 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZEST: Zero-shot Embodied Skill Transfer for Athletic Robot Control
Jan 30, 2026Achieving robust, human-like whole-body control on humanoid robots for agile, contact-rich behaviors remains a central challenge, demanding heavy per-skill engineering and a brittle process of tuning controllers. We introduce ZEST (Zero-shot Embodied Skill Transfer), a streamlined motion-imitation framework that trains policies via reinforcement learning from diverse sources -- high-fidelity motion capture, noisy monocular video, and non-physics-constrained animation -- and deploys them to hardware zero-shot. ZEST generalizes across behaviors and platforms while avoiding contact labels, reference or observation windows, state estimators, and extensive reward shaping. Its training pipeline combines adaptive sampling, which focuses training on difficult motion segments, and an automatic curriculum using a model-based assistive wrench, together enabling dynamic, long-horizon maneuvers. We further provide a procedure for selecting joint-level gains from approximate analytical armature values for closed-chain actuators, along with a refined model of actuators. Trained entirely in simulation with moderate domain randomization, ZEST demonstrates remarkable generality. On Boston Dynamics' Atlas humanoid, ZEST learns dynamic, multi-contact skills (e.g., army crawl, breakdancing) from motion capture. It transfers expressive dance and scene-interaction skills, such as box-climbing, directly from videos to Atlas and the Unitree G1. Furthermore, it extends across morphologies to the Spot quadruped, enabling acrobatics, such as a continuous backflip, through animation. Together, these results demonstrate robust zero-shot deployment across heterogeneous data sources and embodiments, establishing ZEST as a scalable interface between biological movements and their robotic counterparts.
LVIS: Learning from Value Function Intervals for Contact-Aware Robot Controllers
Sep 16, 2018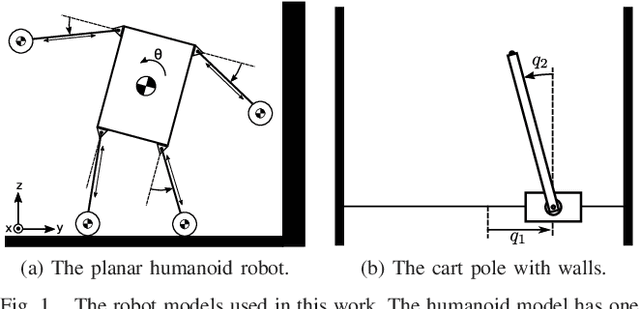
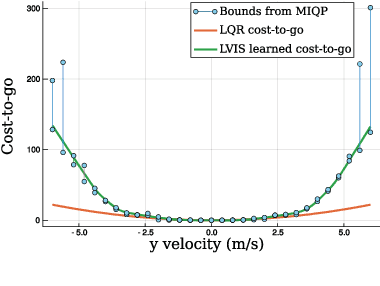
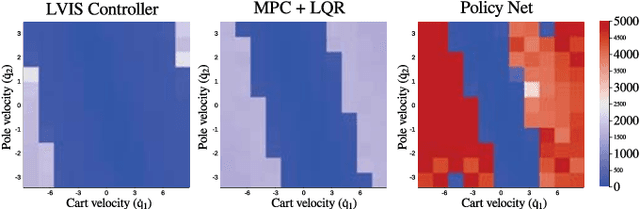
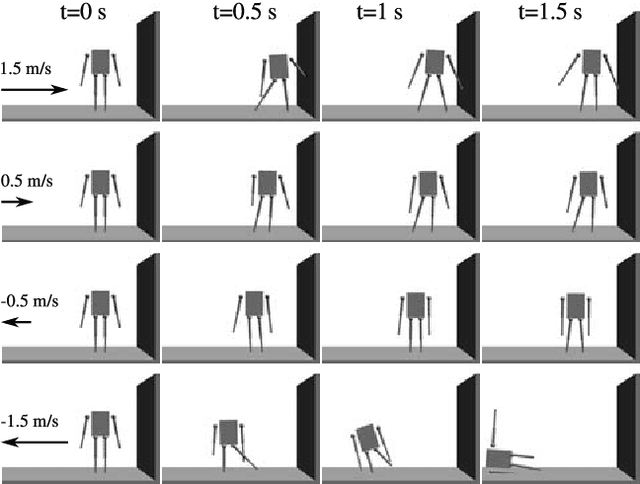
Guided policy search is a popular approach for training controllers for high-dimensional systems, but it has a number of pitfalls. Non-convex trajectory optimization has local minima, and non-uniqueness in the optimal policy itself can mean that independently-optimized samples do not describe a coherent policy from which to train. We introduce LVIS, which circumvents the issue of local minima through global mixed-integer optimization and the issue of non-uniqueness through learning the optimal value function (or cost-to-go) rather than the optimal policy. To avoid the expense of solving the mixed-integer programs to full global optimality, we instead solve them only partially, extracting intervals containing the true cost-to-go from early termination of the branch-and-bound algorithm. These interval samples are used to weakly supervise the training of a neural net which approximates the true cost-to-go. Online, we use that learned cost-to-go as the terminal cost of a one-step model-predictive controller, which we solve via a small mixed-integer optimization. We demonstrate the LVIS approach on a cart-pole system with walls and a planar humanoid robot model and show that it can be applied to a fundamentally hard problem in feedback control--control through contact.