 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Reasoning Using Dynamics-Aware Models
Feb 20, 2021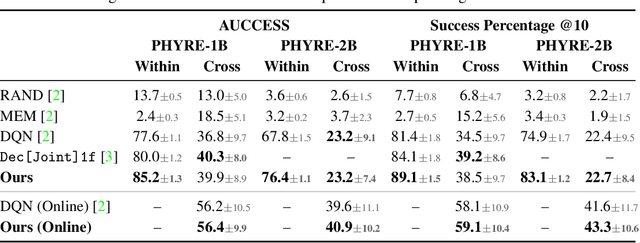
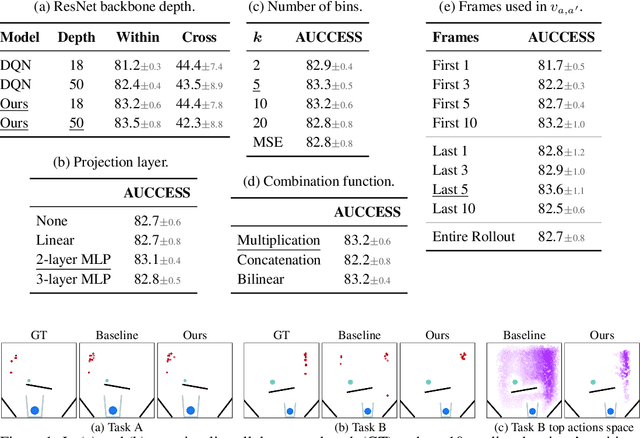
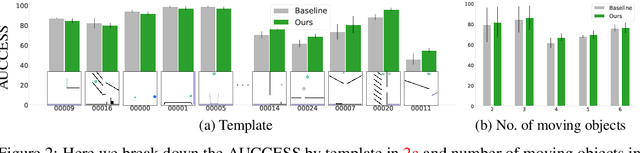
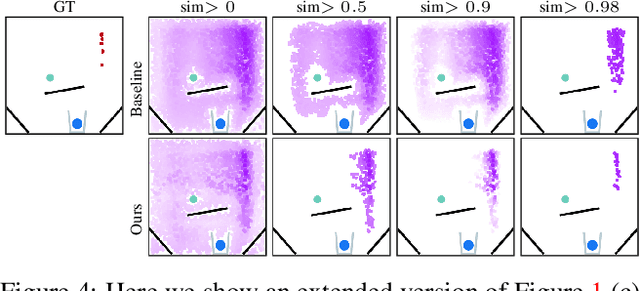
A common approach to solving physical-reasoning tasks is to train a value learner on example tasks. A limitation of such an approach is it requires learning about object dynamics solely from reward values assigned to the final state of a rollout of the environment. This study aims to address this limitation by augmenting the reward value with additional supervisory signals about object dynamics. Specifically,we define a distance measure between the trajectory of two target objects, and use this distance measure to characterize the similarity of two environment rollouts.We train the model to correctly rank rollouts according to this measure in addition to predicting the correct reward. Empirically, we find that this approach leads to substantial performance improvements on the PHYRE benchmark for physical reasoning: our approach obtains a new state-of-the-art on that benchmark.
Self-Supervised Pretraining of 3D Features on any Point-Cloud
Jan 07, 2021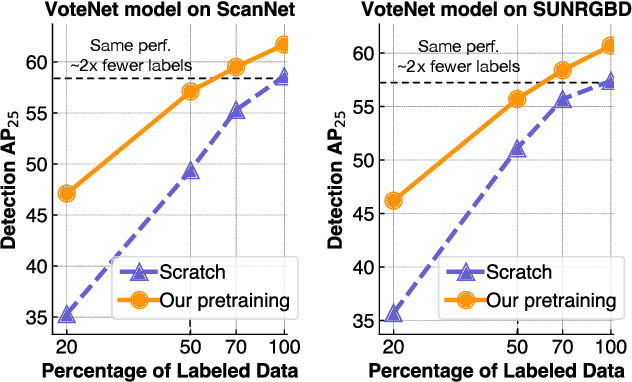
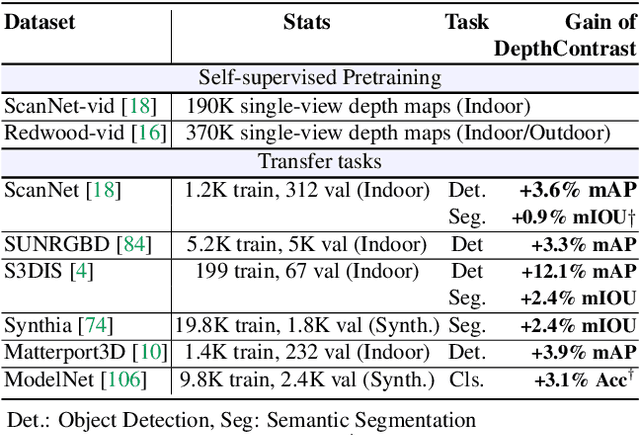


Pretraining on large labeled datasets is a prerequisite to achieve good performance in many computer vision tasks like 2D object recognition, video classification etc. However, pretraining is not widely used for 3D recognition tasks where state-of-the-art methods train models from scratch. A primary reason is the lack of large annotated datasets because 3D data is both difficult to acquire and time consuming to label. We present a simple self-supervised pertaining method that can work with any 3D data - single or multiview, indoor or outdoor, acquired by varied sensors, without 3D registration. We pretrain standard point cloud and voxel based model architectures, and show that joint pretraining further improves performance. We evaluate our models on 9 benchmarks for object detection, semantic segmentation, and object classification, where they achieve state-of-the-art results and can outperform supervised pretraining. We set a new state-of-the-art for object detection on ScanNet (69.0% mAP) and SUNRGBD (63.5% mAP). Our pretrained models are label efficient and improve performance for classes with few examples.
Forward Prediction for Physical Reasoning
Jun 18, 2020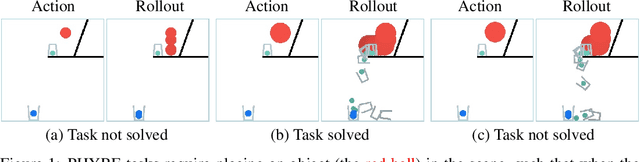

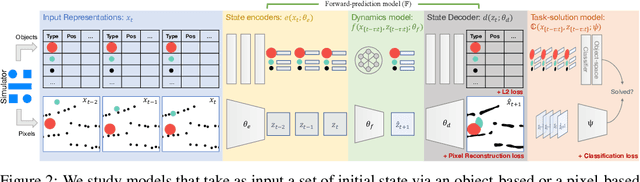
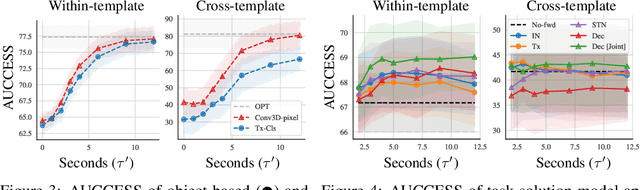
Physical reasoning requires forward prediction: the ability to forecast what will happen next given some initial world state. We study the performance of state-of-the-art forward-prediction models in complex physical-reasoning tasks. We do so by incorporating models that operate on object or pixel-based representations of the world, into simple physical-reasoning agents. We find that forward-prediction models improve the performance of physical-reasoning agents, particularly on complex tasks that involve many objects. However, we also find that these improvements are contingent on the training tasks being similar to the test tasks, and that generalization to different tasks is more challenging. Surprisingly, we observe that forward predictors with better pixel accuracy do not necessarily lead to better physical-reasoning performance. Nevertheless, our best models set a new state-of-the-art on the PHYRE benchmark for physical reasoning.
Video Understanding as Machine Translation
Jun 12, 2020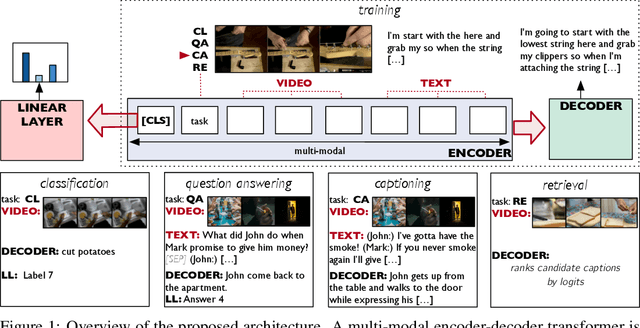
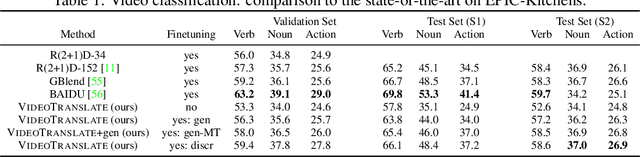
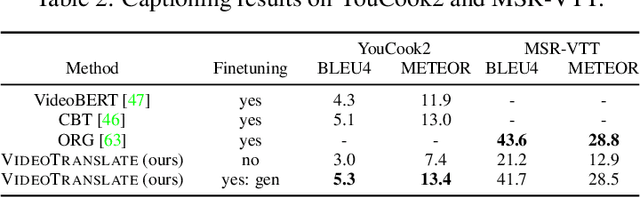

With the advent of large-scale multimodal video datasets, especially sequences with audio or transcribed speech, there has been a growing interest in self-supervised learning of video representations. Most prior work formulates the objective as a contrastive metric learning problem between the modalities. To enable effective learning, however, these strategies require a careful selection of positive and negative samples often combined with hand-designed curriculum policies. In this work we remove the need for negative sampling by taking a generative modeling approach that poses the objective as a translation problem between modalities. Such a formulation allows us to tackle a wide variety of downstream video understanding tasks by means of a single unified framework, without the need for large batches of negative samples common in contrastive metric learning. We experiment with the large-scale HowTo100M dataset for training, and report performance gains over the state-of-the-art on several downstream tasks including video classification (EPIC-Kitchens), question answering (TVQA), captioning (TVC, YouCook2, and MSR-VTT), and text-based clip retrieval (YouCook2 and MSR-VTT).
Are we asking the right questions in MovieQA?
Nov 08, 2019
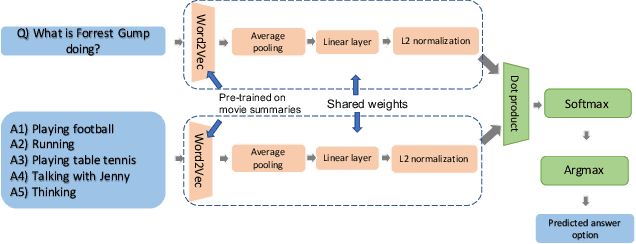

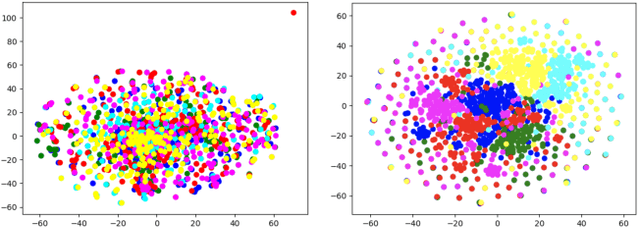
Joint vision and language tasks like visual question answering are fascinating because they explore high-level understanding, but at the same time, can be more prone to language biases. In this paper, we explore the biases in the MovieQA dataset and propose a strikingly simple model which can exploit them. We find that using the right word embedding is of utmost importance. By using an appropriately trained word embedding, about half the Question-Answers (QAs) can be answered by looking at the questions and answers alone, completely ignoring narrative context from video clips, subtitles, and movie scripts. Compared to the best published papers on the leaderboard, our simple question + answer only model improves accuracy by 5% for video + subtitle category, 5% for subtitle, 15% for DVS and 6% higher for scripts.
CATER: A diagnostic dataset for Compositional Actions and TEmporal Reasoning
Oct 10, 2019
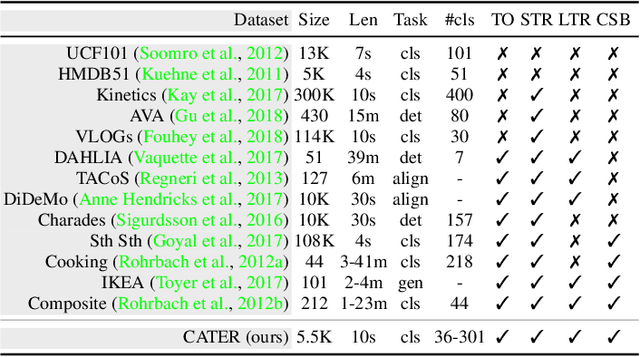
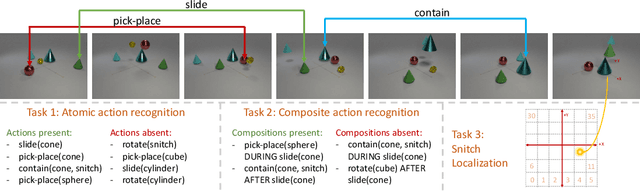
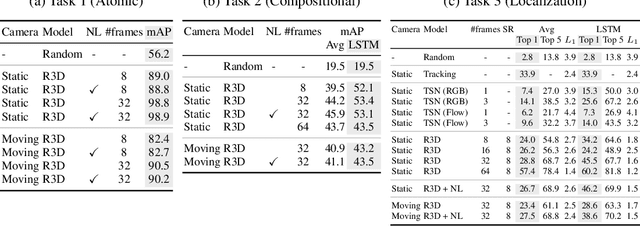
Computer vision has undergone a dramatic revolution in performance, driven in large part through deep features trained on large-scale supervised datasets. However, much of these improvements have focused on static image analysis; video understanding has seen rather modest improvements. Even though new datasets and spatiotemporal models have been proposed, simple frame-by-frame classification methods often still remain competitive. We posit that current video datasets are plagued with implicit biases over scene and object structure that can dwarf variations in temporal structure. In this work, we build a video dataset with fully observable and controllable object and scene bias, and which truly requires spatiotemporal understanding in order to be solved. Our dataset, named CATER, is rendered synthetically using a library of standard 3D objects, and tests the ability to recognize compositions of object movements that require long-term reasoning. In addition to being a challenging dataset, CATER also provides a plethora of diagnostic tools to analyze modern spatiotemporal video architectures by being completely observable and controllable. Using CATER, we provide insights into some of the most recent state of the art deep video architectures.
MetaPix: Few-Shot Video Retargeting
Oct 10, 2019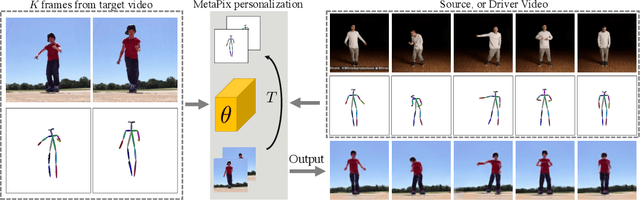
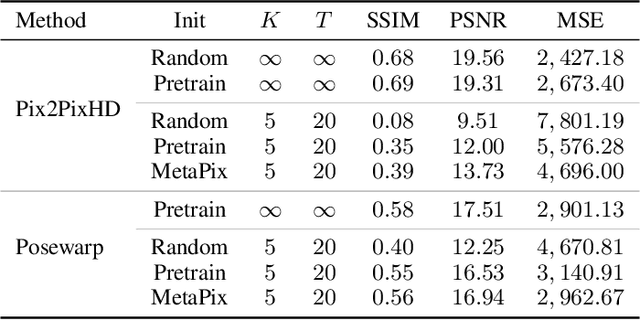
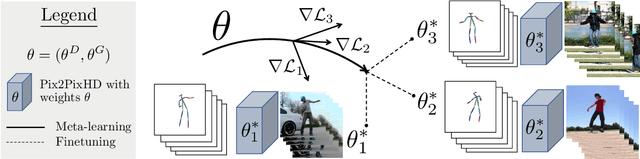

We address the task of unsupervised retargeting of human actions from one video to another. We consider the challenging setting where only a few frames of the target is available. The core of our approach is a conditional generative model that can transcode input skeletal poses (automatically extracted with an off-the-shelf pose estimator) to output target frames. However, it is challenging to build a universal transcoder because humans can appear wildly different due to clothing and background scene geometry. Instead, we learn to adapt - or personalize - a universal generator to the particular human and background in the target. To do so, we make use of meta-learning to discover effective strategies for on-the-fly personalization. One significant benefit of meta-learning is that the personalized transcoder naturally enforces temporal coherence across its generated frames; all frames contain consistent clothing and background geometry of the target. We experiment on in-the-wild internet videos and images and show our approach improves over widely-used baselines for the task.
DistInit: Learning Video Representations without a Single Labeled Video
Jan 26, 2019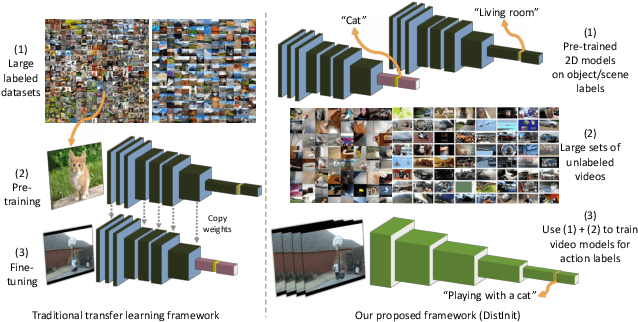
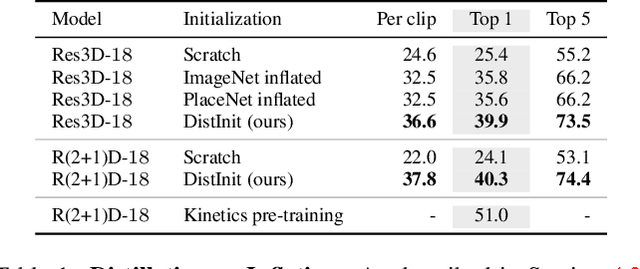
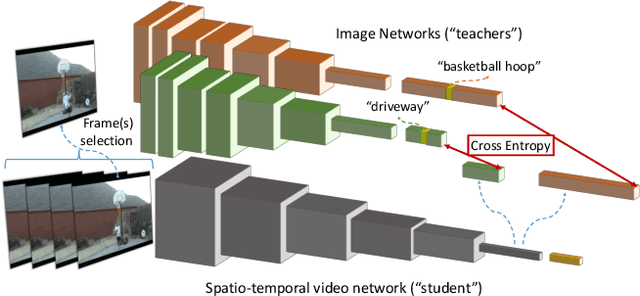

Video recognition models have progressed significantly over the past few years, evolving from shallow classifiers trained on hand-crafted features to deep spatiotemporal networks. However, labeled video data required to train such models has not been able to keep up with the ever increasing depth and sophistication of these networks. In this work we propose an alternative approach to learning video representations that requires no semantically labeled videos, and instead leverages the years of effort in collecting and labeling large and clean still-image datasets. We do so by using state-of-the-art models pre-trained on image datasets as "teachers" to train video models in a distillation framework. We demonstrate that our method learns truly spatiotemporal features, despite being trained only using supervision from still-image networks. Moreover, it learns good representations across different input modalities, using completely uncurated raw video data sources and with different 2D teacher models. Our method obtains strong transfer performance, outperforming standard techniques for bootstrapping video architectures from image-based models and obtains competitive performance with state-of-the-art approaches for video action recognition.
Video Action Transformer Network
Dec 06, 2018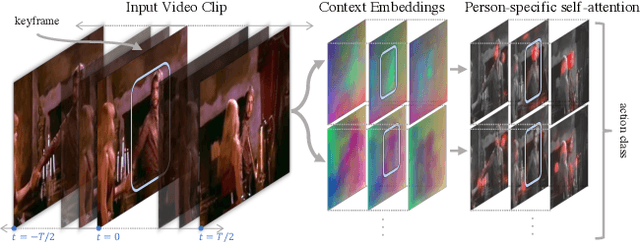
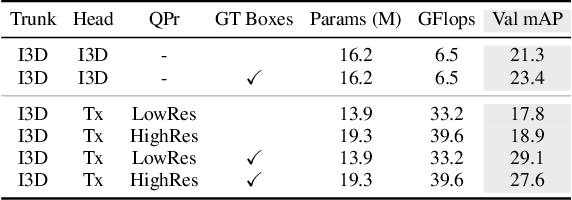
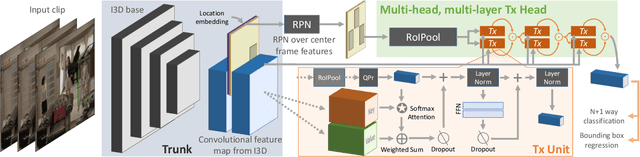

We introduce the Action Transformer model for recognizing and localizing human actions in video clips. We repurpose a Transformer-style architecture to aggregate features from the spatiotemporal context around the person whose actions we are trying to classify. We show that by using high-resolution, person-specific, class-agnostic queries, the model spontaneously learns to track individual people and to pick up on semantic context from the actions of others. Additionally its attention mechanism learns to emphasize hands and faces, which are often crucial to discriminate an action - all without explicit supervision other than boxes and class labels. We train and test our Action Transformer network on the Atomic Visual Actions (AVA) dataset, outperforming the state-of-the-art by a significant margin - more than 7.5% absolute (40% relative) improvement, using only raw RGB frames as input.
A Better Baseline for AVA
Jul 26, 2018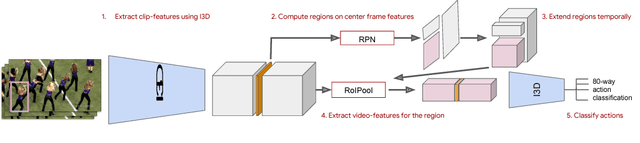
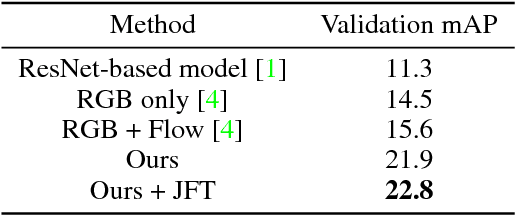
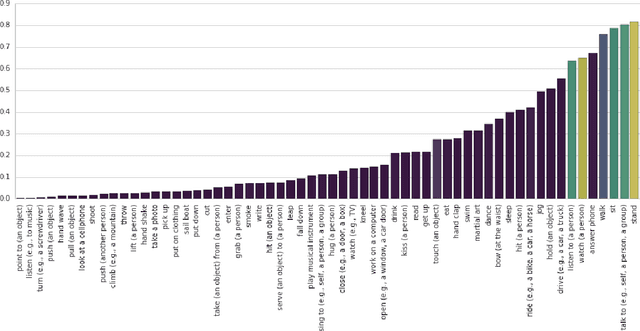

We introduce a simple baseline for action localization on the AVA dataset. The model builds upon the Faster R-CNN bounding box detection framework, adapted to operate on pure spatiotemporal features - in our case produced exclusively by an I3D model pretrained on Kinetics. This model obtains 21.9% average AP on the validation set of AVA v2.1, up from 14.5% for the best RGB spatiotemporal model used in the original AVA paper (which was pretrained on Kinetics and ImageNet), and up from 11.3 of the publicly available baseline using a ResNet101 image feature extractor, that was pretrained on ImageNet. Our final model obtains 22.8%/21.9% mAP on the val/test sets and outperforms all submissions to the AVA challenge at CVPR 2018.