 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-centric Dialog Training via Offline Reinforcement Learning
Oct 12, 2020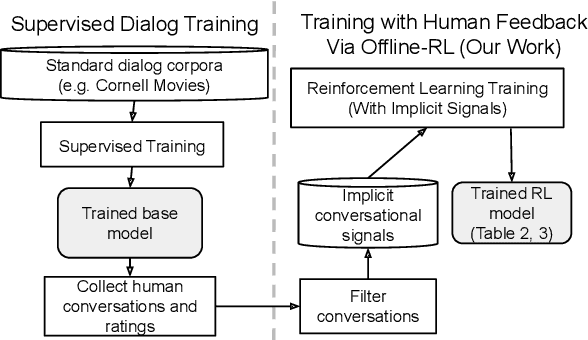
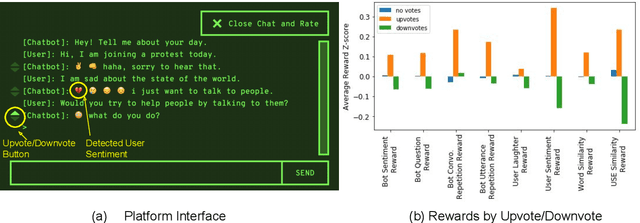
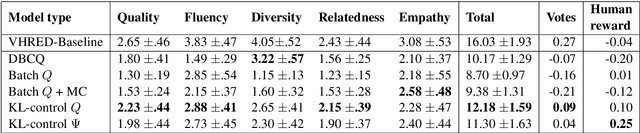
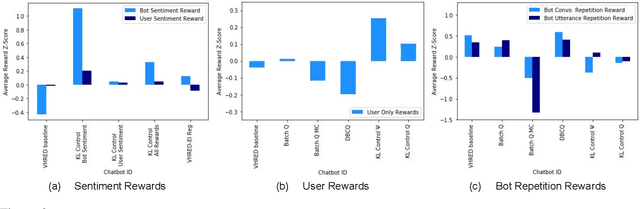
How can we train a dialog model to produce better conversations by learning from human feedback, without the risk of humans teaching it harmful chat behaviors? We start by hosting models online, and gather human feedback from real-time, open-ended conversations, which we then use to train and improve the models using offline reinforcement learning (RL). We identify implicit conversational cues including language similarity, elicitation of laughter, sentiment, and more, which indicate positive human feedback, and embed these in multiple reward functions. A well-known challenge is that learning an RL policy in an offline setting usually fails due to the lack of ability to explore and the tendency to make over-optimistic estimates of future reward. These problems become even harder when using RL for language models, which can easily have a 20,000 action vocabulary and many possible reward functions. We solve the challenge by developing a novel class of offline RL algorithms. These algorithms use KL-control to penalize divergence from a pre-trained prior language model, and use a new strategy to make the algorithm pessimistic, instead of optimistic, in the face of uncertainty. We test the resulting dialog model with ratings from 80 users in an open-domain setting and find it achieves significant improvements over existing deep offline RL approaches. The novel offline RL method is viable for improving any existing generative dialog model using a static dataset of human feedback.
A Robotic Positive Psychology Coach to Improve College Students' Wellbeing
Sep 08, 2020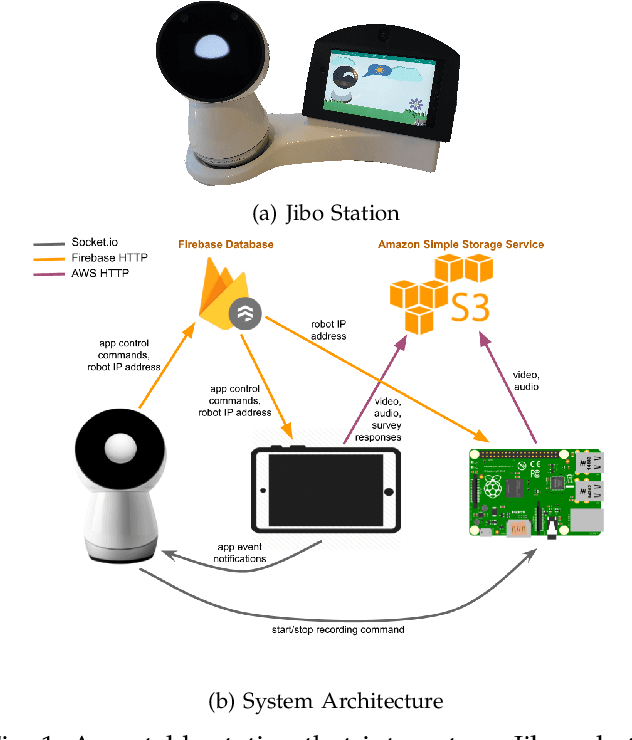

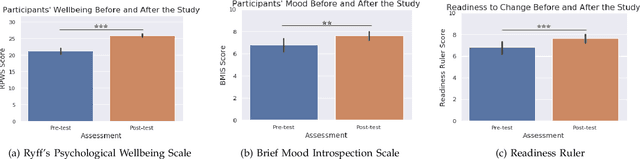
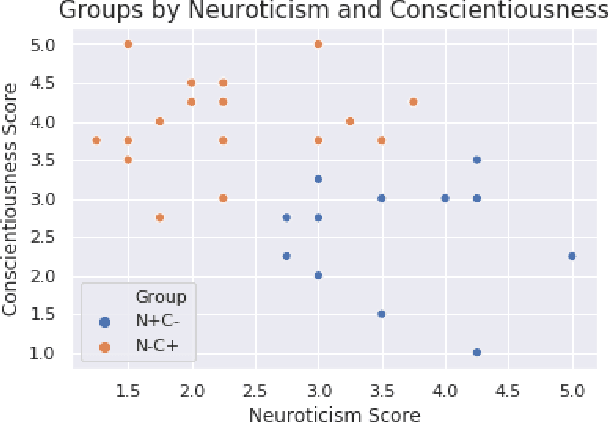
A significant number of college students suffer from mental health issues that impact their physical, social, and occupational outcomes. Various scalable technologies have been proposed in order to mitigate the negative impact of mental health disorders. However, the evaluation for these technologies, if done at all, often reports mixed results on improving users' mental health. We need to better understand the factors that align a user's attributes and needs with technology-based interventions for positive outcomes. In psychotherapy theory, therapeutic alliance and rapport between a therapist and a client is regarded as the basis for therapeutic success. In prior works, social robots have shown the potential to build rapport and a working alliance with users in various settings. In this work, we explore the use of a social robot coach to deliver positive psychology interventions to college students living in on-campus dormitories. We recruited 35 college students to participate in our study and deployed a social robot coach in their room. The robot delivered daily positive psychology sessions among other useful skills like delivering the weather forecast, scheduling reminders, etc. We found a statistically significant improvement in participants' psychological wellbeing, mood, and readiness to change behavior for improved wellbeing after they completed the study. Furthermore, students' personality traits were found to have a significant association with intervention efficacy. Analysis of the post-study interview revealed students' appreciation of the robot's companionship and their concerns for privacy.
Dyadic Speech-based Affect Recognition using DAMI-P2C Parent-child Multimodal Interaction Dataset
Aug 20, 2020
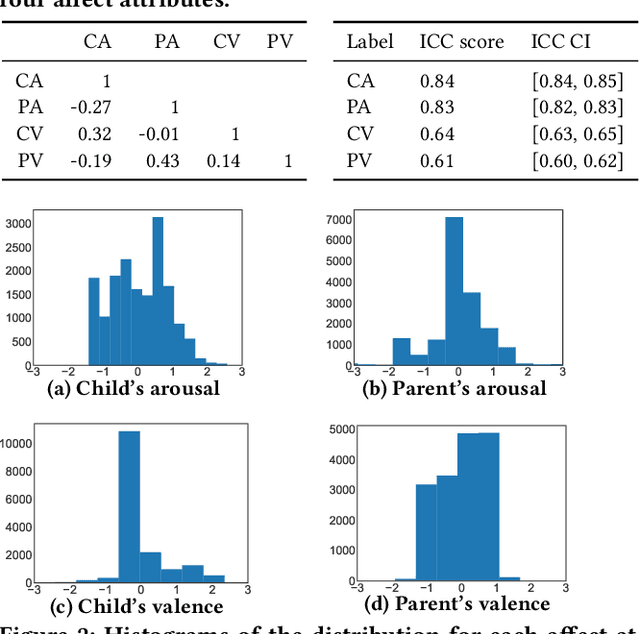

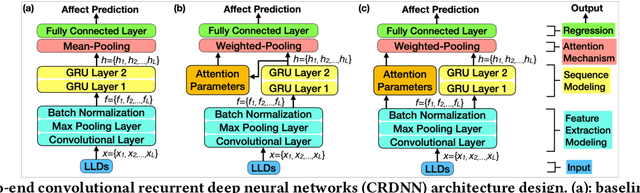
Automatic speech-based affect recognition of individuals in dyadic conversation is a challenging task, in part because of its heavy reliance on manual pre-processing. Traditional approaches frequently require hand-crafted speech features and segmentation of speaker turns. In this work, we design end-to-end deep learning methods to recognize each person's affective expression in an audio stream with two speakers, automatically discovering features and time regions relevant to the target speaker's affect. We integrate a local attention mechanism into the end-to-end architecture and compare the performance of three attention implementations -- one mean pooling and two weighted pooling methods. Our results show that the proposed weighted-pooling attention solutions are able to learn to focus on the regions containing target speaker's affective information and successfully extract the individual's valence and arousal intensity. Here we introduce and use a "dyadic affect in multimodal interaction - parent to child" (DAMI-P2C) dataset collected in a study of 34 families, where a parent and a child (3-7 years old) engage in reading storybooks together. In contrast to existing public datasets for affect recognition, each instance for both speakers in the DAMI-P2C dataset is annotated for the perceived affect by three labelers. To encourage more research on the challenging task of multi-speaker affect sensing, we make the annotated DAMI-P2C dataset publicly available, including acoustic features of the dyads' raw audios, affect annotations, and a diverse set of developmental, social, and demographic profiles of each dyad.
Hierarchical Reinforcement Learning for Open-Domain Dialog
Sep 18, 2019
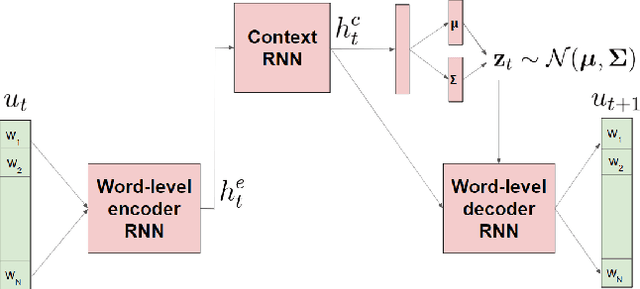
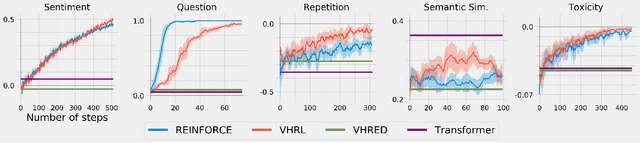
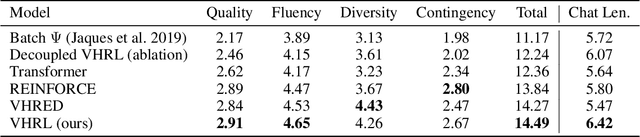
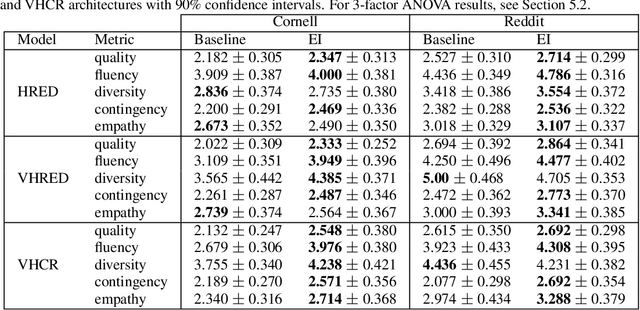
Open-domain dialog generation is a challenging problem; maximum likelihood training can lead to repetitive outputs, models have difficulty tracking long-term conversational goals, and training on standard movie or online datasets may lead to the generation of inappropriate, biased, or offensive text. Reinforcement Learning (RL) is a powerful framework that could potentially address these issues, for example by allowing a dialog model to optimize for reducing toxicity and repetitiveness. However, previous approaches which apply RL to open-domain dialog generation do so at the word level, making it difficult for the model to learn proper credit assignment for long-term conversational rewards. In this paper, we propose a novel approach to hierarchical reinforcement learning, VHRL, which uses policy gradients to tune the utterance-level embedding of a variational sequence model. This hierarchical approach provides greater flexibility for learning long-term, conversational rewards. We use self-play and RL to optimize for a set of human-centered conversation metrics, and show that our approach provides significant improvements -- in terms of both human evaluation and automatic metrics -- over state-of-the-art dialog models, including Transformers.
Pain Detection with fNIRS-Measured Brain Signals: A Personalized Machine Learning Approach Using the Wavelet Transform and Bayesian Hierarchical Modeling with Dirichlet Process Priors
Jul 30, 2019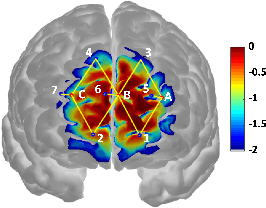
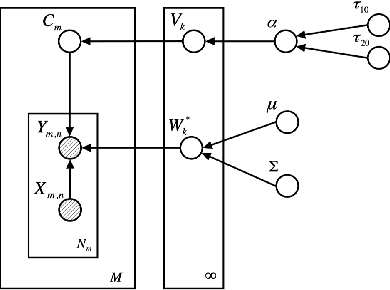

Currently self-report pain ratings are the gold standard in clinical pain assessment. However, the development of objective automatic measures of pain could substantially aid pain diagnosis and therapy. Recent neuroimaging studies have shown the potential of functional near-infrared spectroscopy (fNIRS) for pain detection. This is a brain-imaging technique that provides non-invasive, long-term measurements of cortical hemoglobin concentration changes. In this study, we focused on fNIRS signals acquired exclusively from the prefrontal cortex, which can be accessed unobtrusively, and derived an algorithm for the detection of the presence of pain using Bayesian hierarchical modelling with wavelet features. This approach allows personalization of the inference process by accounting for inter-participant variability in pain responses. Our work highlights the importance of adopting a personalized approach and supports the use of fNIRS for pain assessment.
Detection of Real-world Driving-induced Affective State Using Physiological Signals and Multi-view Multi-task Machine Learning
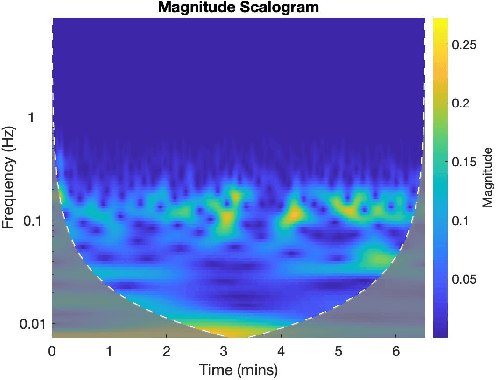
Jul 19, 2019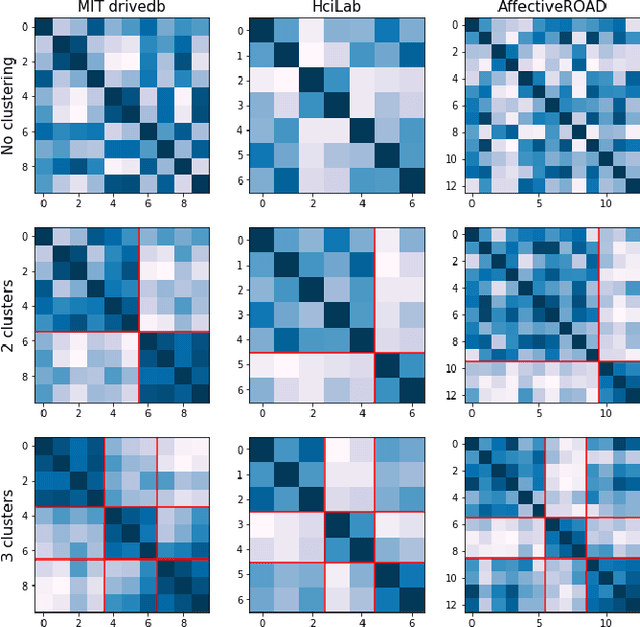
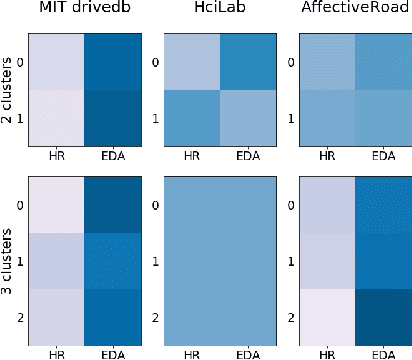
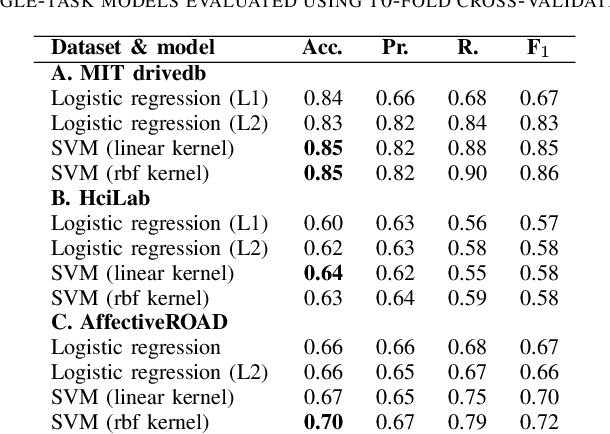
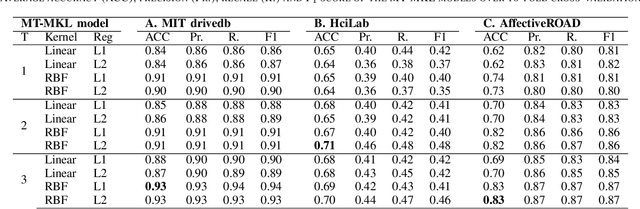
Affective states have a critical role in driving performance and safety. They can degrade driver situation awareness and negatively impact cognitive processes, severely diminishing road safety. Therefore, detecting and assessing drivers' affective states is crucial in order to help improve the driving experience, and increase safety, comfort and well-being. Recent advances in affective computing have enabled the detection of such states. This may lead to empathic automotive user interfaces that account for the driver's emotional state and influence the driver in order to improve safety. In this work, we propose a multiview multi-task machine learning method for the detection of driver's affective states using physiological signals. The proposed approach is able to account for inter-drive variability in physiological responses while enabling interpretability of the learned models, a factor that is especially important in systems deployed in the real world. We evaluate the models on three different datasets containing real-world driving experiences. Our results indicate that accounting for drive-specific differences significantly improves model performance.
Way Off-Policy Batch Deep Reinforcement Learning of Implicit Human Preferences in Dialog
Jul 08, 2019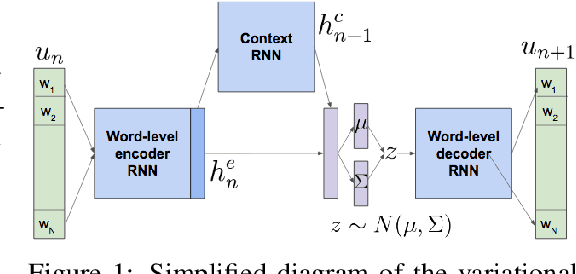
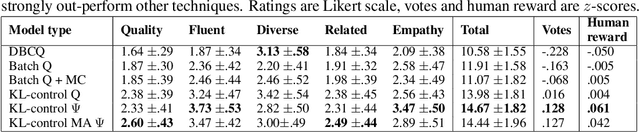

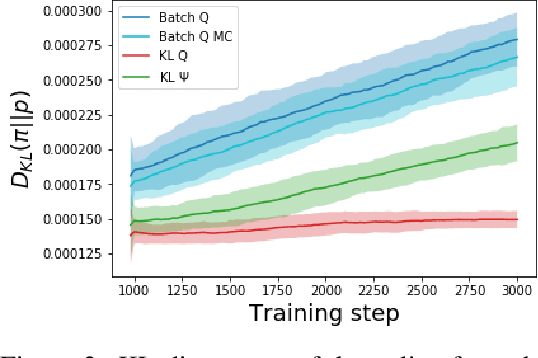
Most deep reinforcement learning (RL) systems are not able to learn effectively from off-policy data, especially if they cannot explore online in the environment. These are critical shortcomings for applying RL to real-world problems where collecting data is expensive, and models must be tested offline before being deployed to interact with the environment -- e.g. systems that learn from human interaction. Thus, we develop a novel class of off-policy batch RL algorithms, which are able to effectively learn offline, without exploring, from a fixed batch of human interaction data. We leverage models pre-trained on data as a strong prior, and use KL-control to penalize divergence from this prior during RL training. We also use dropout-based uncertainty estimates to lower bound the target Q-values as a more efficient alternative to Double Q-Learning. The algorithms are tested on the problem of open-domain dialog generation -- a challenging reinforcement learning problem with a 20,000-dimensional action space. Using our Way Off-Policy algorithm, we can extract multiple different reward functions post-hoc from collected human interaction data, and learn effectively from all of these. We test the real-world generalization of these systems by deploying them live to converse with humans in an open-domain setting, and demonstrate that our algorithm achieves significant improvements over prior methods in off-policy batch RL.
Approximating Interactive Human Evaluation with Self-Play for Open-Domain Dialog Systems
Jun 21, 2019
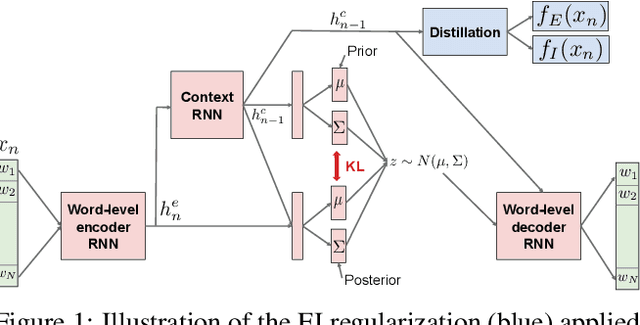
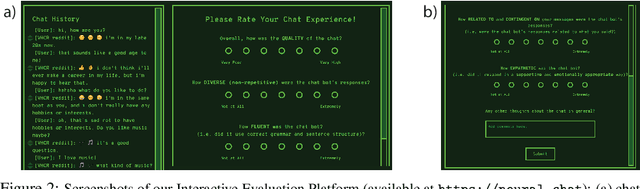
Building an open-domain conversational agent is a challenging problem. Current evaluation methods, mostly post-hoc judgments of single-turn evaluation, do not capture conversation quality in a realistic interactive context. In this paper, we investigate interactive human evaluation and provide evidence for its necessity; we then introduce a novel, model-agnostic, and dataset-agnostic method to approximate it. In particular, we propose a self-play scenario where the dialog system talks to itself and we calculate a combination of proxies such as sentiment and semantic coherence on the conversation trajectory. We show that this metric is capable of capturing the human-rated quality of a dialog model better than any automated metric known to-date, achieving a significant Pearson correlation (r>.7, p<.05). To investigate the strengths of this novel metric and interactive evaluation in comparison to state-of-the-art metrics and one-turn evaluation, we perform extended experiments with a set of models, including several that make novel improvements to recent hierarchical dialog generation architectures through sentiment and semantic knowledge distillation on the utterance level. Finally, we open-source the interactive evaluation platform we built and the dataset we collected to allow researchers to efficiently deploy and evaluate generative dialog models.
Deep Reinforcement Learning for Optimal Critical Care Pain Management with Morphine using Dueling Double-Deep Q Networks
Apr 25, 2019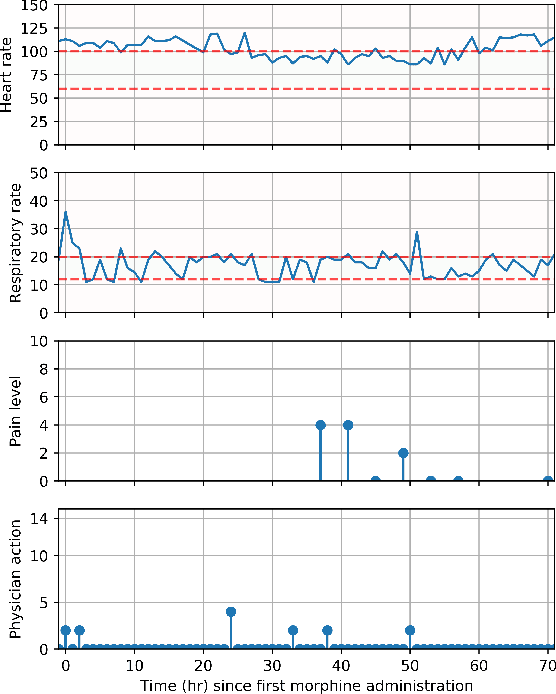
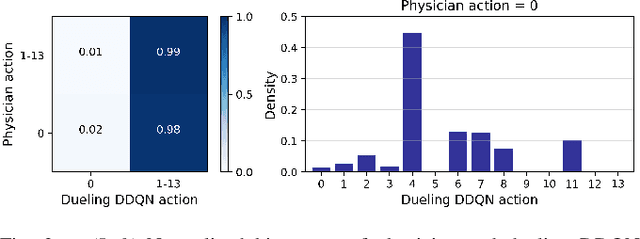
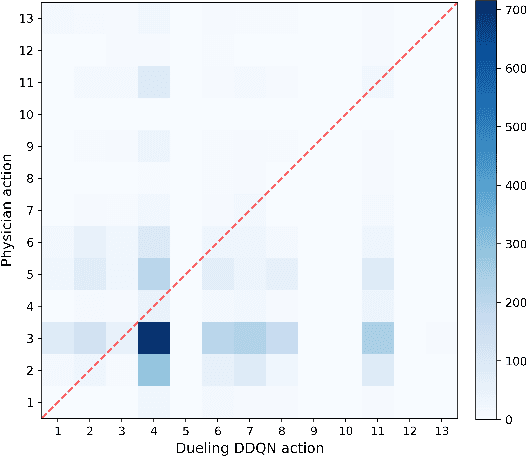
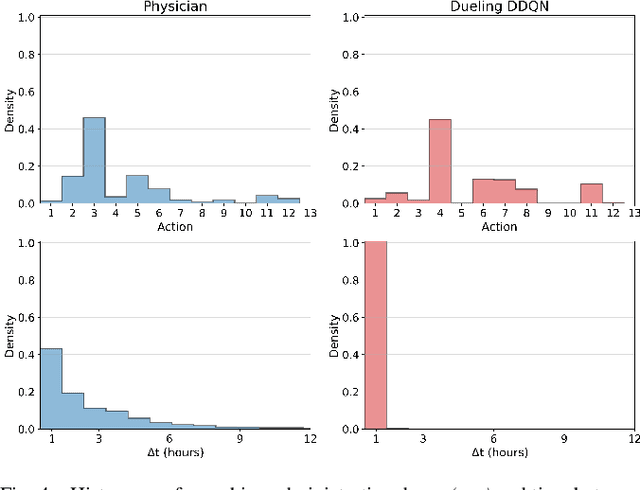
Opioids are the preferred medications for the treatment of pain in the intensive care unit. While undertreatment leads to unrelieved pain and poor clinical outcomes, excessive use of opioids puts patients at risk of experiencing multiple adverse effects. In this work, we present a sequential decision making framework for opioid dosing based on deep reinforcement learning. It provides real-time clinically interpretable dosing recommendations, personalized according to each patient's evolving pain and physiological condition. We focus on morphine, one of the most commonly prescribed opioids. To train and evaluate the model, we used retrospective data from the publicly available MIMIC-3 database. Our results demonstrate that reinforcement learning may be used to aid decision making in the intensive care setting by providing personalized pain management interventions.
Learning via social awareness: Improving a deep generative sketching model with facial feedback
Aug 27, 2018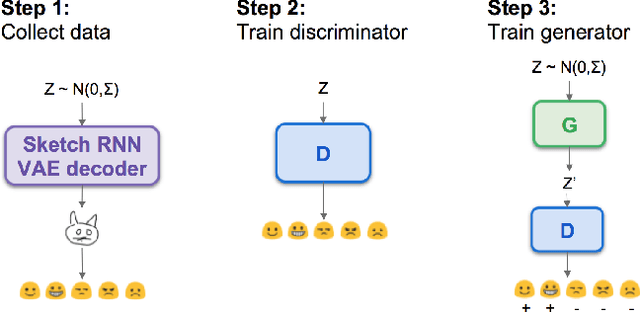
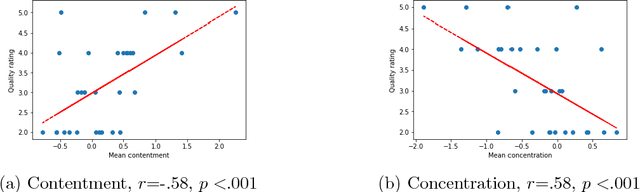
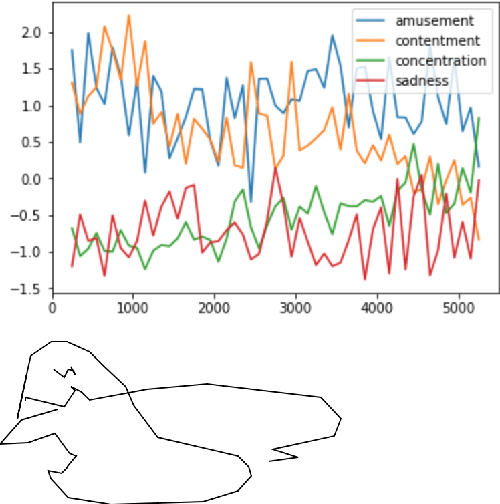
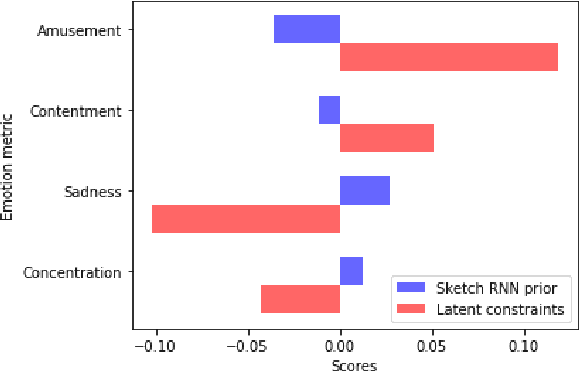
In the quest towards general artificial intelligence (AI), researchers have explored developing loss functions that act as intrinsic motivators in the absence of external rewards. This paper argues that such research has overlooked an important and useful intrinsic motivator: social interaction. We posit that making an AI agent aware of implicit social feedback from humans can allow for faster learning of more generalizable and useful representations, and could potentially impact AI safety. We collect social feedback in the form of facial expression reactions to samples from Sketch RNN, an LSTM-based variational autoencoder (VAE) designed to produce sketch drawings. We use a Latent Constraints GAN (LC-GAN) to learn from the facial feedback of a small group of viewers, by optimizing the model to produce sketches that it predicts will lead to more positive facial expressions. We show in multiple independent evaluations that the model trained with facial feedback produced sketches that are more highly rated, and induce significantly more positive facial expressions. Thus, we establish that implicit social feedback can improve the output of a deep learning model.