 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multitask framework for automated interpretation of multi-frame right upper quadrant ultrasound in clinical decision support
Jan 17, 2026Ultrasound is a cornerstone of emergency and hepatobiliary imaging, yet its interpretation remains highly operator-dependent and time-sensitive. Here, we present a multitask vision-language agent (VLM) developed to assist with comprehensive right upper quadrant (RUQ) ultrasound interpretation across the full diagnostic workflow. The system was trained on a large, multi-center dataset comprising a primary cohort from Johns Hopkins Medical Institutions (9,189 cases, 594,099 images) and externally validated on cohorts from Stanford University (108 cases, 3,240 images) and a major Chinese medical center (257 cases, 3,178 images). Built on the Qwen2.5-VL-7B architecture, the agent integrates frame-level visual understanding with report-grounded language reasoning to perform three tasks: (i) classification of 18 hepatobiliary and gallbladder conditions, (ii) generation of clinically coherent diagnostic reports, and (iii) surgical decision support based on ultrasound findings and clinical data. The model achieved high diagnostic accuracy across all tasks, generated reports that were indistinguishable from expert-written versions in blinded evaluations, and demonstrated superior factual accuracy and information density on content-based metrics. The agent further identified patients requiring cholecystectomy with high precision, supporting real-time decision-making. These results highlight the potential of generalist vision-language models to improve diagnostic consistency, reporting efficiency, and surgical triage in real-world ultrasound practice.
ART-Point: Improving Rotation Robustness of Point Cloud Classifiers via Adversarial Rotation
Mar 08, 2022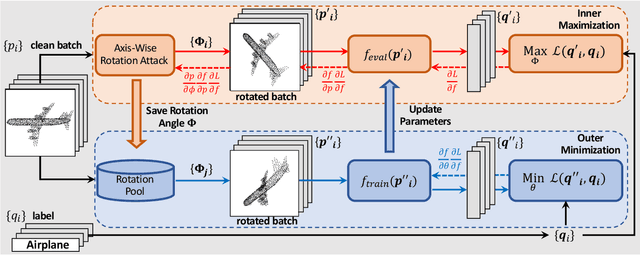
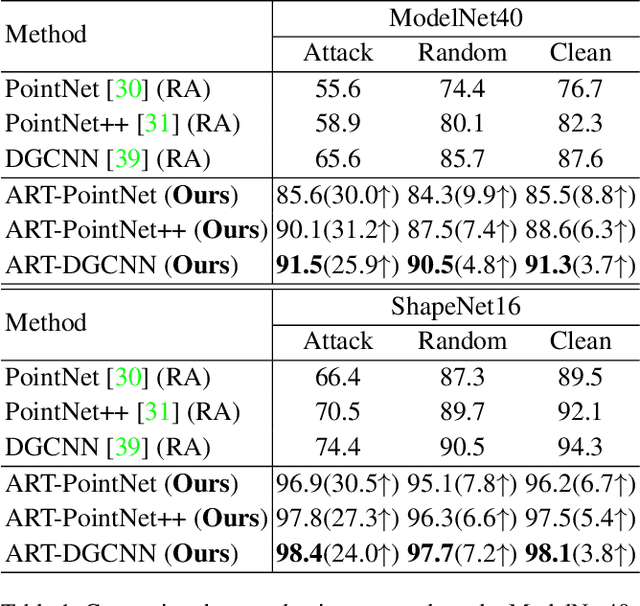
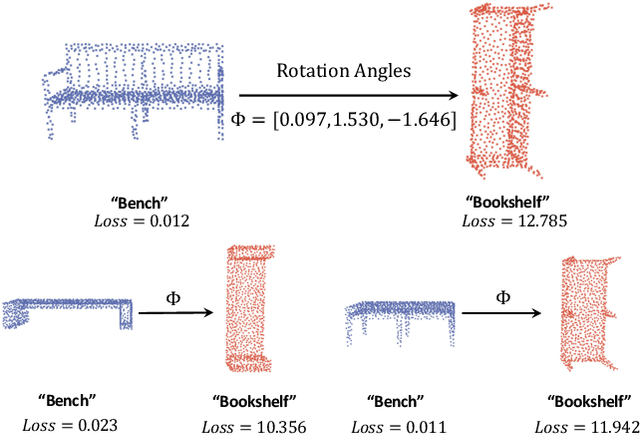
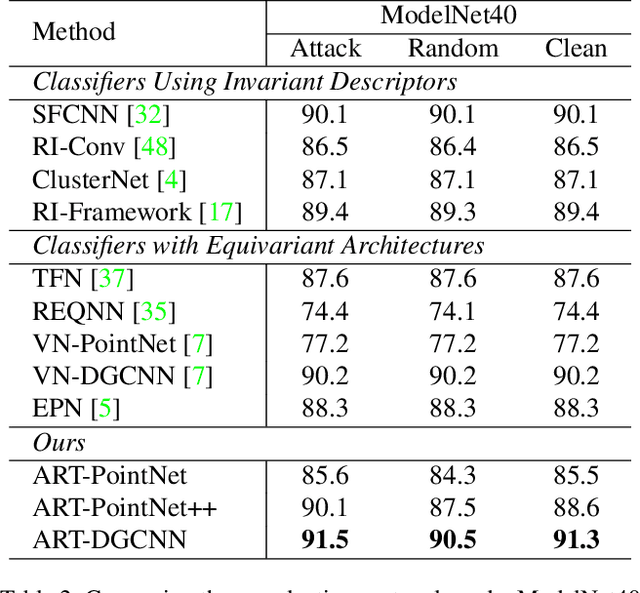
Point cloud classifiers with rotation robustness have been widely discussed in the 3D deep learning community. Most proposed methods either use rotation invariant descriptors as inputs or try to design rotation equivariant networks. However, robust models generated by these methods have limited performance under clean aligned datasets due to modifications on the original classifiers or input space. In this study, for the first time, we show that the rotation robustness of point cloud classifiers can also be acquired via adversarial training with better performance on both rotated and clean datasets. Specifically, our proposed framework named ART-Point regards the rotation of the point cloud as an attack and improves rotation robustness by training the classifier on inputs with Adversarial RoTations. We contribute an axis-wise rotation attack that uses back-propagated gradients of the pre-trained model to effectively find the adversarial rotations. To avoid model over-fitting on adversarial inputs, we construct rotation pools that leverage the transferability of adversarial rotations among samples to increase the diversity of training data. Moreover, we propose a fast one-step optimization to efficiently reach the final robust model. Experiments show that our proposed rotation attack achieves a high success rate and ART-Point can be used on most existing classifiers to improve the rotation robustness while showing better performance on clean datasets than state-of-the-art methods.