 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull Reference Video Quality Assessment for Machine Learning-Based Video Codecs
Sep 02, 2023



Machine learning-based video codecs have made significant progress in the past few years. A critical area in the development of ML-based video codecs is an accurate evaluation metric that does not require an expensive and slow subjective test. We show that existing evaluation metrics that were designed and trained on DSP-based video codecs are not highly correlated to subjective opinion when used with ML video codecs due to the video artifacts being quite different between ML and video codecs. We provide a new dataset of ML video codec videos that have been accurately labeled for quality. We also propose a new full reference video quality assessment (FRVQA) model that achieves a Pearson Correlation Coefficient (PCC) of 0.99 and a Spearman's Rank Correlation Coefficient (SRCC) of 0.99 at the model level. We make the dataset and FRVQA model open source to help accelerate research in ML video codecs, and so that others can further improve the FRVQA model.
DeepVQE: Real Time Deep Voice Quality Enhancement for Joint Acoustic Echo Cancellation, Noise Suppression and Dereverberation
Jun 05, 2023


Acoustic echo cancellation (AEC), noise suppression (NS) and dereverberation (DR) are an integral part of modern full-duplex communication systems. As the demand for teleconferencing systems increases, addressing these tasks is required for an effective and efficient online meeting experience. Most prior research proposes solutions for these tasks separately, combining them with digital signal processing (DSP) based components, resulting in complex pipelines that are often impractical to deploy in real-world applications. This paper proposes a real-time cross-attention deep model, named DeepVQE, based on residual convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to simultaneously address AEC, NS, and DR. We conduct several ablation studies to analyze the contributions of different components of our model to the overall performance. DeepVQE achieves state-of-the-art performance on non-personalized tracks from the ICASSP 2023 Acoustic Echo Cancellation Challenge and ICASSP 2023 Deep Noise Suppression Challenge test sets, showing that a single model can handle multiple tasks with excellent performance. Moreover, the model runs in real-time and has been successfully tested for the Microsoft Teams platform.
PLCMOS -- a data-driven non-intrusive metric for the evaluation of packet loss concealment algorithms
May 24, 2023Speech quality assessment is a problem for every researcher working on models that produce or process speech. Human subjective ratings, the gold standard in speech quality assessment, are expensive and time-consuming to acquire in a quantity that is sufficient to get reliable data, while automated objective metrics show a low correlation with gold standard ratings. This paper presents PLCMOS, a non-intrusive data-driven tool for generating a robust, accurate estimate of the mean opinion score a human rater would assign an audio file that has been processed by being transmitted over a degraded packet-switched network with missing packets being healed by a packet loss concealment algorithm. Our new model shows a model-wise Pearson's correlation of ~0.97 and rank correlation of ~0.95 with human ratings, substantially above all other available intrusive and non-intrusive metrics. The model is released as an ONNX model for other researchers to use when building PLC systems.
Improving Meeting Inclusiveness using Speech Interruption Analysis
Apr 05, 2023



Meetings are a pervasive method of communication within all types of companies and organizations, and using remote collaboration systems to conduct meetings has increased dramatically since the COVID-19 pandemic. However, not all meetings are inclusive, especially in terms of the participation rates among attendees. In a recent large-scale survey conducted at Microsoft, the top suggestion given by meeting participants for improving inclusiveness is to improve the ability of remote participants to interrupt and acquire the floor during meetings. We show that the use of the virtual raise hand (VRH) feature can lead to an increase in predicted meeting inclusiveness at Microsoft. One challenge is that VRH is used in less than 1% of all meetings. In order to drive adoption of its usage to improve inclusiveness (and participation), we present a machine learning-based system that predicts when a meeting participant attempts to obtain the floor, but fails to interrupt (termed a `failed interruption'). This prediction can be used to nudge the user to raise their virtual hand within the meeting. We believe this is the first failed speech interruption detector, and the performance on a realistic test set has an area under curve (AUC) of 0.95 with a true positive rate (TPR) of 50% at a false positive rate (FPR) of <1%. To our knowledge, this is also the first dataset of interruption categories (including the failed interruption category) for remote meetings. Finally, we believe this is the first such system designed to improve meeting inclusiveness through speech interruption analysis and active intervention.
ICASSP 2023 Speech Signal Improvement Challenge
Apr 02, 2023The ICASSP 2023 Speech Signal Improvement Challenge is intended to stimulate research in the area of improving the speech signal quality in communication systems. The speech signal quality can be measured with SIG in ITU-T P.835 and is still a top issue in audio communication and conferencing systems. For example, in the ICASSP 2022 Deep Noise Suppression challenge, the improvement in the background and overall quality is impressive, but the improvement in the speech signal is statistically zero. To improve the speech signal the following speech impairment areas must be addressed: coloration, discontinuity, loudness, and reverberation. A dataset and test set were provided for the challenge, and the winners were determined using an extended crowdsourced implementation of ITU-T P.80's listening phase . The results show significant improvement was made across all measured dimensions of speech quality.
LSTM-based Video Quality Prediction Accounting for Temporal Distortions in Videoconferencing Calls
Mar 22, 2023



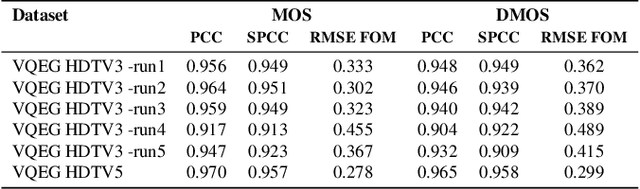
Current state-of-the-art video quality models, such as VMAF, give excellent prediction results by comparing the degraded video with its reference video. However, they do not consider temporal distortions (e.g., frame freezes or skips) that occur during videoconferencing calls. In this paper, we present a data-driven approach for modeling such distortions automatically by training an LSTM with subjective quality ratings labeled via crowdsourcing. The videos were collected from live videoconferencing calls in 83 different network conditions. We applied QR codes as markers on the source videos to create aligned references and compute temporal features based on the alignment vectors. Using these features together with VMAF core features, our proposed model achieves a PCC of 0.99 on the validation set. Furthermore, our model outputs per-frame quality that gives detailed insight into the cause of video quality impairments. The VCM model and dataset are open-sourced at https://github.com/microsoft/Video_Call_MOS.
ICASSP 2023 Deep Speech Enhancement Challenge
Mar 21, 2023
Deep Speech Enhancement Challenge is the 5th edition of deep noise suppression (DNS) challenges organized at ICASSP 2023 Signal Processing Grand Challenges. DNS challenges were organized during 2019-2023 to stimulate research in deep speech enhancement (DSE). Previous DNS challenges were organized at INTERSPEECH 2020, ICASSP 2021, INTERSPEECH 2021, and ICASSP 2022. From prior editions, we learnt that improving signal quality (SIG) is challenging particularly in presence of simultaneously active interfering talkers and noise. This challenge aims to develop models for joint denosing, dereverberation and suppression of interfering talkers. When primary talker wears a headphone, certain acoustic properties of their speech such as direct-to-reverberation (DRR), signal to noise ratio (SNR) etc. make it possible to suppress neighboring talkers even without enrollment data for primary talker. This motivated us to create two tracks for this challenge: (i) Track-1 Headset; (ii) Track-2 Speakerphone. Both tracks has fullband (48kHz) training data and testset, and each testclips has a corresponding enrollment data (10-30s duration) for primary talker. Each track invited submissions of personalized and non-personalized models all of which are evaluated through same subjective evaluation. Most models submitted to challenge were personalized models, same team is winner in both tracks where the best models has improvement of 0.145 and 0.141 in challenge's Score as compared to noisy blind testset.
Real-time Speech Interruption Analysis: From Cloud to Client Deployment
Oct 24, 2022Meetings are an essential form of communication for all types of organizations, and remote collaboration systems have been much more widely used since the COVID-19 pandemic. One major issue with remote meetings is that it is challenging for remote participants to interrupt and speak. We have recently developed the first speech interruption analysis model, which detects failed speech interruptions, shows very promising performance, and is being deployed in the cloud. To deliver this feature in a more cost-efficient and environment-friendly way, we reduced the model complexity and size to ship the WavLM_SI model in client devices. In this paper, we first describe how we successfully improved the True Positive Rate (TPR) at a 1% False Positive Rate (FPR) from 50.9% to 68.3% for the failed speech interruption detection model by training on a larger dataset and fine-tuning. We then shrank the model size from 222.7 MB to 9.3 MB with an acceptable loss in accuracy and reduced the complexity from 31.2 GMACS (Giga Multiply-Accumulate Operations per Second) to 4.3 GMACS. We also estimated the environmental impact of the complexity reduction, which can be used as a general guideline for large Transformer-based models, and thus make those models more accessible with less computation overhead.
A crowdsourced implementation of ITU-T P.910
Apr 14, 2022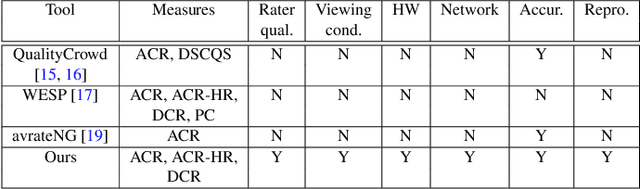
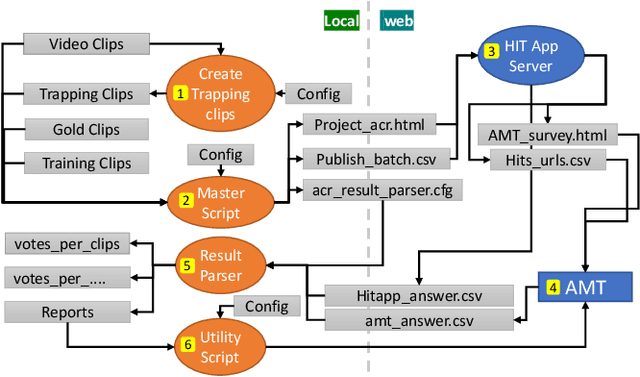

The gold standard for measuring video quality is the subjective test, and the most prevalent is the ITU-T P.910, a lab-based subjective standard in use for the past two decades. However, in practice using P.910 is slow, expensive, and requires a lab, which all create barriers to usage. As a result, most research papers that need to measure video quality don't use P.910 but rather metrics that are not well correlated to subjective opinion. We provide an open-source extension of P.910 based on crowdsourcing principles which address the speed, usage cost, and barrier to usage issues. We implement Absolute Category Rating (ACR), ACR with hidden reference (ACR-HR), and Degradation Category Rating (DCR). It includes rater, environment, hardware, and network qualifications, as well as gold and trapping questions to ensure quality. We have validated that the implementation is both accurate and highly reproducible compared to existing P.910 lab studies.
INTERSPEECH 2022 Audio Deep Packet Loss Concealment Challenge
Apr 11, 2022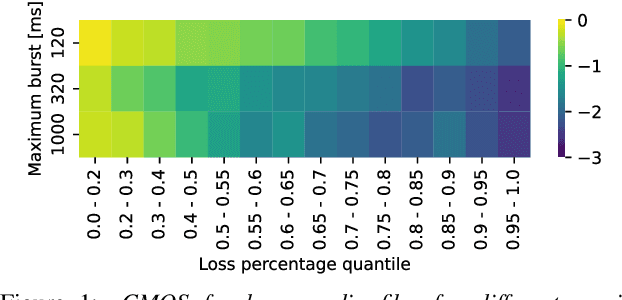
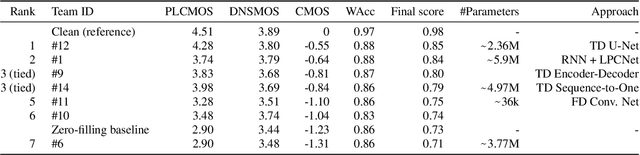
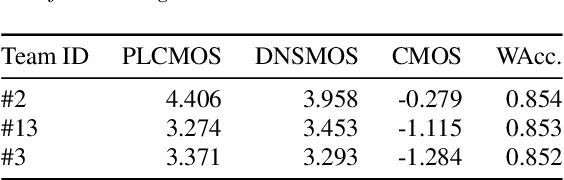
Audio Packet Loss Concealment (PLC) is the hiding of gaps in audio streams caused by data transmission failures in packet switched networks. This is a common problem, and of increasing importance as end-to-end VoIP telephony and teleconference systems become the default and ever more widely used form of communication in business as well as in personal usage. This paper presents the INTERSPEECH 2022 Audio Deep Packet Loss Concealment challenge. We first give an overview of the PLC problem, and introduce some classical approaches to PLC as well as recent work. We then present the open source dataset released as part of this challenge as well as the evaluation methods and metrics used to determine the winner. We also briefly introduce PLCMOS, a novel data-driven metric that can be used to quickly evaluate the performance PLC systems. Finally, we present the results of the INTERSPEECH 2022 Audio Deep PLC Challenge, and provide a summary of important takeaways.