 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient End-to-End Visual Document Understanding with Rationale Distillation
Nov 16, 2023



Understanding visually situated language requires recognizing text and visual elements, and interpreting complex layouts. State-of-the-art methods commonly use specialized pre-processing tools, such as optical character recognition (OCR) systems, that map document image inputs to extracted information in the space of textual tokens, and sometimes also employ large language models (LLMs) to reason in text token space. However, the gains from external tools and LLMs come at the cost of increased computational and engineering complexity. In this paper, we ask whether small pretrained image-to-text models can learn selective text or layout recognition and reasoning as an intermediate inference step in an end-to-end model for pixel-level visual language understanding. We incorporate the outputs of such OCR tools, LLMs, and larger multimodal models as intermediate ``rationales'' on training data, and train a small student model to predict both rationales and answers for input questions based on those training examples. A student model based on Pix2Struct (282M parameters) achieves consistent improvements on three visual document understanding benchmarks representing infographics, scanned documents, and figures, with improvements of more than 4\% absolute over a comparable Pix2Struct model that predicts answers directly.
Do Localization Methods Actually Localize Memorized Data in LLMs?
Nov 15, 2023



Large language models (LLMs) can memorize many pretrained sequences verbatim. This paper studies if we can locate a small set of neurons in LLMs responsible for memorizing a given sequence. While the concept of localization is often mentioned in prior work, methods for localization have never been systematically and directly evaluated; we address this with two benchmarking approaches. In our INJ Benchmark, we actively inject a piece of new information into a small subset of LLM weights and measure whether localization methods can identify these "ground truth" weights. In the DEL Benchmark, we study localization of pretrained data that LLMs have already memorized; while this setting lacks ground truth, we can still evaluate localization by measuring whether dropping out located neurons erases a memorized sequence from the model. We evaluate five localization methods on our two benchmarks, and both show similar rankings. All methods exhibit promising localization ability, especially for pruning-based methods, though the neurons they identify are not necessarily specific to a single memorized sequence.
Transformers Learn Higher-Order Optimization Methods for In-Context Learning: A Study with Linear Models
Oct 26, 2023



Transformers are remarkably good at in-context learning (ICL) -- learning from demonstrations without parameter updates -- but how they perform ICL remains a mystery. Recent work suggests that Transformers may learn in-context by internally running Gradient Descent, a first-order optimization method. In this paper, we instead demonstrate that Transformers learn to implement higher-order optimization methods to perform ICL. Focusing on in-context linear regression, we show that Transformers learn to implement an algorithm very similar to Iterative Newton's Method, a higher-order optimization method, rather than Gradient Descent. Empirically, we show that predictions from successive Transformer layers closely match different iterations of Newton's Method linearly, with each middle layer roughly computing 3 iterations. In contrast, exponentially more Gradient Descent steps are needed to match an additional Transformers layer; this suggests that Transformers have an comparable rate of convergence with high-order methods such as Iterative Newton, which are exponentially faster than Gradient Descent. We also show that Transformers can learn in-context on ill-conditioned data, a setting where Gradient Descent struggles but Iterative Newton succeeds. Finally, we show theoretical results which support our empirical findings and have a close correspondence with them: we prove that Transformers can implement $k$ iterations of Newton's method with $\mathcal{O}(k)$ layers.
How Predictable Are Large Language Model Capabilities? A Case Study on BIG-bench
May 24, 2023



We investigate the predictability of large language model (LLM) capabilities: given records of past experiments using different model families, numbers of parameters, tasks, and numbers of in-context examples, can we accurately predict LLM performance on new experiment configurations? Answering this question has practical implications for LLM users (e.g., deciding which models to try), developers (e.g., prioritizing evaluation on representative tasks), and the research community (e.g., identifying hard-to-predict capabilities that warrant further investigation). We study the performance prediction problem on experiment records from BIG-bench. On a random train-test split, an MLP-based predictor achieves RMSE below 5%, demonstrating the presence of learnable patterns within the experiment records. Further, we formulate the problem of searching for "small-bench," an informative subset of BIG-bench tasks from which the performance of the full set can be maximally recovered, and find a subset as informative for evaluating new model families as BIG-bench Hard, while being 3x smaller.
Chain-of-Questions Training with Latent Answers for Robust Multistep Question Answering
May 24, 2023



We train a language model (LM) to robustly answer multistep questions by generating and answering sub-questions. We propose Chain-of-Questions, a framework that trains a model to generate sub-questions and sub-answers one at a time by leveraging human annotated question decomposition meaning representation (QDMR). The key technical challenge is that QDMR only contains sub-questions but not answers to those sub-questions, so we treat sub-answers as latent variables and optimize them using a novel dynamic mixture of Hard-EM and MAPO. Chain-of-Questions greatly outperforms strong neuro-symbolic methods by 9.0 F1 on DROP contrast set, and outperforms GPT-3.5 by 24.3 F1 on HOTPOTQA adversarial set, thus demonstrating the effectiveness and robustness of our framework.
Estimating Large Language Model Capabilities without Labeled Test Data
May 24, 2023



Large Language Models (LLMs) have exhibited an impressive ability to perform in-context learning (ICL) from only a few examples, but the success of ICL varies widely from task to task. Thus, it is important to quickly determine whether ICL is applicable to a new task, but directly evaluating ICL accuracy can be expensive in situations where test data is expensive to annotate -- the exact situations where ICL is most appealing. In this paper, we propose the task of ICL accuracy estimation, in which we predict the accuracy of an LLM when doing in-context learning on a new task given only unlabeled data for that task. To perform ICL accuracy estimation, we propose a method that trains a meta-model using LLM confidence scores as features. We compare our method to several strong accuracy estimation baselines on a new benchmark that covers 4 LLMs and 3 task collections. On average, the meta-model improves over all baselines and achieves the same estimation performance as directly evaluating on 40 labeled test examples per task, across the total 12 settings. We encourage future work to improve on our methods and evaluate on our ICL accuracy estimation benchmark to deepen our understanding of when ICL works.
SCENE: Self-Labeled Counterfactuals for Extrapolating to Negative Examples
May 13, 2023Detecting negatives (such as non-entailment relationships, unanswerable questions, and false claims) is an important and challenging aspect of many natural language understanding tasks. Though manually collecting challenging negative examples can help models detect them, it is both costly and domain-specific. In this work, we propose Self-labeled Counterfactuals for Extrapolating to Negative Examples (SCENE), an automatic method for synthesizing training data that greatly improves models' ability to detect challenging negative examples. In contrast with standard data augmentation, which synthesizes new examples for existing labels, SCENE can synthesize negative examples zero-shot from only positive ones. Given a positive example, SCENE perturbs it with a mask infilling model, then determines whether the resulting example is negative based on a self-training heuristic. With access to only answerable training examples, SCENE can close 69.6% of the performance gap on SQuAD 2.0, a dataset where half of the evaluation examples are unanswerable, compared to a model trained on SQuAD 2.0. Our method also extends to boolean question answering and recognizing textual entailment, and improves generalization from SQuAD to ACE-whQA, an out-of-domain extractive QA benchmark.
Careful Data Curation Stabilizes In-context Learning
Dec 20, 2022In-context learning (ICL) enables large language models (LLMs) to perform new tasks by prompting them with a sequence of training examples. However, ICL is very sensitive to the choice of training examples: randomly sampling examples from a training set leads to high variance in performance. In this paper, we show that curating a carefully chosen subset of training data greatly stabilizes ICL performance. We propose two methods to choose training subsets, both of which score training examples individually and then select the highest-scoring ones. CondAcc scores a training example by its average ICL accuracy when combined with random training examples, while Datamodels learns a linear proxy model that estimates how the presence of each training example influences LLM accuracy. On average, CondAcc and Datamodels outperform sampling from the entire training set by 7.7% and 6.3%, respectively, across 5 tasks and two LLMs. Our analysis shows that stable subset examples are no more diverse than average, and are not outliers in terms of sequence length and perplexity.
CoNAL: Anticipating Outliers with Large Language Models
Nov 28, 2022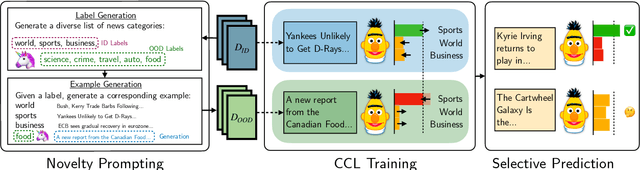
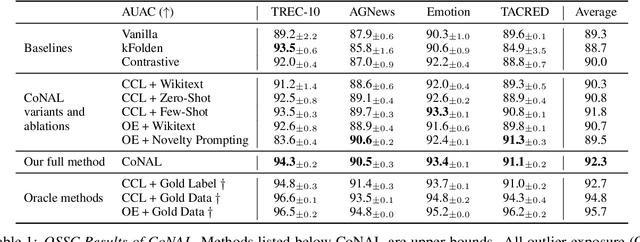

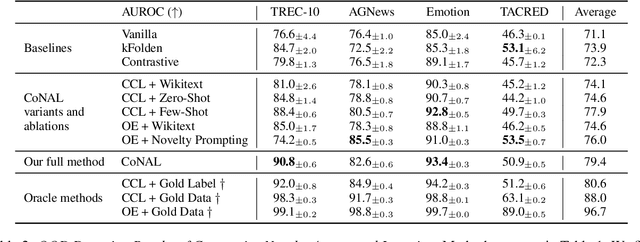
In many task settings, text classification models are likely to encounter examples from novel classes on which they cannot predict correctly. Selective prediction, in which models abstain on low-confidence examples, provides a possible solution, but existing models are often overly confident on OOD examples. To remedy this overconfidence, we introduce Contrastive Novelty-Augmented Learning (CoNAL), a two-step method that generates OOD examples representative of novel classes, then trains to decrease confidence on them. First, we generate OOD examples by prompting a large language model twice: we prompt it to enumerate relevant novel labels, then generate examples from each novel class matching the task format. Second, we train our classifier with a novel contrastive objective that encourages lower confidence on generated OOD examples than training examples. When trained with CoNAL, classifiers improve in their ability to detect and abstain on OOD examples over prior methods by an average of 2.3% AUAC and 5.5% AUROC across 4 NLP datasets, with no cost to in-distribution accuracy.
Generalization Differences between End-to-End and Neuro-Symbolic Vision-Language Reasoning Systems
Oct 26, 2022



For vision-and-language reasoning tasks, both fully connectionist, end-to-end methods and hybrid, neuro-symbolic methods have achieved high in-distribution performance. In which out-of-distribution settings does each paradigm excel? We investigate this question on both single-image and multi-image visual question-answering through four types of generalization tests: a novel segment-combine test for multi-image queries, contrast set, compositional generalization, and cross-benchmark transfer. Vision-and-language end-to-end trained systems exhibit sizeable performance drops across all these tests. Neuro-symbolic methods suffer even more on cross-benchmark transfer from GQA to VQA, but they show smaller accuracy drops on the other generalization tests and their performance quickly improves by few-shot training. Overall, our results demonstrate the complementary benefits of these two paradigms, and emphasize the importance of using a diverse suite of generalization tests to fully characterize model robustness to distribution shift.