 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTornadoNet: Real-Time Building Damage Detection with Ordinal Supervision
Mar 12, 2026We present TornadoNet, a comprehensive benchmark for automated street-level building damage assessment evaluating how modern real-time object detection architectures and ordinal-aware supervision strategies perform under realistic post-disaster conditions. TornadoNet provides the first controlled benchmark demonstrating how architectural design and loss formulation jointly influence multi-level damage detection from street-view imagery, delivering methodological insights and deployable tools for disaster response. Using 3,333 high-resolution geotagged images and 8,890 annotated building instances from the 2021 Midwest tornado outbreak, we systematically compare CNN-based detectors from the YOLO family against transformer-based models (RT-DETR) for multi-level damage detection. Models are trained under standardized protocols using a five-level damage classification framework based on IN-CORE damage states, validated through expert cross-annotation. Baseline experiments reveal complementary architectural strengths. CNN-based YOLO models achieve highest detection accuracy and throughput, with larger variants reaching 46.05% mAP@0.5 at 66-276 FPS on A100 GPUs. Transformer-based RT-DETR models exhibit stronger ordinal consistency, achieving 88.13% Ordinal Top-1 Accuracy and MAOE of 0.65, indicating more reliable severity grading despite lower baseline mAP. To align supervision with the ordered nature of damage severity, we introduce soft ordinal classification targets and evaluate explicit ordinal-distance penalties. RT-DETR trained with calibrated ordinal supervision achieves 44.70% mAP@0.5, a 4.8 percentage-point improvement, with gains in ordinal metrics (91.15% Ordinal Top-1 Accuracy, MAOE = 0.56). These findings establish that ordinal-aware supervision improves damage severity estimation when aligned with detector architecture. Model & Data: https://github.com/crumeike/TornadoNet
Architectural Insights for Post-Tornado Damage Recognition
Feb 16, 2026Rapid and accurate building damage assessment in the immediate aftermath of tornadoes is critical for coordinating life-saving search and rescue operations, optimizing emergency resource allocation, and accelerating community recovery. However, current automated methods struggle with the unique visual complexity of tornado-induced wreckage, primarily due to severe domain shift from standard pre-training datasets and extreme class imbalance in real-world disaster data. To address these challenges, we introduce a systematic experimental framework evaluating 79 open-source deep learning models, encompassing both Convolutional Neural Networks (CNNs) and Vision Transformers, across over 2,300 controlled experiments on our newly curated Quad-State Tornado Damage (QSTD) benchmark dataset. Our findings reveal that achieving operational-grade performance hinges on a complex interaction between architecture and optimization, rather than architectural selection alone. Most strikingly, we demonstrate that optimizer choice can be more consequential than architecture: switching from Adam to SGD provided dramatic F1 gains of +25 to +38 points for Vision Transformer and Swin Transformer families, fundamentally reversing their ranking from bottom-tier to competitive with top-performing CNNs. Furthermore, a low learning rate of 1x10^(-4) proved universally critical, boosting average F1 performance by +10.2 points across all architectures. Our champion model, ConvNeXt-Base trained with these optimized settings, demonstrated strong cross-event generalization on the held-out Tuscaloosa-Moore Tornado Damage (TMTD) dataset, achieving 46.4% Macro F1 (+34.6 points over baseline) and retaining 85.5% Ordinal Top-1 Accuracy despite temporal and sensor domain shifts.
Contact-based Grasp Control and Inverse Kinematics for a Five-fingered Robotic Hand
Mar 24, 2025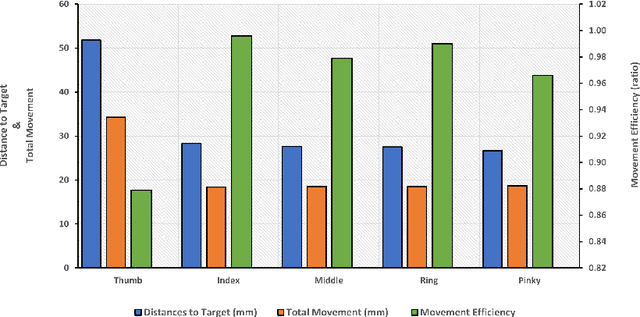
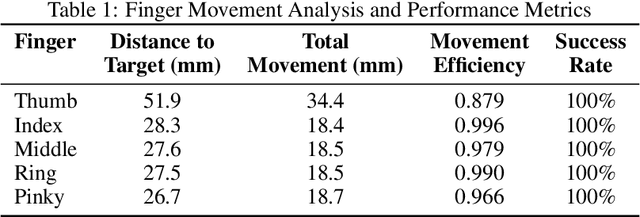

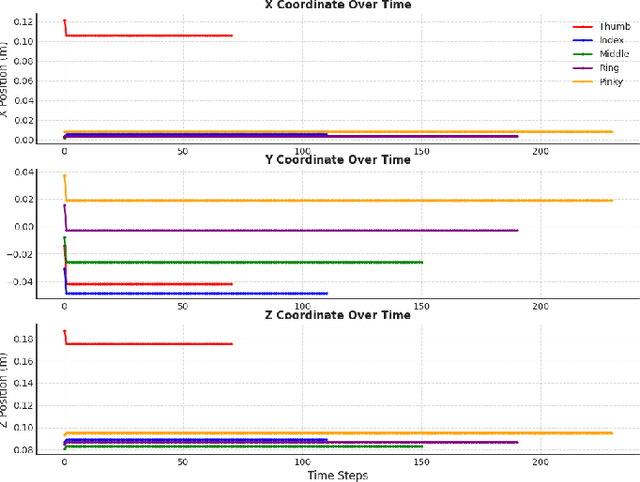
This paper presents an implementation and analysis of a five-fingered robotic grasping system that combines contact-based control with inverse kinematics solutions. Using the PyBullet simulation environment and the DexHand v2 model, we demonstrate a comprehensive approach to achieving stable grasps through contact point optimization with force closure validation. Our method achieves movement efficiency ratings between 0.966-0.996 for non-thumb fingers and 0.879 for the thumb, while maintaining positional accuracy within 0.0267-0.0283m for non-thumb digits and 0.0519m for the thumb. The system demonstrates rapid position stabilization at 240Hz simulation frequency and maintains stable contact configurations throughout the grasp execution. Experimental results validate the effectiveness of our approach, while also identifying areas for future enhancement in thumb opposition movements and horizontal plane control.
Scaling Large Vision-Language Models for Enhanced Multimodal Comprehension In Biomedical Image Analysis
Jan 26, 2025Large language models (LLMs) have demonstrated immense capabilities in understanding textual data and are increasingly being adopted to help researchers accelerate scientific discovery through knowledge extraction (information retrieval), knowledge distillation (summarizing key findings and methodologies into concise forms), and knowledge synthesis (aggregating information from multiple scientific sources to address complex queries, generate hypothesis and formulate experimental plans). However, scientific data often exists in both visual and textual modalities. Vision language models (VLMs) address this by incorporating a pretrained vision backbone for processing images and a cross-modal projector that adapts image tokens into the LLM dimensional space, thereby providing richer multimodal comprehension. Nevertheless, off-the-shelf VLMs show limited capabilities in handling domain-specific data and are prone to hallucinations. We developed intelligent assistants finetuned from LLaVA models to enhance multimodal understanding in low-dose radiation therapy (LDRT)-a benign approach used in the treatment of cancer-related illnesses. Using multilingual data from 42,673 articles, we devise complex reasoning and detailed description tasks for visual question answering (VQA) benchmarks. Our assistants, trained on 50,882 image-text pairs, demonstrate superior performance over base models as evaluated using LLM-as-a-judge approach, particularly in reducing hallucination and improving domain-specific comprehension.
Accelerating Post-Tornado Disaster Assessment Using Advanced Deep Learning Models
Dec 24, 2024



Post-disaster assessments of buildings and infrastructure are crucial for both immediate recovery efforts and long-term resilience planning. This research introduces an innovative approach to automating post-disaster assessments through advanced deep learning models. Our proposed system employs state-of-the-art computer vision techniques (YOLOv11 and ResNet50) to rapidly analyze images and videos from disaster sites, extracting critical information about building characteristics, including damage level of structural components and the extent of damage. Our experimental results show promising performance, with ResNet50 achieving 90.28% accuracy and an inference time of 1529ms per image on multiclass damage classification. This study contributes to the field of disaster management by offering a scalable, efficient, and objective tool for post-disaster analysis, potentially capable of transforming how communities and authorities respond to and learn from catastrophic events.