 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite Versus Infinite Neural Networks: an Empirical Study
Sep 08, 2020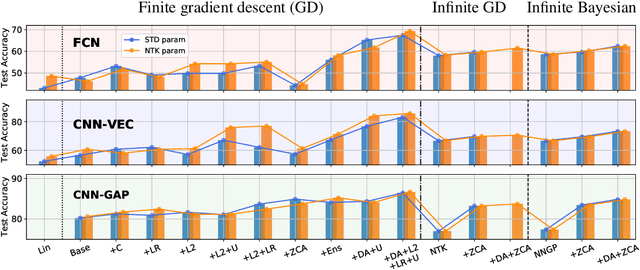



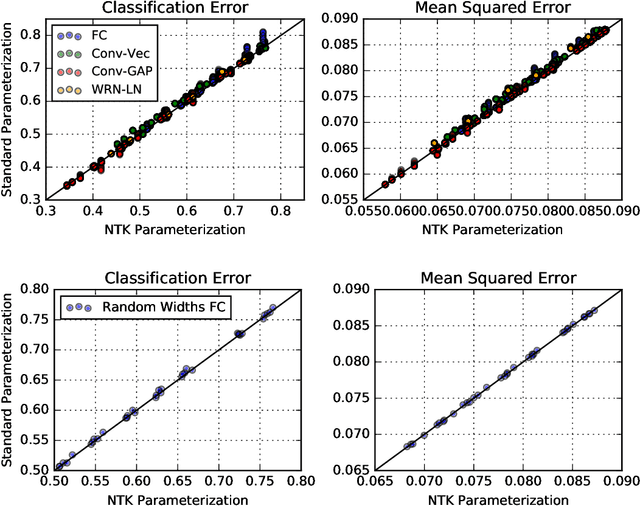
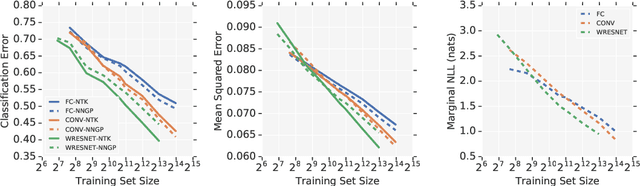
We perform a careful, thorough, and large scale empirical study of the correspondence between wide neural networks and kernel methods. By doing so, we resolve a variety of open questions related to the study of infinitely wide neural networks. Our experimental results include: kernel methods outperform fully-connected finite-width networks, but underperform convolutional finite width networks; neural network Gaussian process (NNGP) kernels frequently outperform neural tangent (NT) kernels; centered and ensembled finite networks have reduced posterior variance and behave more similarly to infinite networks; weight decay and the use of a large learning rate break the correspondence between finite and infinite networks; the NTK parameterization outperforms the standard parameterization for finite width networks; diagonal regularization of kernels acts similarly to early stopping; floating point precision limits kernel performance beyond a critical dataset size; regularized ZCA whitening improves accuracy; finite network performance depends non-monotonically on width in ways not captured by double descent phenomena; equivariance of CNNs is only beneficial for narrow networks far from the kernel regime. Our experiments additionally motivate an improved layer-wise scaling for weight decay which improves generalization in finite-width networks. Finally, we develop improved best practices for using NNGP and NT kernels for prediction, including a novel ensembling technique. Using these best practices we achieve state-of-the-art results on CIFAR-10 classification for kernels corresponding to each architecture class we consider.
Exact posterior distributions of wide Bayesian neural networks
Jun 18, 2020
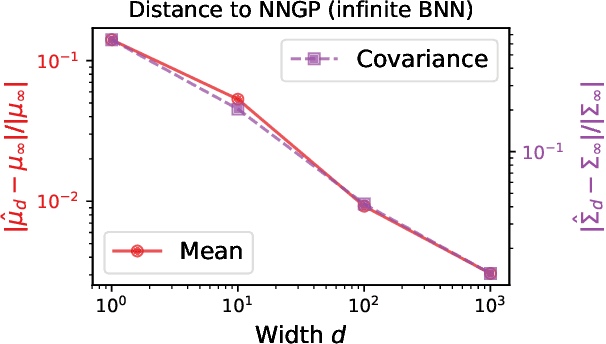
Recent work has shown that the prior over functions induced by a deep Bayesian neural network (BNN) behaves as a Gaussian process (GP) as the width of all layers becomes large. However, many BNN applications are concerned with the BNN function space posterior. While some empirical evidence of the posterior convergence was provided in the original works of Neal (1996) and Matthews et al. (2018), it is limited to small datasets or architectures due to the notorious difficulty of obtaining and verifying exactness of BNN posterior approximations. We provide the missing theoretical proof that the exact BNN posterior converges (weakly) to the one induced by the GP limit of the prior. For empirical validation, we show how to generate exact samples from a finite BNN on a small dataset via rejection sampling.
Infinite attention: NNGP and NTK for deep attention networks
Jun 18, 2020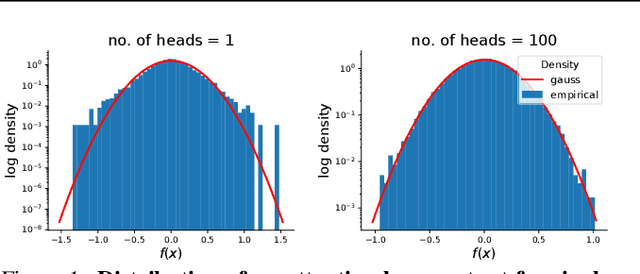


There is a growing amount of literature on the relationship between wide neural networks (NNs) and Gaussian processes (GPs), identifying an equivalence between the two for a variety of NN architectures. This equivalence enables, for instance, accurate approximation of the behaviour of wide Bayesian NNs without MCMC or variational approximations, or characterisation of the distribution of randomly initialised wide NNs optimised by gradient descent without ever running an optimiser. We provide a rigorous extension of these results to NNs involving attention layers, showing that unlike single-head attention, which induces non-Gaussian behaviour, multi-head attention architectures behave as GPs as the number of heads tends to infinity. We further discuss the effects of positional encodings and layer normalisation, and propose modifications of the attention mechanism which lead to improved results for both finite and infinitely wide NNs. We evaluate attention kernels empirically, leading to a moderate improvement upon the previous state-of-the-art on CIFAR-10 for GPs without trainable kernels and advanced data preprocessing. Finally, we introduce new features to the Neural Tangents library (Novak et al., 2020) allowing applications of NNGP/NTK models, with and without attention, to variable-length sequences, with an example on the IMDb reviews dataset.
On the infinite width limit of neural networks with a standard parameterization
Jan 25, 2020
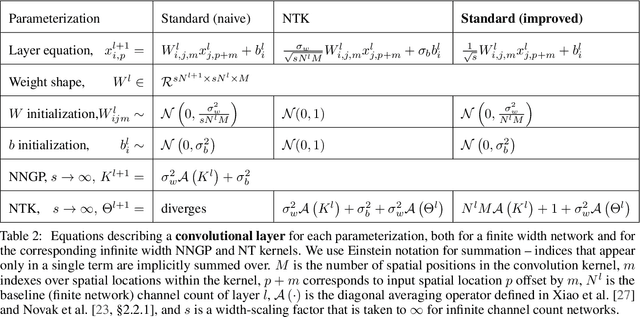
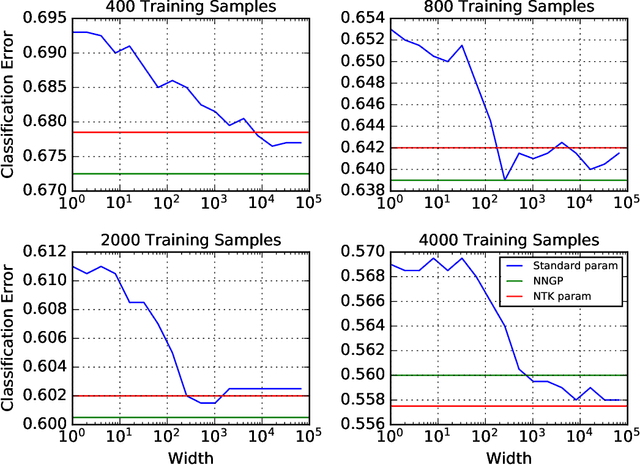
There are currently two parameterizations used to derive fixed kernels corresponding to infinite width neural networks, the NTK (Neural Tangent Kernel) parameterization and the naive standard parameterization. However, the extrapolation of both of these parameterizations to infinite width is problematic. The standard parameterization leads to a divergent neural tangent kernel while the NTK parameterization fails to capture crucial aspects of finite width networks such as: the dependence of training dynamics on relative layer widths, the relative training dynamics of weights and biases, and a nonstandard learning rate scale. Here we propose an improved extrapolation of the standard parameterization that preserves all of these properties as width is taken to infinity and yields a well-defined neural tangent kernel. We show experimentally that the resulting kernels typically achieve similar accuracy to those resulting from an NTK parameterization, but with better correspondence to the parameterization of typical finite width networks. Additionally, with careful tuning of width parameters, the improved standard parameterization kernels can outperform those stemming from an NTK parameterization. We release code implementing this improved standard parameterization as part of the Neural Tangents library at https://github.com/google/neural-tangents.
Neural Tangents: Fast and Easy Infinite Neural Networks in Python
Dec 05, 2019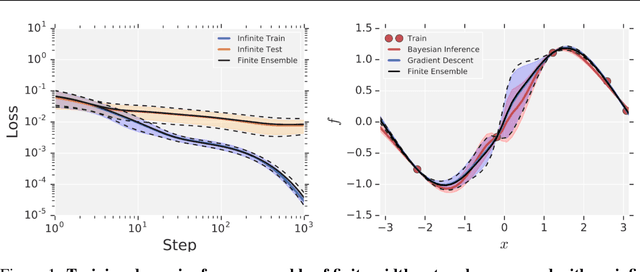
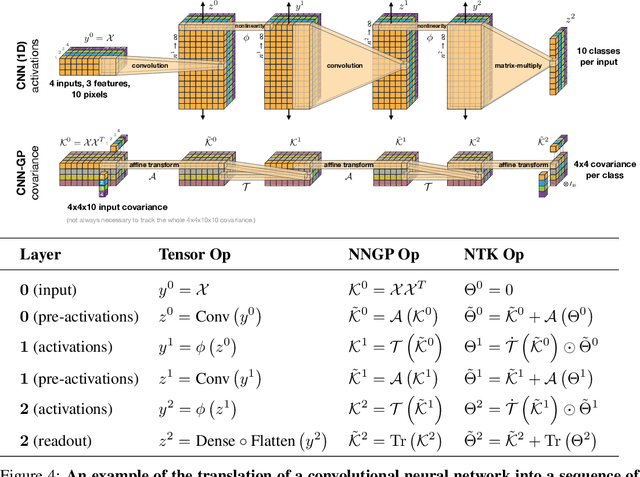
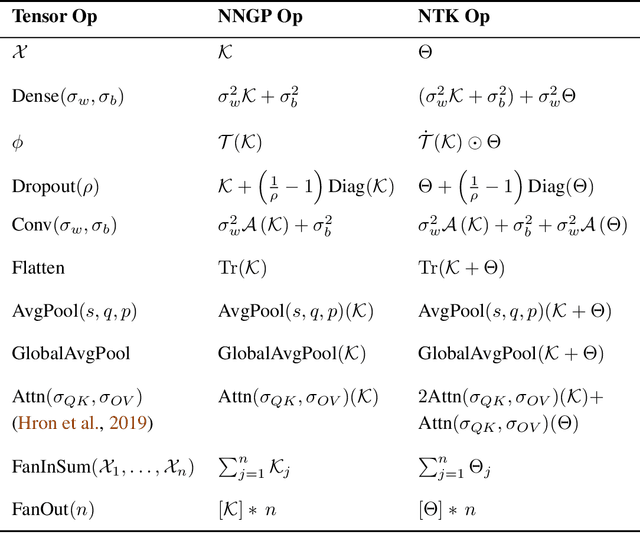
Neural Tangents is a library designed to enable research into infinite-width neural networks. It provides a high-level API for specifying complex and hierarchical neural network architectures. These networks can then be trained and evaluated either at finite-width as usual or in their infinite-width limit. Infinite-width networks can be trained analytically using exact Bayesian inference or using gradient descent via the Neural Tangent Kernel. Additionally, Neural Tangents provides tools to study gradient descent training dynamics of wide but finite networks in either function space or weight space. The entire library runs out-of-the-box on CPU, GPU, or TPU. All computations can be automatically distributed over multiple accelerators with near-linear scaling in the number of devices. Neural Tangents is available at www.github.com/google/neural-tangents. We also provide an accompanying interactive Colab notebook.
Bayesian Convolutional Neural Networks with Many Channels are Gaussian Processes
Oct 11, 2018

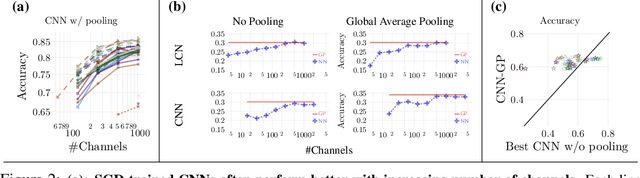
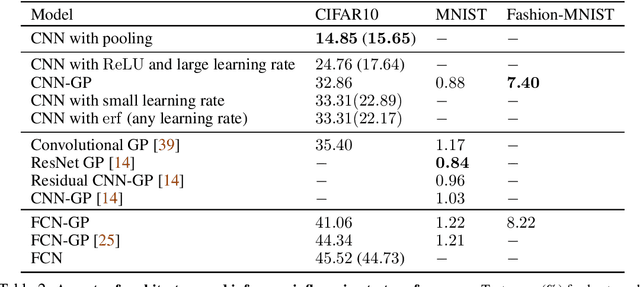
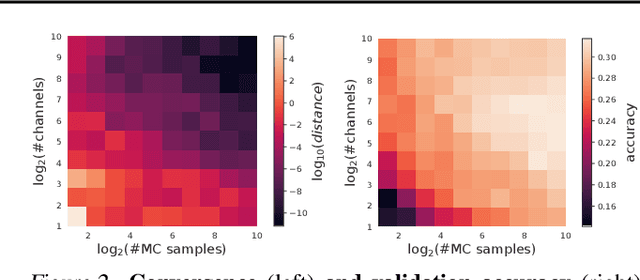
There is a previously identified equivalence between wide fully connected neural networks (FCNs) and Gaussian processes (GPs). This equivalence enables, for instance, test set predictions that would have resulted from a fully Bayesian, infinitely wide trained FCN to be computed without ever instantiating the FCN, but by instead evaluating the corresponding GP. In this work, we derive an analogous equivalence for multi-layer convolutional neural networks (CNNs) both with and without pooling layers, and achieve state of the art results on CIFAR10 for GPs without trainable kernels. We also introduce a Monte Carlo method to estimate the GP corresponding to a given neural network architecture, even in cases where the analytic form has too many terms to be computationally feasible. Surprisingly, in the absence of pooling layers, the GPs corresponding to CNNs with and without weight sharing are identical. As a consequence, translation equivariance in finite-channel CNNs trained with stochastic gradient descent (SGD) has no corresponding property in the Bayesian treatment of the infinite channel limit - a qualitative difference between the two regimes that is not present in the FCN case. We confirm experimentally, that while in some scenarios the performance of SGD-trained finite CNNs approaches that of the corresponding GPs as the channel count increases, with careful tuning SGD-trained CNNs can significantly outperform their corresponding GPs, suggesting advantages from SGD training compared to fully Bayesian parameter estimation.
Sensitivity and Generalization in Neural Networks: an Empirical Study
Jun 18, 2018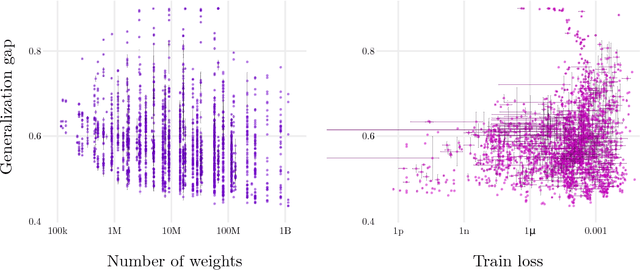
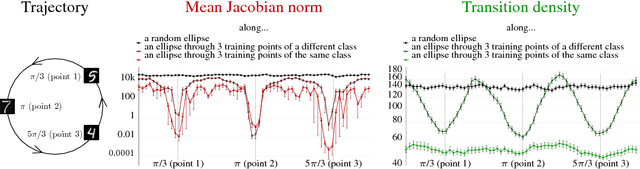

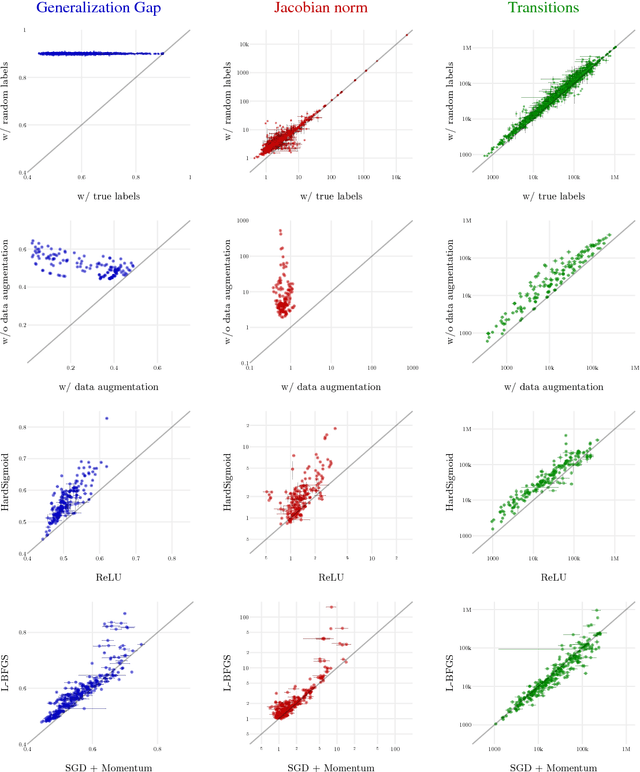
In practice it is often found that large over-parameterized neural networks generalize better than their smaller counterparts, an observation that appears to conflict with classical notions of function complexity, which typically favor smaller models. In this work, we investigate this tension between complexity and generalization through an extensive empirical exploration of two natural metrics of complexity related to sensitivity to input perturbations. Our experiments survey thousands of models with various fully-connected architectures, optimizers, and other hyper-parameters, as well as four different image classification datasets. We find that trained neural networks are more robust to input perturbations in the vicinity of the training data manifold, as measured by the norm of the input-output Jacobian of the network, and that it correlates well with generalization. We further establish that factors associated with poor generalization $-$ such as full-batch training or using random labels $-$ correspond to lower robustness, while factors associated with good generalization $-$ such as data augmentation and ReLU non-linearities $-$ give rise to more robust functions. Finally, we demonstrate how the input-output Jacobian norm can be predictive of generalization at the level of individual test points.
Iterative Refinement for Machine Translation
Apr 13, 2018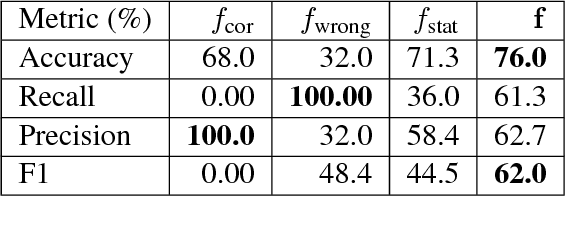
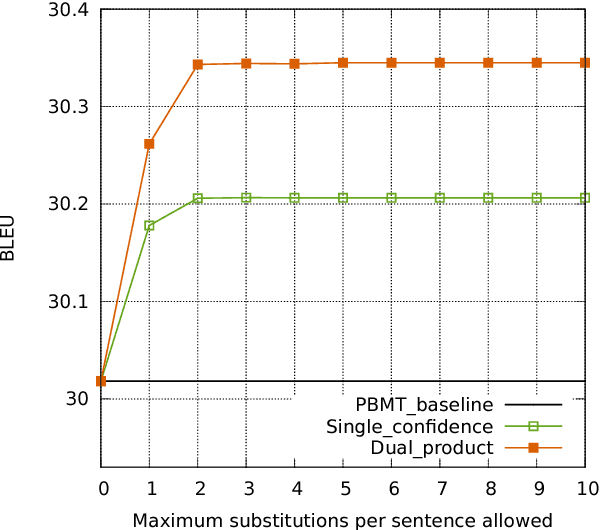
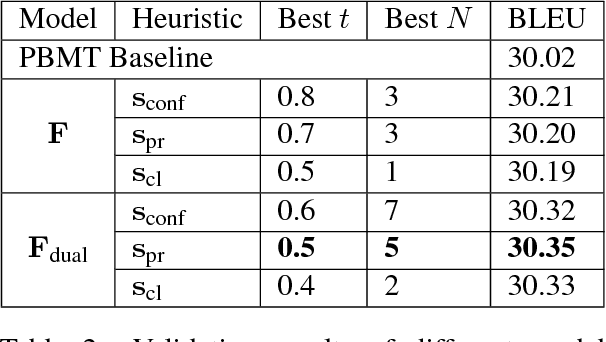
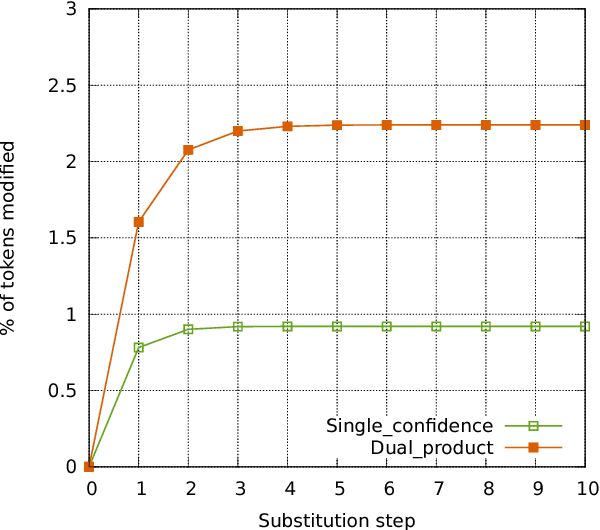
Existing machine translation decoding algorithms generate translations in a strictly monotonic fashion and never revisit previous decisions. As a result, earlier mistakes cannot be corrected at a later stage. In this paper, we present a translation scheme that starts from an initial guess and then makes iterative improvements that may revisit previous decisions. We parameterize our model as a convolutional neural network that predicts discrete substitutions to an existing translation based on an attention mechanism over both the source sentence as well as the current translation output. By making less than one modification per sentence, we improve the output of a phrase-based translation system by up to 0.4 BLEU on WMT15 German-English translation.
Deep Neural Networks as Gaussian Processes
Mar 03, 2018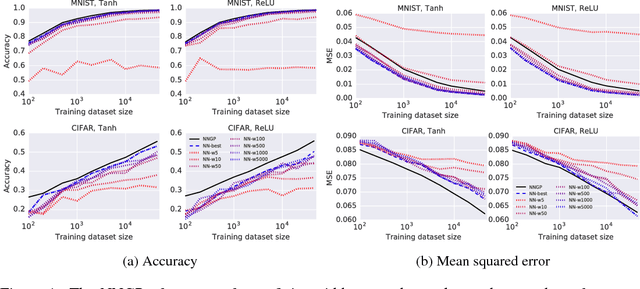
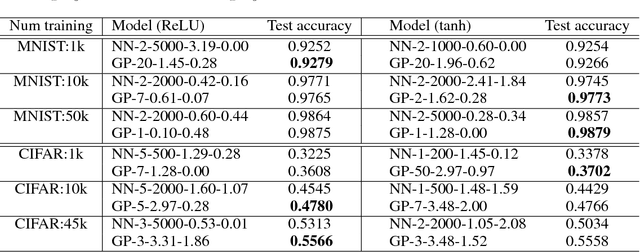
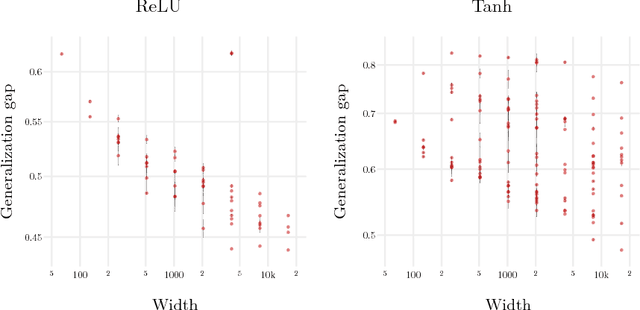
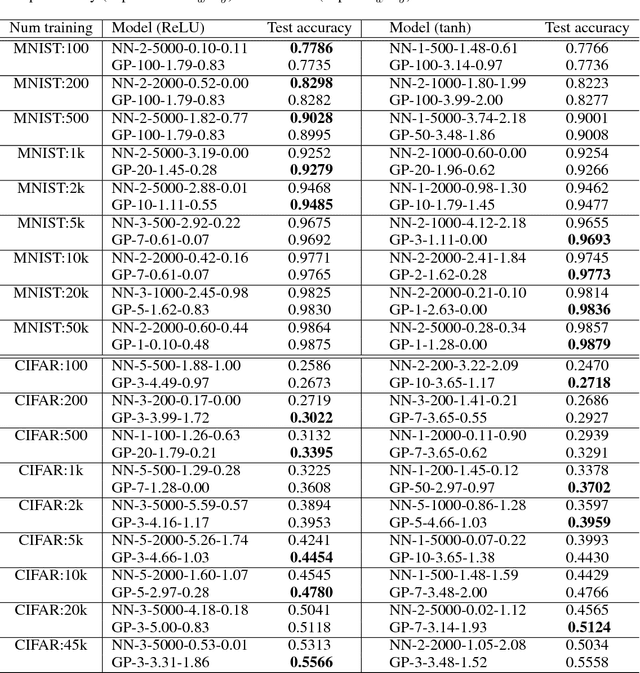
It has long been known that a single-layer fully-connected neural network with an i.i.d. prior over its parameters is equivalent to a Gaussian process (GP), in the limit of infinite network width. This correspondence enables exact Bayesian inference for infinite width neural networks on regression tasks by means of evaluating the corresponding GP. Recently, kernel functions which mimic multi-layer random neural networks have been developed, but only outside of a Bayesian framework. As such, previous work has not identified that these kernels can be used as covariance functions for GPs and allow fully Bayesian prediction with a deep neural network. In this work, we derive the exact equivalence between infinitely wide deep networks and GPs. We further develop a computationally efficient pipeline to compute the covariance function for these GPs. We then use the resulting GPs to perform Bayesian inference for wide deep neural networks on MNIST and CIFAR-10. We observe that trained neural network accuracy approaches that of the corresponding GP with increasing layer width, and that the GP uncertainty is strongly correlated with trained network prediction error. We further find that test performance increases as finite-width trained networks are made wider and more similar to a GP, and thus that GP predictions typically outperform those of finite-width networks. Finally we connect the performance of these GPs to the recent theory of signal propagation in random neural networks.
Improving the Neural Algorithm of Artistic Style
May 15, 2016



In this work we investigate different avenues of improving the Neural Algorithm of Artistic Style (by Leon A. Gatys, Alexander S. Ecker and Matthias Bethge, arXiv:1508.06576). While showing great results when transferring homogeneous and repetitive patterns, the original style representation often fails to capture more complex properties, like having separate styles of foreground and background. This leads to visual artifacts and undesirable textures appearing in unexpected regions when performing style transfer. We tackle this issue with a variety of approaches, mostly by modifying the style representation in order for it to capture more information and impose a tighter constraint on the style transfer result. In our experiments, we subjectively evaluate our best method as producing from barely noticeable to significant improvements in the quality of style transfer.