 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentScore: Intent-Conditioned Action Evaluation for Computer-Use Agents
Apr 06, 2026Computer-Use Agents (CUAs) leverage large language models to execute GUI operations on desktop environments, yet they generate actions without evaluating action quality, leading to irreversible errors that cascade through subsequent steps. We propose IntentScore, a plan-aware reward model that learns to score candidate actions from 398K offline GUI interaction steps spanning three operating systems. IntentScore trains with two complementary objectives: contrastive alignment for state-action relevance and margin ranking for action correctness. Architecturally, it embeds each candidate's planning intent in the action encoder, enabling discrimination between candidates with similar actions but different rationales. IntentScore achieves 97.5% pairwise discrimination accuracy on held-out evaluation. Deployed as a re-ranker for Agent S3 on OSWorld, an environment entirely unseen during training, IntentScore improves task success rate by 6.9 points, demonstrating that reward estimation learned from heterogeneous offline trajectories generalizes to unseen agents and task distributions.
Reasoning Knowledge-Gap in Drone Planning via LLM-based Active Elicitation
Mar 08, 2026Human-AI joint planning in Unmanned Aerial Vehicles (UAVs) typically relies on control handover when facing environmental uncertainties, which is often inefficient and cognitively demanding for non-expert operators. To address this, we propose a novel framework that shifts the collaboration paradigm from control takeover to active information elicitation. We introduce the Minimal Information Neuro-Symbolic Tree (MINT), a reasoning mechanism that explicitly structures knowledge gaps regarding obstacles and goals into a queryable format. By leveraging large language models, our system formulates optimal binary queries to resolve specific ambiguities with minimal human interaction. We demonstrate the efficacy of this approach through a comprehensive workflow integrating a vision-language model for perception, voice interfaces, and a low-level UAV control module in both high-fidelity NVIDIA Isaac simulations and real-world deployments. Experimental results show that our method achieves a significant improvement in the success rate for complex search-and-rescue tasks while significantly reducing the frequency of human interaction compared to exhaustive querying baselines.
Uncertainty Mitigation and Intent Inference: A Dual-Mode Human-Machine Joint Planning System
Mar 08, 2026Effective human-robot collaboration in open-world environments requires joint planning under uncertain conditions. However, existing approaches often treat humans as passive supervisors, preventing autonomous agents from becoming human-like teammates that can actively model teammate behaviors, reason about knowledge gaps, query, and elicit responses through communication to resolve uncertainties. To address these limitations, we propose a unified human-robot joint planning system designed to tackle dual sources of uncertainty: task-relevant knowledge gaps and latent human intent. Our system operates in two complementary modes. First, an uncertainty-mitigation joint planning module enables two-way conversations to resolve semantic ambiguity and object uncertainty. It utilizes an LLM-assisted active elicitation mechanism and a hypothesis-augmented A^* search, subsequently computing an optimal querying policy via dynamic programming to minimize interaction and verification costs. Second, a real-time intent-aware collaboration module maintains a probabilistic belief over the human's latent task intent via spatial and directional cues, enabling dynamic, coordination-aware task selection for agents without explicit communication. We validate the proposed system in both Gazebo simulations and real-world UAV deployments integrated with a Vision-Language Model (VLM)-based 3D semantic perception pipeline. Experimental results demonstrate that the system significantly cuts the interaction cost by 51.9% in uncertainty-mitigation planning and reduces the task execution time by 25.4% in intent-aware cooperation compared to the baselines.
Agent Alpha: Tree Search Unifying Generation, Exploration and Evaluation for Computer-Use Agents
Feb 03, 2026While scaling test-time compute through trajectory-level sampling has significantly improved Graphical User Interface (GUI) agents, the lack of regressive ability prevents the reuse of partial successes and the recovery from early missteps. In this paper, we introduce Agent Alpha, a unified framework that synergizes generation, exploration, and evaluation through step-level Monte Carlo Tree Search (MCTS). It enables active modeling or exploiting structures of the planning space. By integrating alpha-UCT guided search into the interaction loop, Agent Alpha enables deliberate planning, facilitating early pruning of suboptimal branches and efficient prefix reuse. We also employ comparison-driven evaluation to mitigate absolute scoring biases and diversity-constrained expansion to maintain a compact, informative search space. Regret bound of alpha-UCT is analyzed. On the OSWorld benchmark, Agent Alpha achieves a state-of-the-art success rate of $\sim 77\%$, significantly outperforming trajectory-level baselines under equivalent compute.
ACDZero: Graph-Embedding-Based Tree Search for Mastering Automated Cyber Defense
Jan 05, 2026Automated cyber defense (ACD) seeks to protect computer networks with minimal or no human intervention, reacting to intrusions by taking corrective actions such as isolating hosts, resetting services, deploying decoys, or updating access controls. However, existing approaches for ACD, such as deep reinforcement learning (RL), often face difficult exploration in complex networks with large decision/state spaces and thus require an expensive amount of samples. Inspired by the need to learn sample-efficient defense policies, we frame ACD in CAGE Challenge 4 (CAGE-4 / CC4) as a context-based partially observable Markov decision problem and propose a planning-centric defense policy based on Monte Carlo Tree Search (MCTS). It explicitly models the exploration-exploitation tradeoff in ACD and uses statistical sampling to guide exploration and decision making. We make novel use of graph neural networks (GNNs) to embed observations from the network as attributed graphs, to enable permutation-invariant reasoning over hosts and their relationships. To make our solution practical in complex search spaces, we guide MCTS with learned graph embeddings and priors over graph-edit actions, combining model-free generalization and policy distillation with look-ahead planning. We evaluate the resulting agent on CC4 scenarios involving diverse network structures and adversary behaviors, and show that our search-guided, graph-embedding-based planning improves defense reward and robustness relative to state-of-the-art RL baselines.
A Cluster-Based Weighted Feature Similarity Moving Target Tracking Algorithm for Automotive FMCW Radar
Dec 13, 2021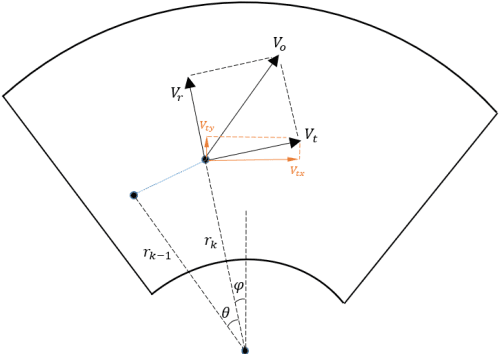


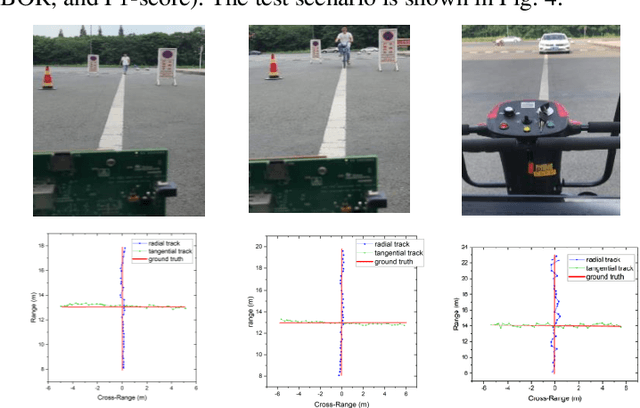
We studied a target tracking algorithm based on millimeter-wave (MMW) radar in an autonomous driving environment. Aiming at the cluster matching in the target tracking stage, a new weighted feature similarity algorithm is proposed, which increases the matching rate of the same target in adjacent frames under strong environmental noise and multiple interference targets. For autonomous driving scenarios, we constructed a method that uses its motion parameters to extract and correct the trajectory of a moving target, which solves the problem of moving target detection and trajectory correction during vehicle movement. Finally, the feasibility of the proposed method was verified by a series of experiments in autonomous driving environments. The results verify the high recognition accuracy and low positional error of the method.