 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanistic Interpretability for Learning Assurance of a Vision-Based Landing System
May 20, 2026EASA's learning-assurance guidance requires data-driven aviation systems to build and monitor their own situation representation, yet for neural networks the technical means to provide such evidence remain an open problem. We address this gap for a vision-based aircraft landing system: we propose that a minimally assurable model must at least be shown to separate content from style in its own situation representation. Showing that the model's predictions then rely largely on the contentful representation components leads to a concrete assurance path. To demonstrate this assurance path on a concrete model we train a vision transformer model for runway keypoint regression on the LARDv2 dataset. The model, which acts as the subject for our assurance demonstration, produces per-patch embeddings that we decompose into interpretable atoms via K-SVD sparse dictionary learning. A qualitative visualization confirms that contentful atoms track task-relevant runway structure and stylistic atoms track domain-specific appearance, and the regression head is shown to place almost all of its linear weight on contentful atoms. We further build on the content/style separation and define out-of-model-scope (OOMS) detection, a novel runtime assurance approach directly monitoring the model's situation representation. OOMS monitoring is complementary to operational design domain and output-space out-of-distribution monitoring and addresses concrete requirements of the recent EASA guidance. By directly analyzing a model's situation representation both at test time and runtime, this work delivers the first concrete piece of the representation-level evidence that EASA learning-assurance guidance demands, and points to mechanistic interpretability as a practical building block of future aviation safety cases.
DB-KSVD: Scalable Alternating Optimization for Disentangling High-Dimensional Embedding Spaces
May 24, 2025Dictionary learning has recently emerged as a promising approach for mechanistic interpretability of large transformer models. Disentangling high-dimensional transformer embeddings, however, requires algorithms that scale to high-dimensional data with large sample sizes. Recent work has explored sparse autoencoders (SAEs) for this problem. However, SAEs use a simple linear encoder to solve the sparse encoding subproblem, which is known to be NP-hard. It is therefore interesting to understand whether this structure is sufficient to find good solutions to the dictionary learning problem or if a more sophisticated algorithm could find better solutions. In this work, we propose Double-Batch KSVD (DB-KSVD), a scalable dictionary learning algorithm that adapts the classic KSVD algorithm. DB-KSVD is informed by the rich theoretical foundations of KSVD but scales to datasets with millions of samples and thousands of dimensions. We demonstrate the efficacy of DB-KSVD by disentangling embeddings of the Gemma-2-2B model and evaluating on six metrics from the SAEBench benchmark, where we achieve competitive results when compared to established approaches based on SAEs. By matching SAE performance with an entirely different optimization approach, our results suggest that (i) SAEs do find strong solutions to the dictionary learning problem and (ii) that traditional optimization approaches can be scaled to the required problem sizes, offering a promising avenue for further research. We provide an implementation of DB-KSVD at https://github.com/RomeoV/KSVD.jl.
Probabilistic Parameter Estimators and Calibration Metrics for Pose Estimation from Image Features
Jul 23, 2024



This paper addresses the challenge of probabilistic parameter estimation given measurement uncertainty in real-time. We provide a general formulation and apply this to pose estimation for an autonomous visual landing system. We present three probabilistic parameter estimators: a least-squares sampling approach, a linear approximation method, and a probabilistic programming estimator. To evaluate these estimators, we introduce novel closed-form expressions for measuring calibration and sharpness specifically for multivariate normal distributions. Our experimental study compares the three estimators under various noise conditions. We demonstrate that the linear approximation estimator can produce sharp and well-calibrated pose predictions significantly faster than the other methods but may yield overconfident predictions in certain scenarios. Additionally, we demonstrate that these estimators can be integrated with a Kalman filter for continuous pose estimation during a runway approach where we observe a 50\% improvement in sharpness while maintaining marginal calibration. This work contributes to the integration of data-driven computer vision models into complex safety-critical aircraft systems and provides a foundation for developing rigorous certification guidelines for such systems.
A Holistic Assessment of the Reliability of Machine Learning Systems
Jul 29, 2023As machine learning (ML) systems increasingly permeate high-stakes settings such as healthcare, transportation, military, and national security, concerns regarding their reliability have emerged. Despite notable progress, the performance of these systems can significantly diminish due to adversarial attacks or environmental changes, leading to overconfident predictions, failures to detect input faults, and an inability to generalize in unexpected scenarios. This paper proposes a holistic assessment methodology for the reliability of ML systems. Our framework evaluates five key properties: in-distribution accuracy, distribution-shift robustness, adversarial robustness, calibration, and out-of-distribution detection. A reliability score is also introduced and used to assess the overall system reliability. To provide insights into the performance of different algorithmic approaches, we identify and categorize state-of-the-art techniques, then evaluate a selection on real-world tasks using our proposed reliability metrics and reliability score. Our analysis of over 500 models reveals that designing for one metric does not necessarily constrain others but certain algorithmic techniques can improve reliability across multiple metrics simultaneously. This study contributes to a more comprehensive understanding of ML reliability and provides a roadmap for future research and development.
Instance-wise algorithm configuration with graph neural networks
Feb 10, 2022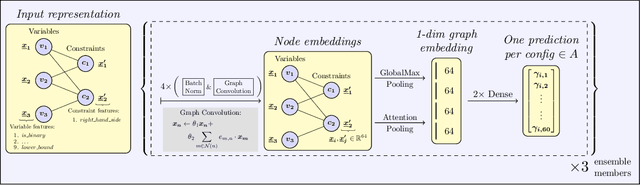

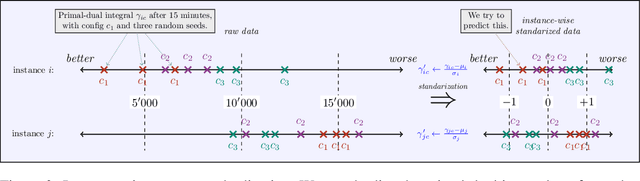
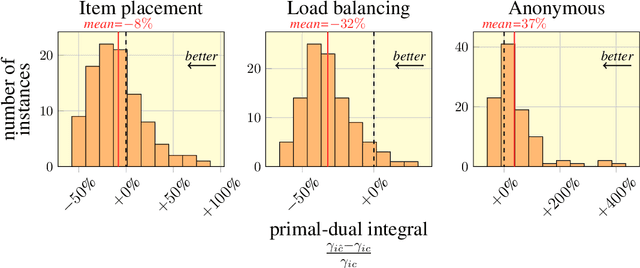
We present our submission for the configuration task of the Machine Learning for Combinatorial Optimization (ML4CO) NeurIPS 2021 competition. The configuration task is to predict a good configuration of the open-source solver SCIP to solve a mixed integer linear program (MILP) efficiently. We pose this task as a supervised learning problem: First, we compile a large dataset of the solver performance for various configurations and all provided MILP instances. Second, we use this data to train a graph neural network that learns to predict a good configuration for a specific instance. The submission was tested on the three problem benchmarks of the competition and improved solver performance over the default by 12% and 35% and 8% across the hidden test instances. We ranked 3rd out of 15 on the global leaderboard and won the student leaderboard. We make our code publicly available at \url{https://github.com/RomeoV/ml4co-competition} .