 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Sample Complexity of Sparse Dictionary Learning
Mar 20, 2014In the synthesis model signals are represented as a sparse combinations of atoms from a dictionary. Dictionary learning describes the acquisition process of the underlying dictionary for a given set of training samples. While ideally this would be achieved by optimizing the expectation of the factors over the underlying distribution of the training data, in practice the necessary information about the distribution is not available. Therefore, in real world applications it is achieved by minimizing an empirical average over the available samples. The main goal of this paper is to provide a sample complexity estimate that controls to what extent the empirical average deviates from the cost function. This estimate then provides a suitable estimate to the accuracy of the representation of the learned dictionary. The presented approach exemplifies the general results proposed by the authors in Sample Complexity of Dictionary Learning and other Matrix Factorizations, Gribonval et al. and gives more concrete bounds of the sample complexity of dictionary learning. We cover a variety of sparsity measures employed in the learning procedure.
Local stability and robustness of sparse dictionary learning in the presence of noise
Oct 02, 2012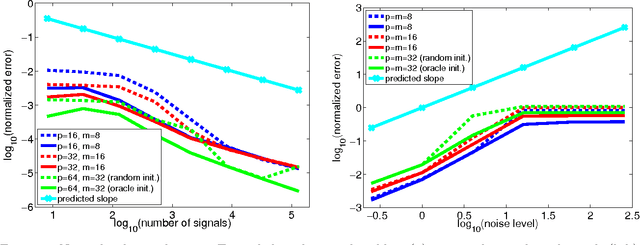
A popular approach within the signal processing and machine learning communities consists in modelling signals as sparse linear combinations of atoms selected from a learned dictionary. While this paradigm has led to numerous empirical successes in various fields ranging from image to audio processing, there have only been a few theoretical arguments supporting these evidences. In particular, sparse coding, or sparse dictionary learning, relies on a non-convex procedure whose local minima have not been fully analyzed yet. In this paper, we consider a probabilistic model of sparse signals, and show that, with high probability, sparse coding admits a local minimum around the reference dictionary generating the signals. Our study takes into account the case of over-complete dictionaries and noisy signals, thus extending previous work limited to noiseless settings and/or under-complete dictionaries. The analysis we conduct is non-asymptotic and makes it possible to understand how the key quantities of the problem, such as the coherence or the level of noise, can scale with respect to the dimension of the signals, the number of atoms, the sparsity and the number of observations.
Structured sparsity through convex optimization
Apr 20, 2012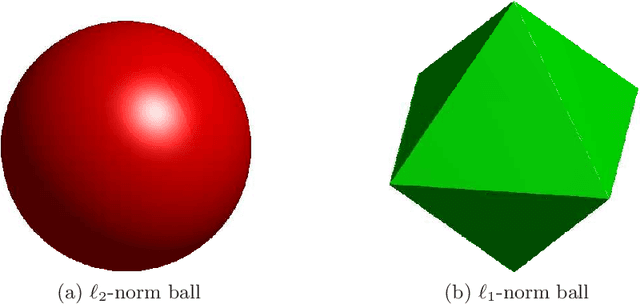
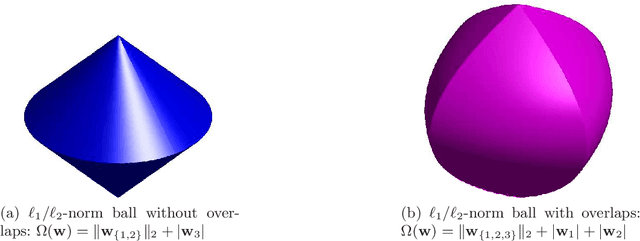
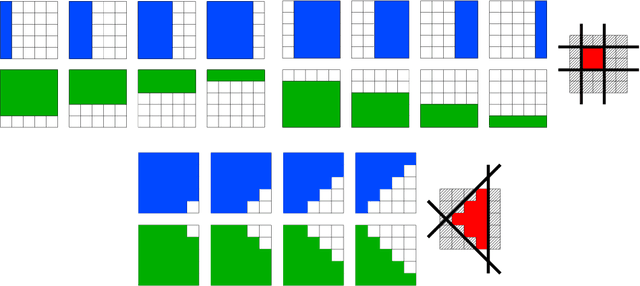
Sparse estimation methods are aimed at using or obtaining parsimonious representations of data or models. While naturally cast as a combinatorial optimization problem, variable or feature selection admits a convex relaxation through the regularization by the $\ell_1$-norm. In this paper, we consider situations where we are not only interested in sparsity, but where some structural prior knowledge is available as well. We show that the $\ell_1$-norm can then be extended to structured norms built on either disjoint or overlapping groups of variables, leading to a flexible framework that can deal with various structures. We present applications to unsupervised learning, for structured sparse principal component analysis and hierarchical dictionary learning, and to supervised learning in the context of non-linear variable selection.
Multi-scale Mining of fMRI data with Hierarchical Structured Sparsity
Dec 08, 2011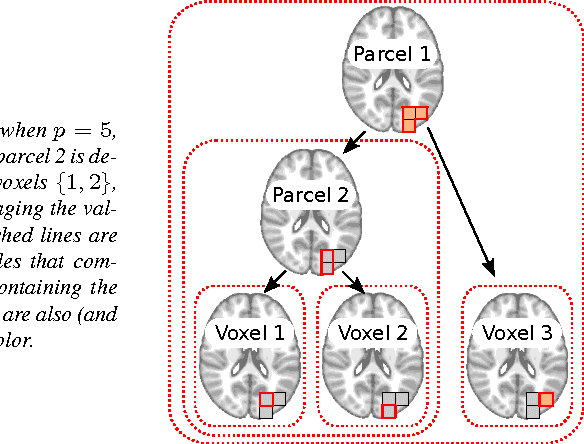
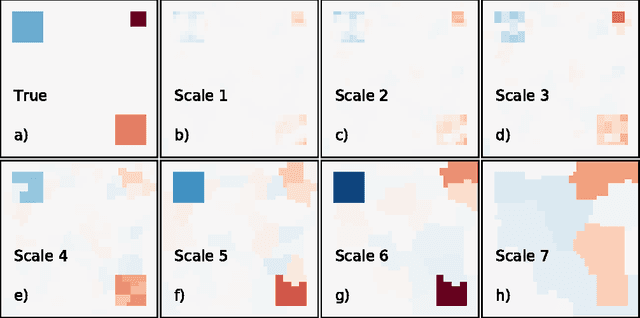
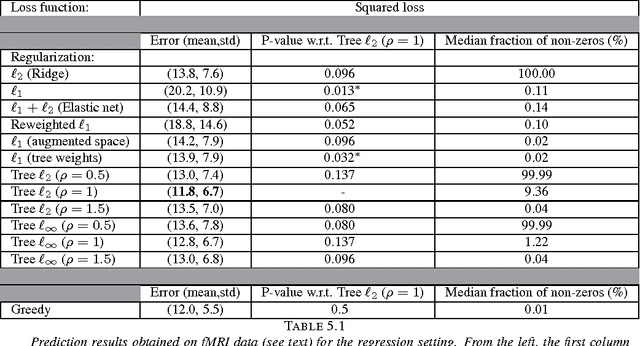
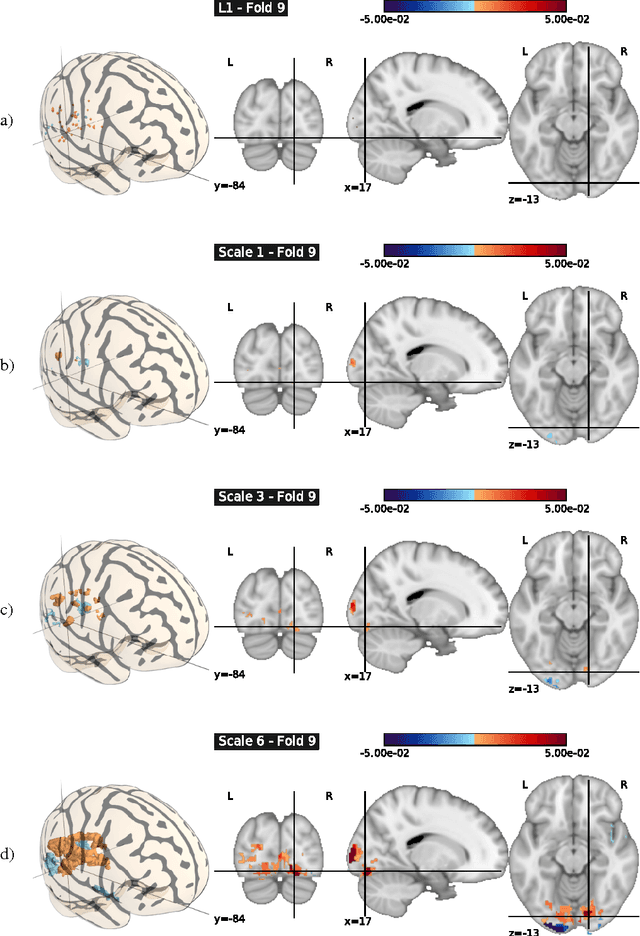
Inverse inference, or "brain reading", is a recent paradigm for analyzing functional magnetic resonance imaging (fMRI) data, based on pattern recognition and statistical learning. By predicting some cognitive variables related to brain activation maps, this approach aims at decoding brain activity. Inverse inference takes into account the multivariate information between voxels and is currently the only way to assess how precisely some cognitive information is encoded by the activity of neural populations within the whole brain. However, it relies on a prediction function that is plagued by the curse of dimensionality, since there are far more features than samples, i.e., more voxels than fMRI volumes. To address this problem, different methods have been proposed, such as, among others, univariate feature selection, feature agglomeration and regularization techniques. In this paper, we consider a sparse hierarchical structured regularization. Specifically, the penalization we use is constructed from a tree that is obtained by spatially-constrained agglomerative clustering. This approach encodes the spatial structure of the data at different scales into the regularization, which makes the overall prediction procedure more robust to inter-subject variability. The regularization used induces the selection of spatially coherent predictive brain regions simultaneously at different scales. We test our algorithm on real data acquired to study the mental representation of objects, and we show that the proposed algorithm not only delineates meaningful brain regions but yields as well better prediction accuracy than reference methods.
Optimization with Sparsity-Inducing Penalties
Nov 22, 2011

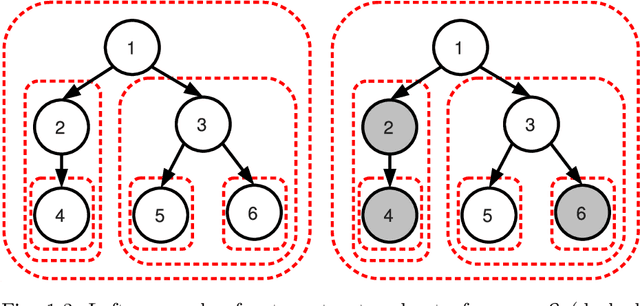
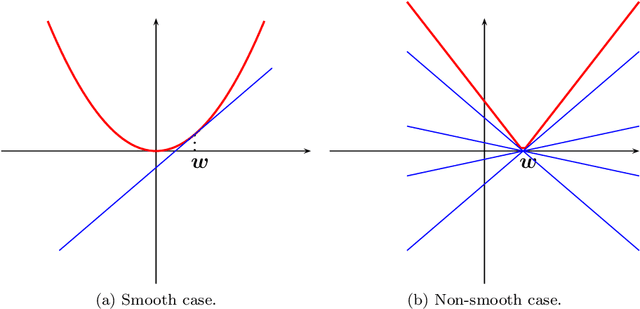
Sparse estimation methods are aimed at using or obtaining parsimonious representations of data or models. They were first dedicated to linear variable selection but numerous extensions have now emerged such as structured sparsity or kernel selection. It turns out that many of the related estimation problems can be cast as convex optimization problems by regularizing the empirical risk with appropriate non-smooth norms. The goal of this paper is to present from a general perspective optimization tools and techniques dedicated to such sparsity-inducing penalties. We cover proximal methods, block-coordinate descent, reweighted $\ell_2$-penalized techniques, working-set and homotopy methods, as well as non-convex formulations and extensions, and provide an extensive set of experiments to compare various algorithms from a computational point of view.
Learning Hierarchical and Topographic Dictionaries with Structured Sparsity
Oct 20, 2011Recent work in signal processing and statistics have focused on defining new regularization functions, which not only induce sparsity of the solution, but also take into account the structure of the problem. We present in this paper a class of convex penalties introduced in the machine learning community, which take the form of a sum of l_2 and l_infinity-norms over groups of variables. They extend the classical group-sparsity regularization in the sense that the groups possibly overlap, allowing more flexibility in the group design. We review efficient optimization methods to deal with the corresponding inverse problems, and their application to the problem of learning dictionaries of natural image patches: On the one hand, dictionary learning has indeed proven effective for various signal processing tasks. On the other hand, structured sparsity provides a natural framework for modeling dependencies between dictionary elements. We thus consider a structured sparse regularization to learn dictionaries embedded in a particular structure, for instance a tree or a two-dimensional grid. In the latter case, the results we obtain are similar to the dictionaries produced by topographic independent component analysis.
Convex and Network Flow Optimization for Structured Sparsity
Sep 16, 2011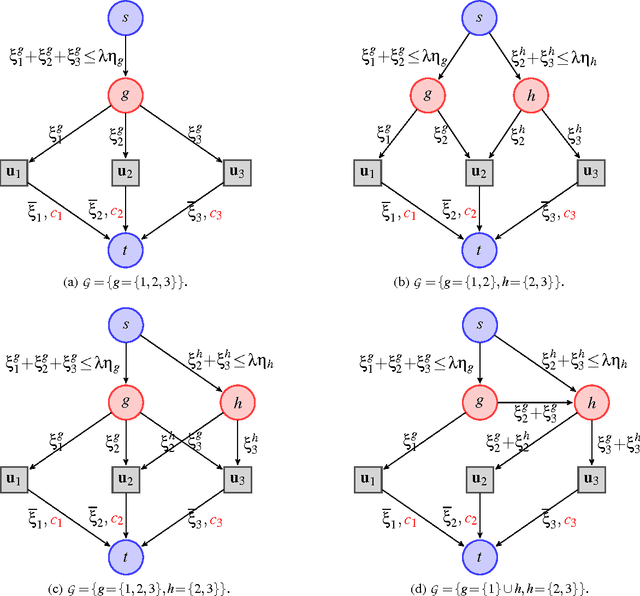
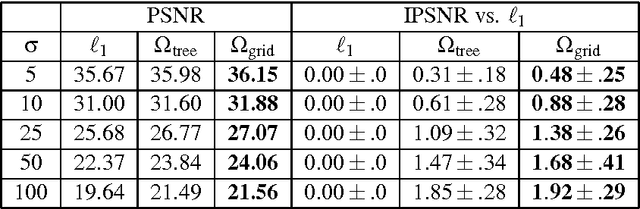
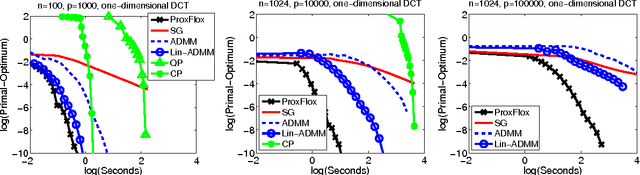
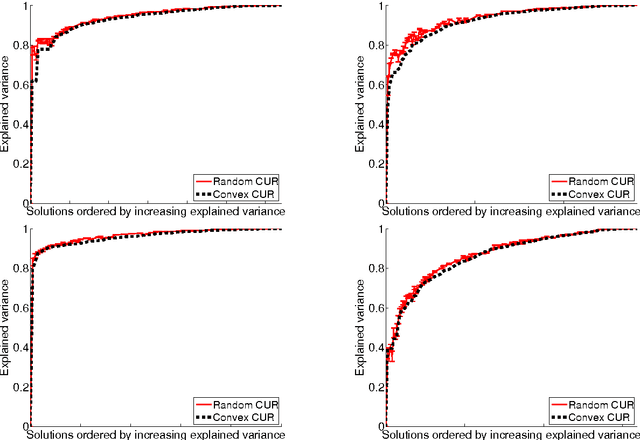
We consider a class of learning problems regularized by a structured sparsity-inducing norm defined as the sum of l_2- or l_infinity-norms over groups of variables. Whereas much effort has been put in developing fast optimization techniques when the groups are disjoint or embedded in a hierarchy, we address here the case of general overlapping groups. To this end, we present two different strategies: On the one hand, we show that the proximal operator associated with a sum of l_infinity-norms can be computed exactly in polynomial time by solving a quadratic min-cost flow problem, allowing the use of accelerated proximal gradient methods. On the other hand, we use proximal splitting techniques, and address an equivalent formulation with non-overlapping groups, but in higher dimension and with additional constraints. We propose efficient and scalable algorithms exploiting these two strategies, which are significantly faster than alternative approaches. We illustrate these methods with several problems such as CUR matrix factorization, multi-task learning of tree-structured dictionaries, background subtraction in video sequences, image denoising with wavelets, and topographic dictionary learning of natural image patches.
* to appear in the Journal of Machine Learning Research (JMLR)
Proximal Methods for Hierarchical Sparse Coding
Jul 05, 2011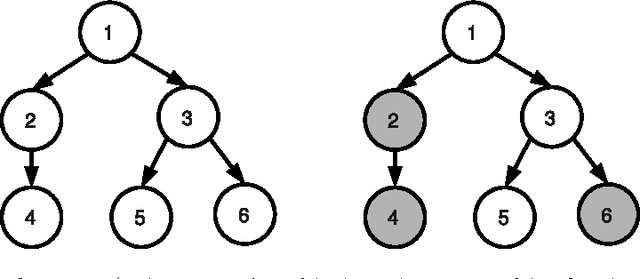
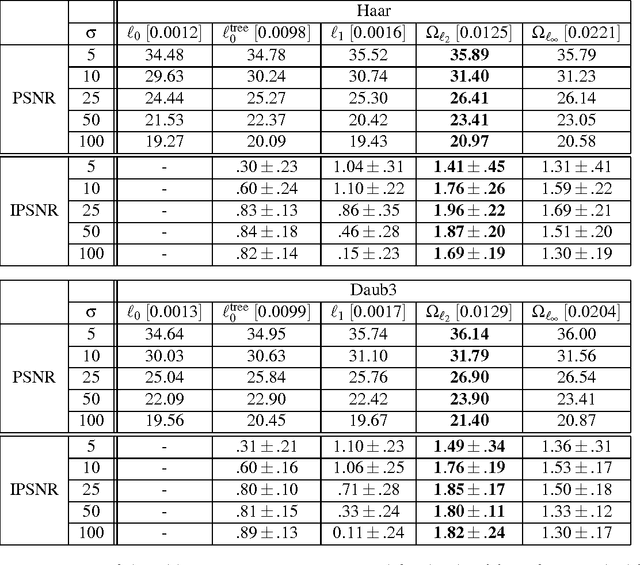
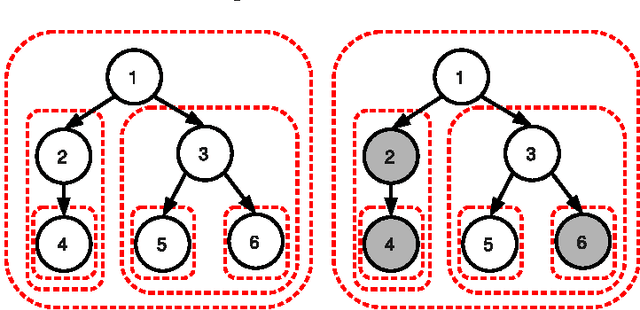

Sparse coding consists in representing signals as sparse linear combinations of atoms selected from a dictionary. We consider an extension of this framework where the atoms are further assumed to be embedded in a tree. This is achieved using a recently introduced tree-structured sparse regularization norm, which has proven useful in several applications. This norm leads to regularized problems that are difficult to optimize, and we propose in this paper efficient algorithms for solving them. More precisely, we show that the proximal operator associated with this norm is computable exactly via a dual approach that can be viewed as the composition of elementary proximal operators. Our procedure has a complexity linear, or close to linear, in the number of atoms, and allows the use of accelerated gradient techniques to solve the tree-structured sparse approximation problem at the same computational cost as traditional ones using the L1-norm. Our method is efficient and scales gracefully to millions of variables, which we illustrate in two types of applications: first, we consider fixed hierarchical dictionaries of wavelets to denoise natural images. Then, we apply our optimization tools in the context of dictionary learning, where learned dictionary elements naturally organize in a prespecified arborescent structure, leading to a better performance in reconstruction of natural image patches. When applied to text documents, our method learns hierarchies of topics, thus providing a competitive alternative to probabilistic topic models.
Network Flow Algorithms for Structured Sparsity
Aug 31, 2010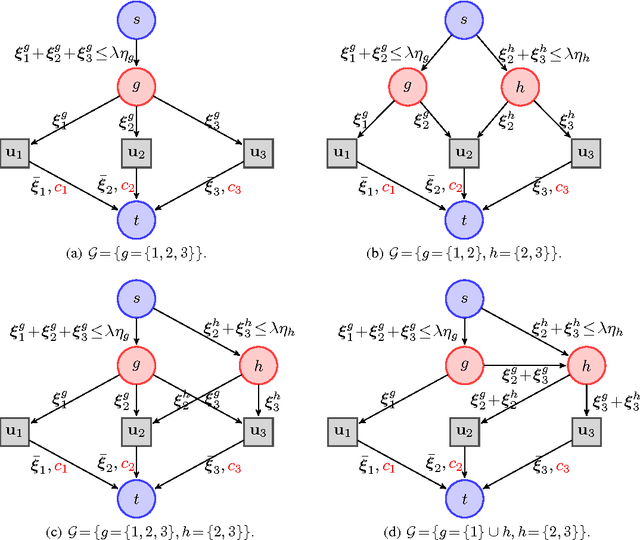
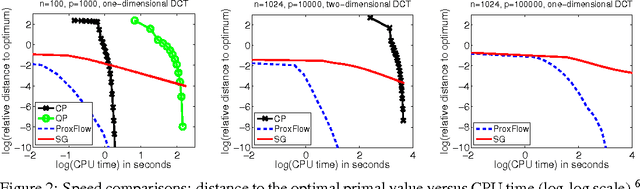

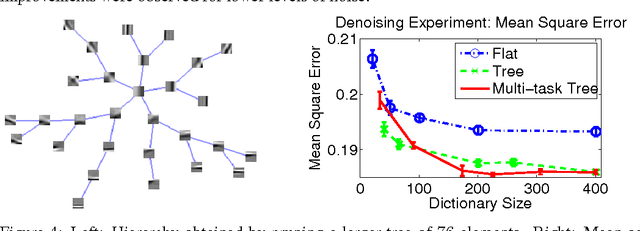
We consider a class of learning problems that involve a structured sparsity-inducing norm defined as the sum of $\ell_\infty$-norms over groups of variables. Whereas a lot of effort has been put in developing fast optimization methods when the groups are disjoint or embedded in a specific hierarchical structure, we address here the case of general overlapping groups. To this end, we show that the corresponding optimization problem is related to network flow optimization. More precisely, the proximal problem associated with the norm we consider is dual to a quadratic min-cost flow problem. We propose an efficient procedure which computes its solution exactly in polynomial time. Our algorithm scales up to millions of variables, and opens up a whole new range of applications for structured sparse models. We present several experiments on image and video data, demonstrating the applicability and scalability of our approach for various problems.
Structured Variable Selection with Sparsity-Inducing Norms
May 31, 2010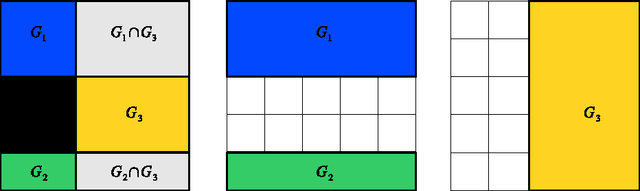



We consider the empirical risk minimization problem for linear supervised learning, with regularization by structured sparsity-inducing norms. These are defined as sums of Euclidean norms on certain subsets of variables, extending the usual $\ell_1$-norm and the group $\ell_1$-norm by allowing the subsets to overlap. This leads to a specific set of allowed nonzero patterns for the solutions of such problems. We first explore the relationship between the groups defining the norm and the resulting nonzero patterns, providing both forward and backward algorithms to go back and forth from groups to patterns. This allows the design of norms adapted to specific prior knowledge expressed in terms of nonzero patterns. We also present an efficient active set algorithm, and analyze the consistency of variable selection for least-squares linear regression in low and high-dimensional settings.