 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA clustering and graph deep learning-based framework for COVID-19 drug repurposing
Jun 24, 2023



Drug repurposing (or repositioning) is the process of finding new therapeutic uses for drugs already approved by drug regulatory authorities (e.g., the Food and Drug Administration (FDA) and Therapeutic Goods Administration (TGA)) for other diseases. This involves analyzing the interactions between different biological entities, such as drug targets (genes/proteins and biological pathways) and drug properties, to discover novel drug-target or drug-disease relations. Artificial intelligence methods such as machine learning and deep learning have successfully analyzed complex heterogeneous data in the biomedical domain and have also been used for drug repurposing. This study presents a novel unsupervised machine learning framework that utilizes a graph-based autoencoder for multi-feature type clustering on heterogeneous drug data. The dataset consists of 438 drugs, of which 224 are under clinical trials for COVID-19 (category A). The rest are systematically filtered to ensure the safety and efficacy of the treatment (category B). The framework solely relies on reported drug data, including its pharmacological properties, chemical/physical properties, interaction with the host, and efficacy in different publicly available COVID-19 assays. Our machine-learning framework reveals three clusters of interest and provides recommendations featuring the top 15 drugs for COVID-19 drug repurposing, which were shortlisted based on the predicted clusters that were dominated by category A drugs. The anti-COVID efficacy of the drugs should be verified by experimental studies. Our framework can be extended to support other datasets and drug repurposing studies, given open-source code and data availability.
An analysis of vaccine-related sentiments from development to deployment of COVID-19 vaccines
Jun 23, 2023Anti-vaccine sentiments have been well-known and reported throughout the history of viral outbreaks and vaccination programmes. The COVID-19 pandemic had fear and uncertainty about vaccines which has been well expressed on social media platforms such as Twitter. We analyse Twitter sentiments from the beginning of the COVID-19 pandemic and study the public behaviour during the planning, development and deployment of vaccines expressed in tweets worldwide using a sentiment analysis framework via deep learning models. In this way, we provide visualisation and analysis of anti-vaccine sentiments over the course of the COVID-19 pandemic. Our results show a link between the number of tweets, the number of cases, and the change in sentiment polarity scores during major waves of COVID-19 cases. We also found that the first half of the pandemic had drastic changes in the sentiment polarity scores that later stabilised which implies that the vaccine rollout had an impact on the nature of discussions on social media.
Multi-Modal Deep Learning for Credit Rating Prediction Using Text and Numerical Data Streams
Apr 21, 2023



Knowing which factors are significant in credit rating assignment leads to better decision-making. However, the focus of the literature thus far has been mostly on structured data, and fewer studies have addressed unstructured or multi-modal datasets. In this paper, we present an analysis of the most effective architectures for the fusion of deep learning models for the prediction of company credit rating classes, by using structured and unstructured datasets of different types. In these models, we tested different combinations of fusion strategies with different deep learning models, including CNN, LSTM, GRU, and BERT. We studied data fusion strategies in terms of level (including early and intermediate fusion) and techniques (including concatenation and cross-attention). Our results show that a CNN-based multi-modal model with two fusion strategies outperformed other multi-modal techniques. In addition, by comparing simple architectures with more complex ones, we found that more sophisticated deep learning models do not necessarily produce the highest performance; however, if attention-based models are producing the best results, cross-attention is necessary as a fusion strategy. Finally, our comparison of rating agencies on short-, medium-, and long-term performance shows that Moody's credit ratings outperform those of other agencies like Standard & Poor's and Fitch Ratings.
A review of ensemble learning and data augmentation models for class imbalanced problems: combination, implementation and evaluation
Apr 06, 2023



Class imbalance (CI) in classification problems arises when the number of observations belonging to one class is lower than the other classes. Ensemble learning that combines multiple models to obtain a robust model has been prominently used with data augmentation methods to address class imbalance problems. In the last decade, a number of strategies have been added to enhance ensemble learning and data augmentation methods, along with new methods such as generative adversarial networks (GANs). A combination of these has been applied in many studies, but the true rank of different combinations would require a computational review. In this paper, we present a computational review to evaluate data augmentation and ensemble learning methods used to address prominent benchmark CI problems. We propose a general framework that evaluates 10 data augmentation and 10 ensemble learning methods for CI problems. Our objective was to identify the most effective combination for improving classification performance on imbalanced datasets. The results indicate that combinations of data augmentation methods with ensemble learning can significantly improve classification performance on imbalanced datasets. These findings have important implications for the development of more effective approaches for handling imbalanced datasets in machine learning applications.
Bayesian neural networks via MCMC: a Python-based tutorial
Apr 02, 2023



Bayesian inference provides a methodology for parameter estimation and uncertainty quantification in machine learning and deep learning methods. Variational inference and Markov Chain Monte-Carlo (MCMC) sampling techniques are used to implement Bayesian inference. In the past three decades, MCMC methods have faced a number of challenges in being adapted to larger models (such as in deep learning) and big data problems. Advanced proposals that incorporate gradients, such as a Langevin proposal distribution, provide a means to address some of the limitations of MCMC sampling for Bayesian neural networks. Furthermore, MCMC methods have typically been constrained to use by statisticians and are still not prominent among deep learning researchers. We present a tutorial for MCMC methods that covers simple Bayesian linear and logistic models, and Bayesian neural networks. The aim of this tutorial is to bridge the gap between theory and implementation via coding, given a general sparsity of libraries and tutorials to this end. This tutorial provides code in Python with data and instructions that enable their use and extension. We provide results for some benchmark problems showing the strengths and weaknesses of implementing the respective Bayesian models via MCMC. We highlight the challenges in sampling multi-modal posterior distributions in particular for the case of Bayesian neural networks, and the need for further improvement of convergence diagnosis.
An evaluation of Google Translate for Sanskrit to English translation via sentiment and semantic analysis
Feb 28, 2023Google Translate has been prominent for language translation; however, limited work has been done in evaluating the quality of translation when compared to human experts. Sanskrit one of the oldest written languages in the world. In 2022, the Sanskrit language was added to the Google Translate engine. Sanskrit is known as the mother of languages such as Hindi and an ancient source of the Indo-European group of languages. Sanskrit is the original language for sacred Hindu texts such as the Bhagavad Gita. In this study, we present a framework that evaluates the Google Translate for Sanskrit using the Bhagavad Gita. We first publish a translation of the Bhagavad Gita in Sanskrit using Google Translate. Our framework then compares Google Translate version of Bhagavad Gita with expert translations using sentiment and semantic analysis via BERT-based language models. Our results indicate that in terms of sentiment and semantic analysis, there is low level of similarity in selected verses of Google Translate when compared to expert translations. In the qualitative evaluation, we find that Google translate is unsuitable for translation of certain Sanskrit words and phrases due to its poetic nature, contextual significance, metaphor and imagery. The mistranslations are not surprising since the Bhagavad Gita is known as a difficult text not only to translate, but also to interpret since it relies on contextual, philosophical and historical information. Our framework lays the foundation for automatic evaluation of other languages by Google Translate
Deep learning for COVID-19 topic modelling via Twitter: Alpha, Delta and Omicron
Feb 28, 2023Topic modelling with innovative deep learning methods has gained interest for a wide range of applications that includes COVID-19. Topic modelling can provide, psychological, social and cultural insights for understanding human behaviour in extreme events such as the COVID-19 pandemic. In this paper, we use prominent deep learning-based language models for COVID-19 topic modelling taking into account data from emergence (Alpha) to the Omicron variant. We apply topic modeling to review the public behaviour across the first, second and third waves based on Twitter dataset from India. Our results show that the topics extracted for the subsequent waves had certain overlapping themes such as covers governance, vaccination, and pandemic management while novel issues aroused in political, social and economic situation during COVID-19 pandemic. We also found a strong correlation of the major topics qualitatively to news media prevalent at the respective time period. Hence, our framework has the potential to capture major issues arising during different phases of the COVID-19 pandemic which can be extended to other countries and regions.
Reef-insight: A framework for reef habitat mapping with clustering methods via remote sensing
Jan 26, 2023



Environmental damage has been of much concern, particularly coastal areas and the oceans given climate change and drastic effects of pollution and extreme climate events. Our present day analytical capabilities along with the advancements in information acquisition techniques such as remote sensing can be utilized for the management and study of coral reef ecosystems. In this paper, we present Reef-insight, an unsupervised machine learning framework that features advanced clustering methods and remote sensing for reef community mapping. Our framework compares different clustering methods to evaluate them for reef community mapping using remote sensing data. We evaluate four major clustering approaches such as k- means, hierarchical clustering, Gaussian mixture model, and density-based clustering based on qualitative and visual assessment. We utilise remote sensing data featuring Heron reef island region in the Great Barrier Reef of Australia. Our results indicate that clustering methods using remote sensing data can well identify benthic and geomorphic clusters that are found in reefs when compared to other studies. Our results indicate that Reef-insight can generate detailed reef community maps outlining distinct reef habitats and has the potential to enable further insights for reef restoration projects. We release our framework as open source software to enable its extension to different parts of the world
Recursive deep learning framework for forecasting the decadal world economic outlook
Jan 25, 2023Gross domestic product (GDP) is the most widely used indicator in macroeconomics and the main tool for measuring a country's economic ouput. Due to the diversity and complexity of the world economy, a wide range of models have been used, but there are challenges in making decadal GDP forecasts given unexpected changes such as pandemics and wars. Deep learning models are well suited for modeling temporal sequences have been applied for time series forecasting. In this paper, we develop a deep learning framework to forecast the GDP growth rate of the world economy over a decade. We use Penn World Table as the source of our data, taking data from 1980 to 2019, across 13 countries, such as Australia, China, India, the United States and so on. We test multiple deep learning models, LSTM, BD-LSTM, ED-LSTM and CNN, and compared their results with the traditional time series model (ARIMA,VAR). Our results indicate that ED-LSTM is the best performing model. We present a recursive deep learning framework to predict the GDP growth rate in the next ten years. We predict that most countries will experience economic growth slowdown, stagnation or even recession within five years; only China, France and India are predicted to experience stable, or increasing, GDP growth.
Evolutionary bagged ensemble learning
Aug 04, 2022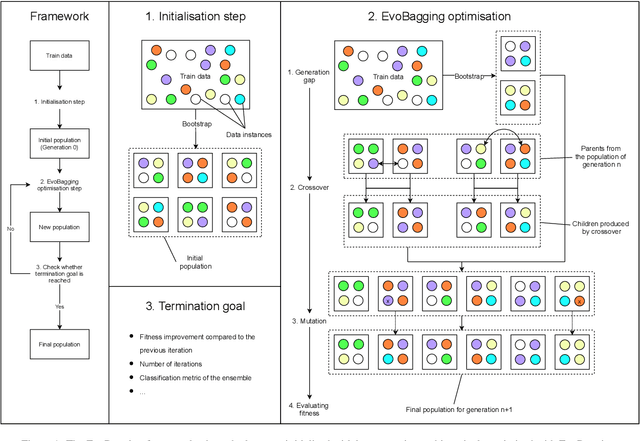

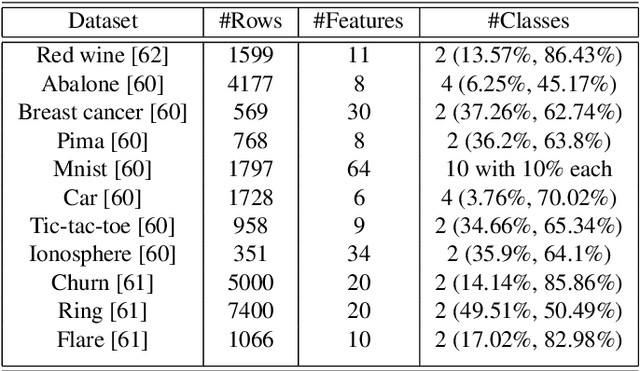
Ensemble learning has gained success in machine learning with major advantages over other learning methods. Bagging is a prominent ensemble learning method that creates subgroups of data, known as bags, that are trained by individual machine learning methods such as decision trees. Random forest is a prominent example of bagging with additional features in the learning process. \textcolor{black}{A limitation of bagging is high bias (model under-fitting) in the aggregated prediction when the individual learners have high biases.} Evolutionary algorithms have been prominent for optimisation problems and also been used for machine learning. Evolutionary algorithms are gradient-free methods with a population of candidate solutions that maintain diversity for creating new solutions. In conventional bagged ensemble learning, the bags are created once and the content, in terms of the training examples, is fixed over the learning process. In our paper, we propose evolutionary bagged ensemble learning, where we utilise evolutionary algorithms to evolve the content of the bags in order to enhance the ensemble by providing diversity in the bags iteratively. The results show that our evolutionary ensemble bagging method outperforms conventional ensemble methods (bagging and random forests) for several benchmark datasets under certain constraints. Evolutionary bagging can inherently sustain a diverse set of bags without sacrificing any data.