gender bias (specifically, occupational gender bias). We measure bias in three masked language model families (RoBERTa, DeBERTa, and T5) in two setups: directly using prompt based method, and using a downstream task (Winogender). We find on the one hand that larger models receive higher bias scores on the former task, but when evaluated on the latter, they make fewer gender errors. To examine these potentially conflicting results, we carefully investigate the behavior of the different models on Winogender. We find that while larger models outperform smaller ones, the probability that their mistakes are caused by gender bias is higher. Moreover, we find that the proportion of stereotypical errors compared to anti-stereotypical ones grows with the model size. Our findings highlight the potential risks that can arise from increasing model size.
Measuring the Carbon Intensity of AI in Cloud Instances
Jun 10, 2022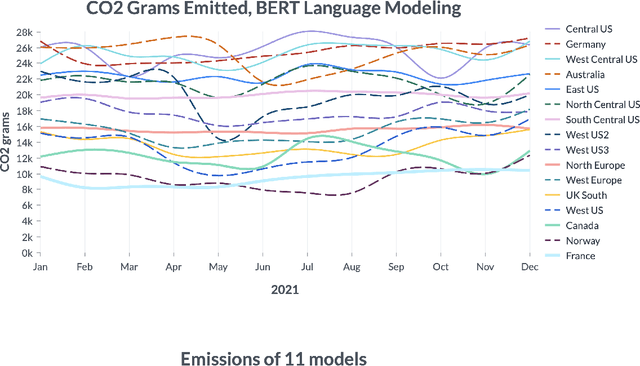

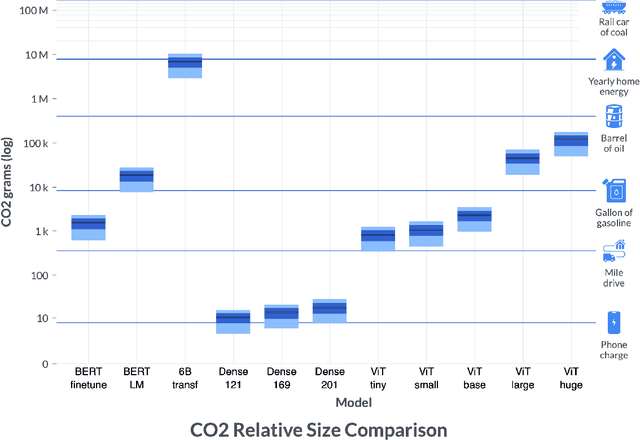

By providing unprecedented access to computational resources, cloud computing has enabled rapid growth in technologies such as machine learning, the computational demands of which incur a high energy cost and a commensurate carbon footprint. As a result, recent scholarship has called for better estimates of the greenhouse gas impact of AI: data scientists today do not have easy or reliable access to measurements of this information, precluding development of actionable tactics. Cloud providers presenting information about software carbon intensity to users is a fundamental stepping stone towards minimizing emissions. In this paper, we provide a framework for measuring software carbon intensity, and propose to measure operational carbon emissions by using location-based and time-specific marginal emissions data per energy unit. We provide measurements of operational software carbon intensity for a set of modern models for natural language processing and computer vision, and a wide range of model sizes, including pretraining of a 6.1 billion parameter language model. We then evaluate a suite of approaches for reducing emissions on the Microsoft Azure cloud compute platform: using cloud instances in different geographic regions, using cloud instances at different times of day, and dynamically pausing cloud instances when the marginal carbon intensity is above a certain threshold. We confirm previous results that the geographic region of the data center plays a significant role in the carbon intensity for a given cloud instance, and find that choosing an appropriate region can have the largest operational emissions reduction impact. We also show that the time of day has notable impact on operational software carbon intensity. Finally, we conclude with recommendations for how machine learning practitioners can use software carbon intensity information to reduce environmental impact.
On the Limitations of Dataset Balancing: The Lost Battle Against Spurious Correlations
Apr 27, 2022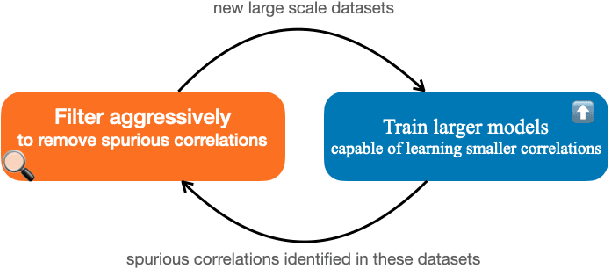


Recent work has shown that deep learning models in NLP are highly sensitive to low-level correlations between simple features and specific output labels, leading to overfitting and lack of generalization. To mitigate this problem, a common practice is to balance datasets by adding new instances or by filtering out "easy" instances (Sakaguchi et al., 2020), culminating in a recent proposal to eliminate single-word correlations altogether (Gardner et al., 2021). In this opinion paper, we identify that despite these efforts, increasingly-powerful models keep exploiting ever-smaller spurious correlations, and as a result even balancing all single-word features is insufficient for mitigating all of these correlations. In parallel, a truly balanced dataset may be bound to "throw the baby out with the bathwater" and miss important signal encoding common sense and world knowledge. We highlight several alternatives to dataset balancing, focusing on enhancing datasets with richer contexts, allowing models to abstain and interact with users, and turning from large-scale fine-tuning to zero- or few-shot setups.
TangoBERT: Reducing Inference Cost by using Cascaded Architecture
Apr 13, 2022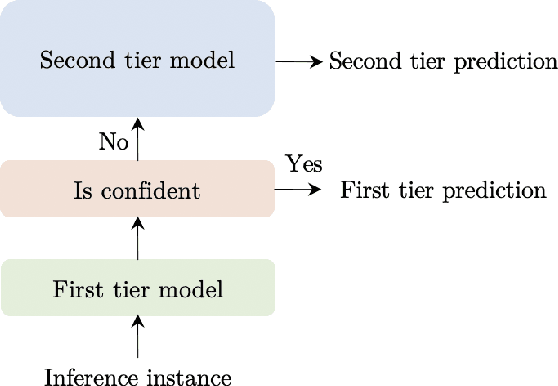

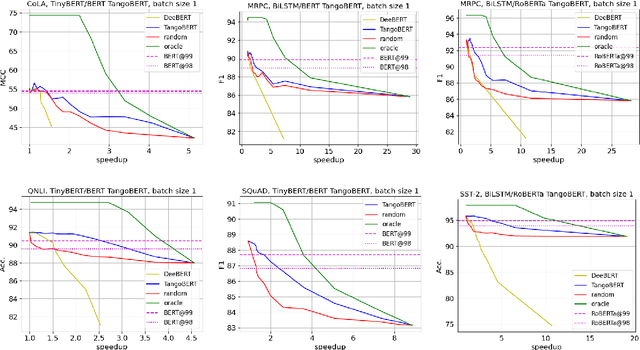
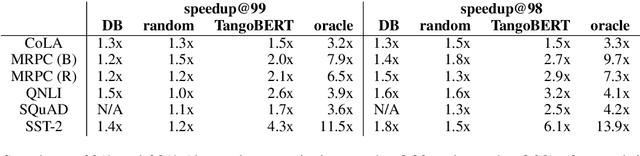
The remarkable success of large transformer-based models such as BERT, RoBERTa and XLNet in many NLP tasks comes with a large increase in monetary and environmental cost due to their high computational load and energy consumption. In order to reduce this computational load in inference time, we present TangoBERT, a cascaded model architecture in which instances are first processed by an efficient but less accurate first tier model, and only part of those instances are additionally processed by a less efficient but more accurate second tier model. The decision of whether to apply the second tier model is based on a confidence score produced by the first tier model. Our simple method has several appealing practical advantages compared to standard cascading approaches based on multi-layered transformer models. First, it enables higher speedup gains (average lower latency). Second, it takes advantage of batch size optimization for cascading, which increases the relative inference cost reductions. We report TangoBERT inference CPU speedup on four text classification GLUE tasks and on one reading comprehension task. Experimental results show that TangoBERT outperforms efficient early exit baseline models; on the the SST-2 task, it achieves an accuracy of 93.9% with a CPU speedup of 8.2x.
A deep learning framework for the detection and quantification of drusen and reticular pseudodrusen on optical coherence tomography
Apr 05, 2022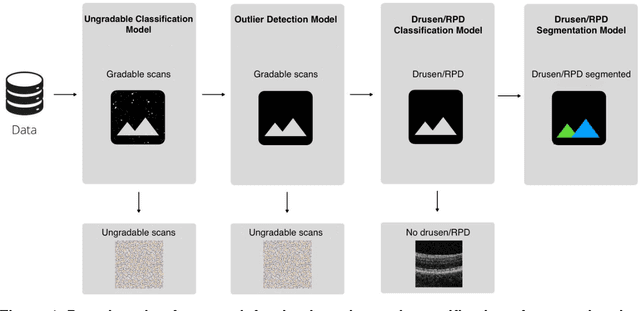
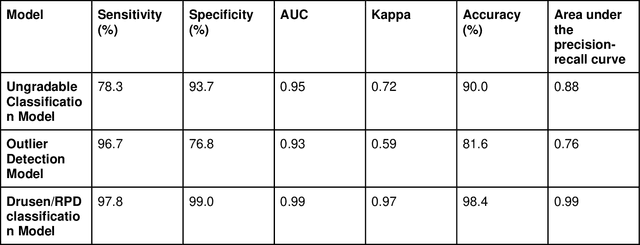
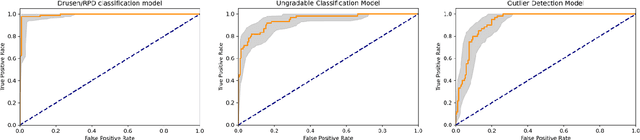

Purpose - To develop and validate a deep learning (DL) framework for the detection and quantification of drusen and reticular pseudodrusen (RPD) on optical coherence tomography scans. Design - Development and validation of deep learning models for classification and feature segmentation. Methods - A DL framework was developed consisting of a classification model and an out-of-distribution (OOD) detection model for the identification of ungradable scans; a classification model to identify scans with drusen or RPD; and an image segmentation model to independently segment lesions as RPD or drusen. Data were obtained from 1284 participants in the UK Biobank (UKBB) with a self-reported diagnosis of age-related macular degeneration (AMD) and 250 UKBB controls. Drusen and RPD were manually delineated by five retina specialists. The main outcome measures were sensitivity, specificity, area under the ROC curve (AUC), kappa, accuracy and intraclass correlation coefficient (ICC). Results - The classification models performed strongly at their respective tasks (0.95, 0.93, and 0.99 AUC, respectively, for the ungradable scans classifier, the OOD model, and the drusen and RPD classification model). The mean ICC for drusen and RPD area vs. graders was 0.74 and 0.61, respectively, compared with 0.69 and 0.68 for intergrader agreement. FROC curves showed that the model's sensitivity was close to human performance. Conclusions - The models achieved high classification and segmentation performance, similar to human performance. Application of this robust framework will further our understanding of RPD as a separate entity from drusen in both research and clinical settings.
Data Contamination: From Memorization to Exploitation
Mar 15, 2022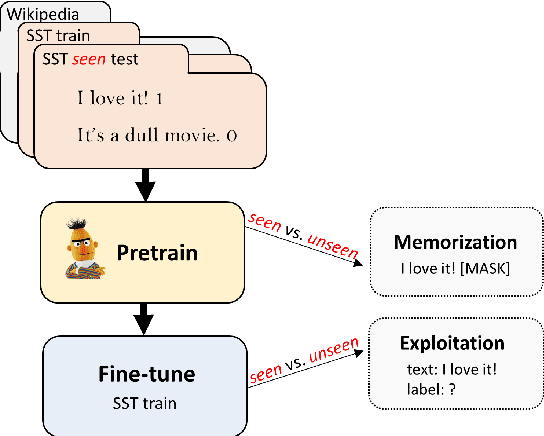
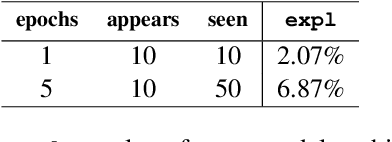
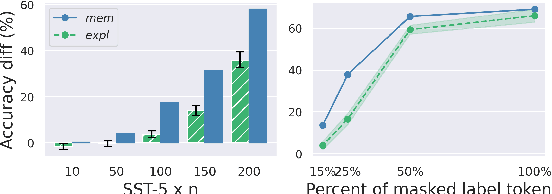

Pretrained language models are typically trained on massive web-based datasets, which are often "contaminated" with downstream test sets. It is not clear to what extent models exploit the contaminated data for downstream tasks. We present a principled method to study this question. We pretrain BERT models on joint corpora of Wikipedia and labeled downstream datasets, and fine-tune them on the relevant task. Comparing performance between samples seen and unseen during pretraining enables us to define and quantify levels of memorization and exploitation. Experiments with two models and three downstream tasks show that exploitation exists in some cases, but in others the models memorize the contaminated data, but do not exploit it. We show that these two measures are affected by different factors such as the number of duplications of the contaminated data and the model size. Our results highlight the importance of analyzing massive web-scale datasets to verify that progress in NLP is obtained by better language understanding and not better data exploitation.
ABC: Attention with Bounded-memory Control
Oct 06, 2021
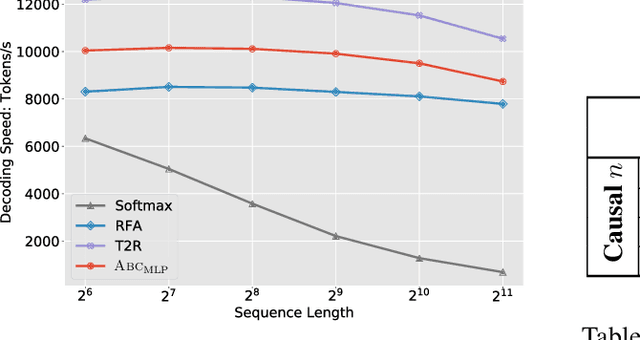
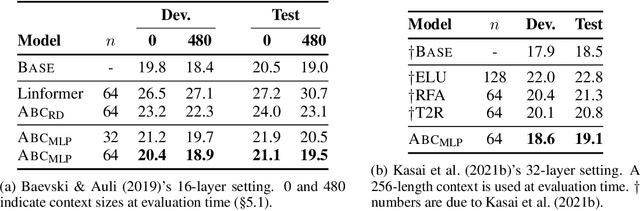
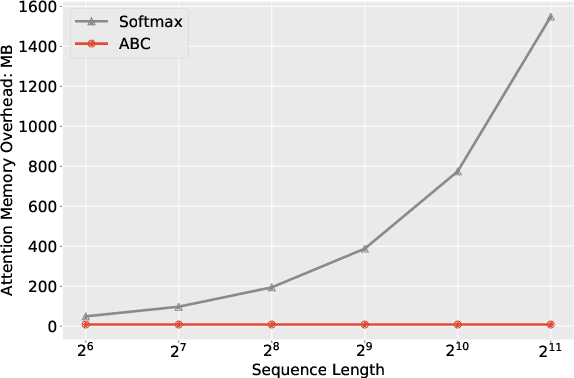
Transformer architectures have achieved state-of-the-art results on a variety of sequence modeling tasks. However, their attention mechanism comes with a quadratic complexity in sequence lengths, making the computational overhead prohibitive, especially for long sequences. Attention context can be seen as a random-access memory with each token taking a slot. Under this perspective, the memory size grows linearly with the sequence length, and so does the overhead of reading from it. One way to improve the efficiency is to bound the memory size. We show that disparate approaches can be subsumed into one abstraction, attention with bounded-memory control (ABC), and they vary in their organization of the memory. ABC reveals new, unexplored possibilities. First, it connects several efficient attention variants that would otherwise seem apart. Second, this abstraction gives new insights--an established approach (Wang et al., 2020b) previously thought to be not applicable in causal attention, actually is. Last, we present a new instance of ABC, which draws inspiration from existing ABC approaches, but replaces their heuristic memory-organizing functions with a learned, contextualized one. Our experiments on language modeling, machine translation, and masked language model finetuning show that our approach outperforms previous efficient attention models; compared to the strong transformer baselines, it significantly improves the inference time and space efficiency with no or negligible accuracy loss.
Expected Validation Performance and Estimation of a Random Variable's Maximum
Oct 01, 2021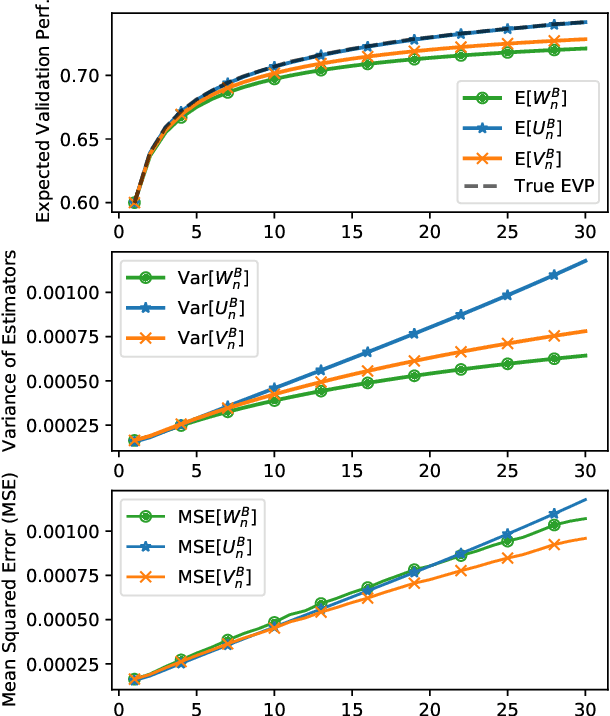
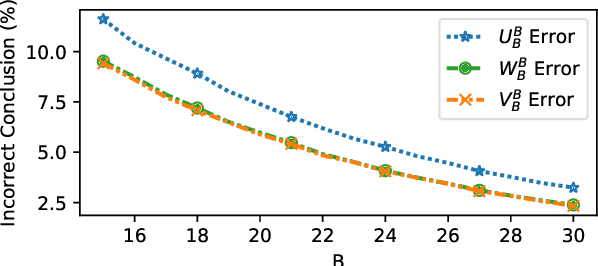
Research in NLP is often supported by experimental results, and improved reporting of such results can lead to better understanding and more reproducible science. In this paper we analyze three statistical estimators for expected validation performance, a tool used for reporting performance (e.g., accuracy) as a function of computational budget (e.g., number of hyperparameter tuning experiments). Where previous work analyzing such estimators focused on the bias, we also examine the variance and mean squared error (MSE). In both synthetic and realistic scenarios, we evaluate three estimators and find the unbiased estimator has the highest variance, and the estimator with the smallest variance has the largest bias; the estimator with the smallest MSE strikes a balance between bias and variance, displaying a classic bias-variance tradeoff. We use expected validation performance to compare between different models, and analyze how frequently each estimator leads to drawing incorrect conclusions about which of two models performs best. We find that the two biased estimators lead to the fewest incorrect conclusions, which hints at the importance of minimizing variance and MSE.
Data Efficient Masked Language Modeling for Vision and Language
Sep 05, 2021



Masked language modeling (MLM) is one of the key sub-tasks in vision-language pretraining. In the cross-modal setting, tokens in the sentence are masked at random, and the model predicts the masked tokens given the image and the text. In this paper, we observe several key disadvantages of MLM in this setting. First, as captions tend to be short, in a third of the sentences no token is sampled. Second, the majority of masked tokens are stop-words and punctuation, leading to under-utilization of the image. We investigate a range of alternative masking strategies specific to the cross-modal setting that address these shortcomings, aiming for better fusion of text and image in the learned representation. When pre-training the LXMERT model, our alternative masking strategies consistently improve over the original masking strategy on three downstream tasks, especially in low resource settings. Further, our pre-training approach substantially outperforms the baseline model on a prompt-based probing task designed to elicit image objects. These results and our analysis indicate that our method allows for better utilization of the training data.