 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Depth Estimation by Fusing Single-View Depth Probability with Multi-View Geometry
Dec 15, 2021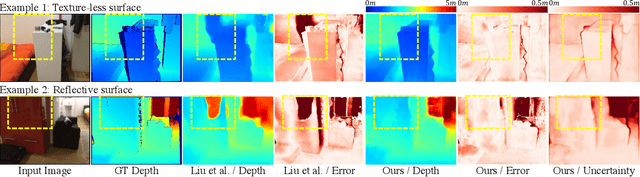
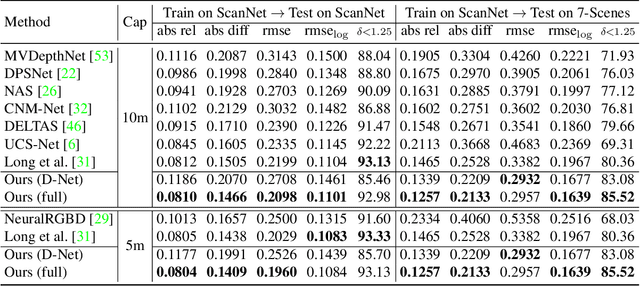

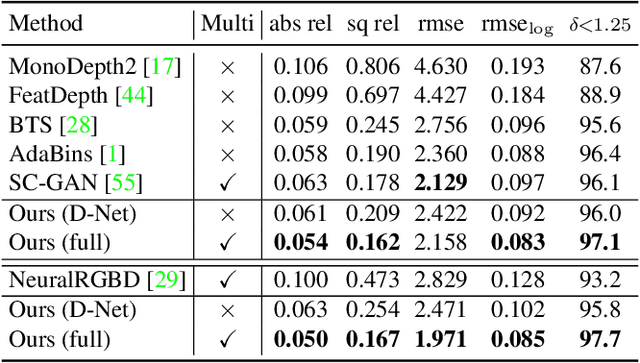
Multi-view depth estimation methods typically require the computation of a multi-view cost-volume, which leads to huge memory consumption and slow inference. Furthermore, multi-view matching can fail for texture-less surfaces, reflective surfaces and moving objects. For such failure modes, single-view depth estimation methods are often more reliable. To this end, we propose MaGNet, a novel framework for fusing single-view depth probability with multi-view geometry, to improve the accuracy, robustness and efficiency of multi-view depth estimation. For each frame, MaGNet estimates a single-view depth probability distribution, parameterized as a pixel-wise Gaussian. The distribution estimated for the reference frame is then used to sample per-pixel depth candidates. Such probabilistic sampling enables the network to achieve higher accuracy while evaluating fewer depth candidates. We also propose depth consistency weighting for the multi-view matching score, to ensure that the multi-view depth is consistent with the single-view predictions. The proposed method achieves state-of-the-art performance on ScanNet, 7-Scenes and KITTI. Qualitative evaluation demonstrates that our method is more robust against challenging artifacts such as texture-less/reflective surfaces and moving objects.
Discrete neural representations for explainable anomaly detection
Dec 10, 2021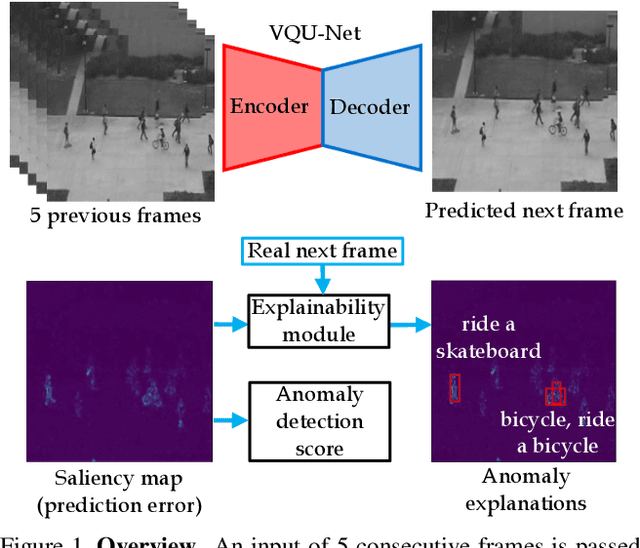
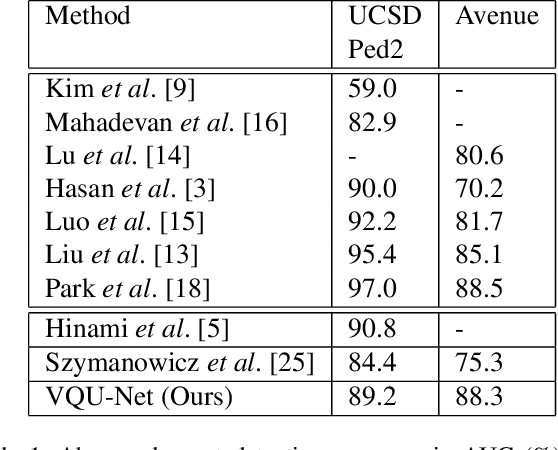
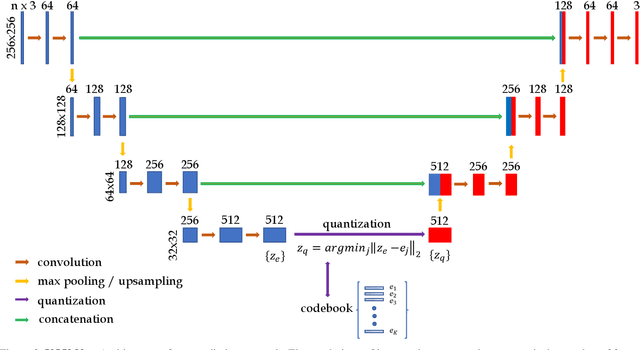
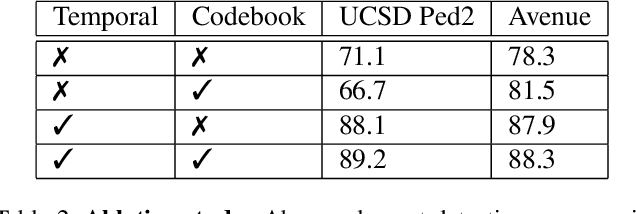
The aim of this work is to detect and automatically generate high-level explanations of anomalous events in video. Understanding the cause of an anomalous event is crucial as the required response is dependant on its nature and severity. Recent works typically use object or action classifier to detect and provide labels for anomalous events. However, this constrains detection systems to a finite set of known classes and prevents generalisation to unknown objects or behaviours. Here we show how to robustly detect anomalies without the use of object or action classifiers yet still recover the high level reason behind the event. We make the following contributions: (1) a method using saliency maps to decouple the explanation of anomalous events from object and action classifiers, (2) show how to improve the quality of saliency maps using a novel neural architecture for learning discrete representations of video by predicting future frames and (3) beat the state-of-the-art anomaly explanation methods by 60\% on a subset of the public benchmark X-MAN dataset.
Probabilistic Estimation of 3D Human Shape and Pose with a Semantic Local Parametric Model
Nov 30, 2021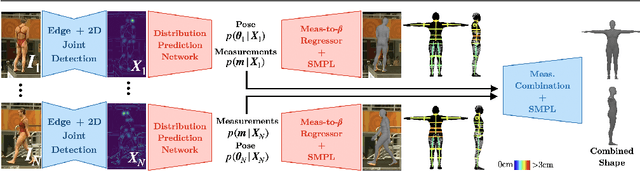
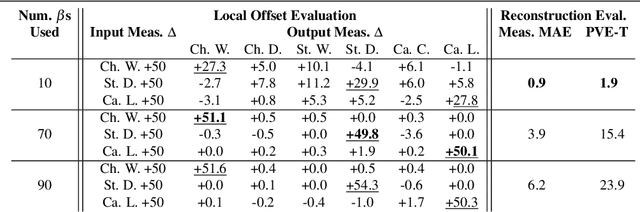
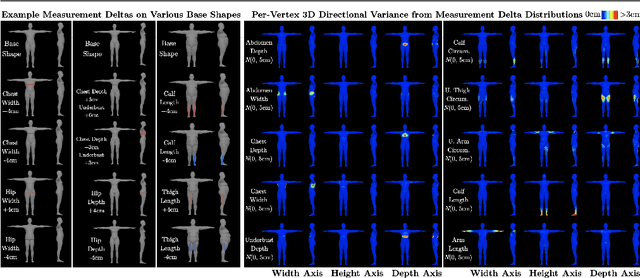
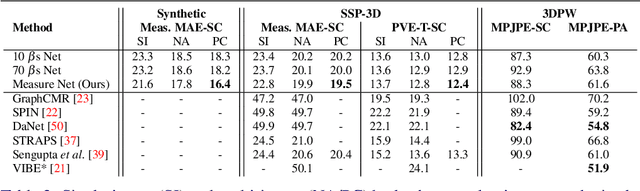
This paper addresses the problem of 3D human body shape and pose estimation from RGB images. Some recent approaches to this task predict probability distributions over human body model parameters conditioned on the input images. This is motivated by the ill-posed nature of the problem wherein multiple 3D reconstructions may match the image evidence, particularly when some parts of the body are locally occluded. However, body shape parameters in widely-used body models (e.g. SMPL) control global deformations over the whole body surface. Distributions over these global shape parameters are unable to meaningfully capture uncertainty in shape estimates associated with locally-occluded body parts. In contrast, we present a method that (i) predicts distributions over local body shape in the form of semantic body measurements and (ii) uses a linear mapping to transform a local distribution over body measurements to a global distribution over SMPL shape parameters. We show that our method outperforms the current state-of-the-art in terms of identity-dependent body shape estimation accuracy on the SSP-3D dataset, and a private dataset of tape-measured humans, by probabilistically-combining local body measurement distributions predicted from multiple images of a subject.
Leveraging Geometry for Shape Estimation from a Single RGB Image
Nov 10, 2021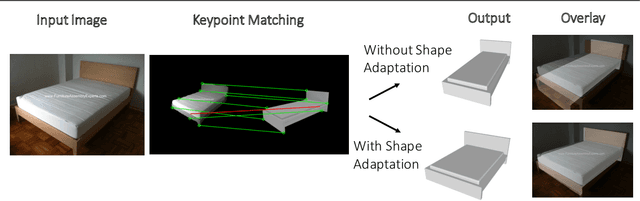
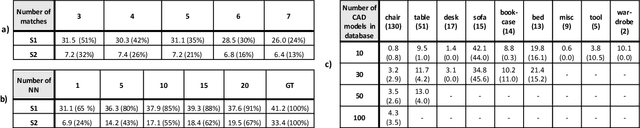
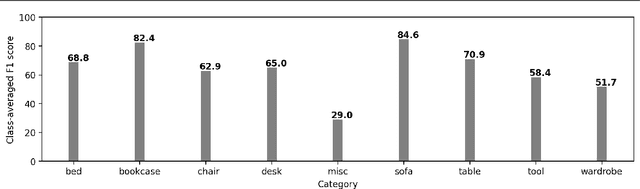
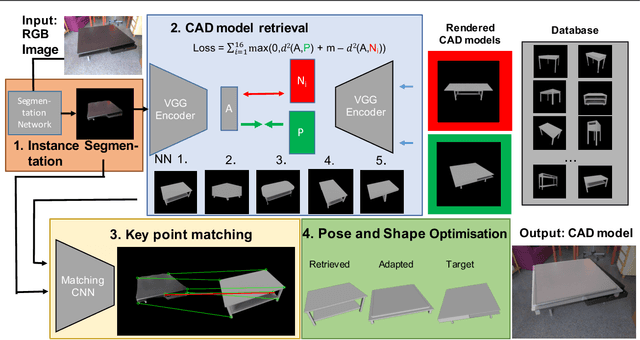
Predicting 3D shapes and poses of static objects from a single RGB image is an important research area in modern computer vision. Its applications range from augmented reality to robotics and digital content creation. Typically this task is performed through direct object shape and pose predictions which is inaccurate. A promising research direction ensures meaningful shape predictions by retrieving CAD models from large scale databases and aligning them to the objects observed in the image. However, existing work does not take the object geometry into account, leading to inaccurate object pose predictions, especially for unseen objects. In this work we demonstrate how cross-domain keypoint matches from an RGB image to a rendered CAD model allow for more precise object pose predictions compared to ones obtained through direct predictions. We further show that keypoint matches can not only be used to estimate the pose of an object, but also to modify the shape of the object itself. This is important as the accuracy that can be achieved with object retrieval alone is inherently limited to the available CAD models. Allowing shape adaptation bridges the gap between the retrieved CAD model and the observed shape. We demonstrate our approach on the challenging Pix3D dataset. The proposed geometric shape prediction improves the AP mesh over the state-of-the-art from 33.2 to 37.8 on seen objects and from 8.2 to 17.1 on unseen objects. Furthermore, we demonstrate more accurate shape predictions without closely matching CAD models when following the proposed shape adaptation. Code is publicly available at https://github.com/florianlanger/leveraging_geometry_for_shape_estimation .
Hierarchical Kinematic Probability Distributions for 3D Human Shape and Pose Estimation from Images in the Wild
Oct 03, 2021
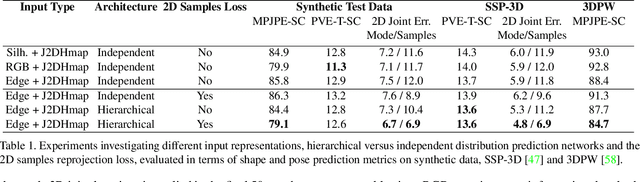
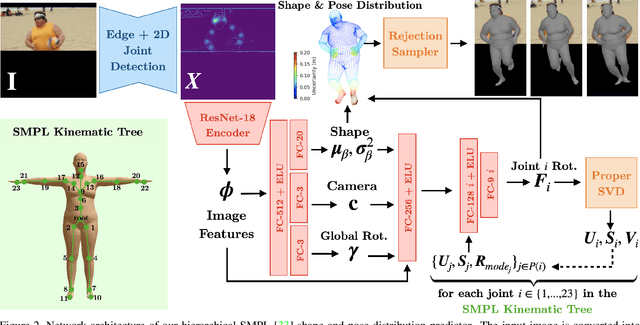
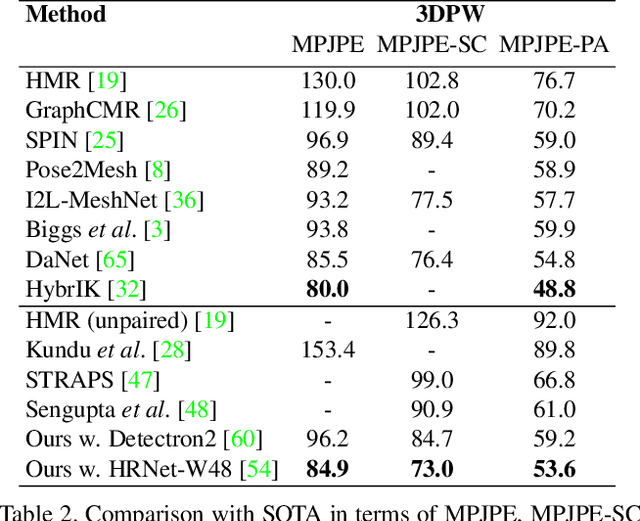
This paper addresses the problem of 3D human body shape and pose estimation from an RGB image. This is often an ill-posed problem, since multiple plausible 3D bodies may match the visual evidence present in the input - particularly when the subject is occluded. Thus, it is desirable to estimate a distribution over 3D body shape and pose conditioned on the input image instead of a single 3D reconstruction. We train a deep neural network to estimate a hierarchical matrix-Fisher distribution over relative 3D joint rotation matrices (i.e. body pose), which exploits the human body's kinematic tree structure, as well as a Gaussian distribution over SMPL body shape parameters. To further ensure that the predicted shape and pose distributions match the visual evidence in the input image, we implement a differentiable rejection sampler to impose a reprojection loss between ground-truth 2D joint coordinates and samples from the predicted distributions, projected onto the image plane. We show that our method is competitive with the state-of-the-art in terms of 3D shape and pose metrics on the SSP-3D and 3DPW datasets, while also yielding a structured probability distribution over 3D body shape and pose, with which we can meaningfully quantify prediction uncertainty and sample multiple plausible 3D reconstructions to explain a given input image. Code is available at https://github.com/akashsengupta1997/HierarchicalProbabilistic3DHuman .
Estimating and Exploiting the Aleatoric Uncertainty in Surface Normal Estimation
Sep 20, 2021
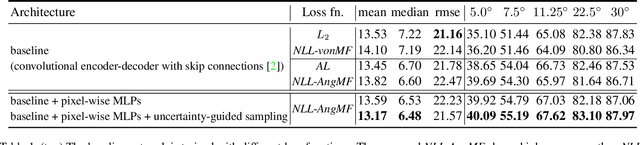

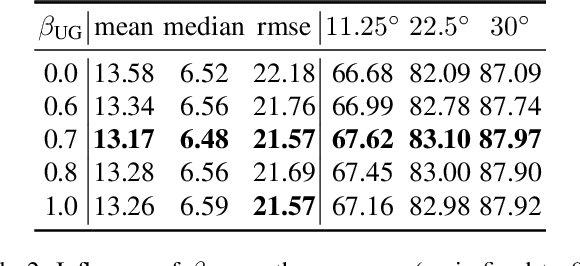
Surface normal estimation from a single image is an important task in 3D scene understanding. In this paper, we address two limitations shared by the existing methods: the inability to estimate the aleatoric uncertainty and lack of detail in the prediction. The proposed network estimates the per-pixel surface normal probability distribution. We introduce a new parameterization for the distribution, such that its negative log-likelihood is the angular loss with learned attenuation. The expected value of the angular error is then used as a measure of the aleatoric uncertainty. We also present a novel decoder framework where pixel-wise multi-layer perceptrons are trained on a subset of pixels sampled based on the estimated uncertainty. The proposed uncertainty-guided sampling prevents the bias in training towards large planar surfaces and improves the quality of prediction, especially near object boundaries and on small structures. Experimental results show that the proposed method outperforms the state-of-the-art in ScanNet and NYUv2, and that the estimated uncertainty correlates well with the prediction error. Code is available at https://github.com/baegwangbin/surface_normal_uncertainty.
X-MAN: Explaining multiple sources of anomalies in video
Jun 16, 2021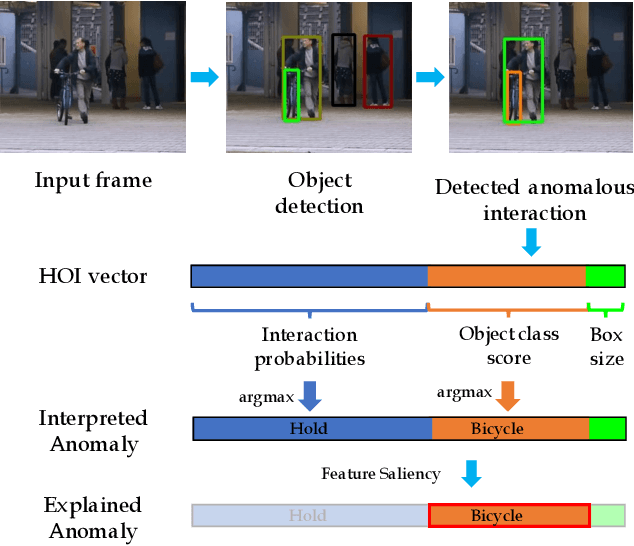
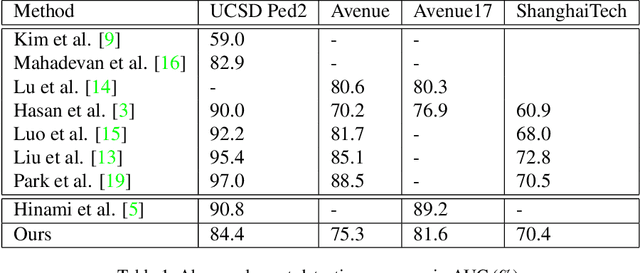
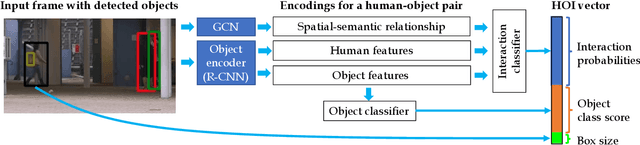
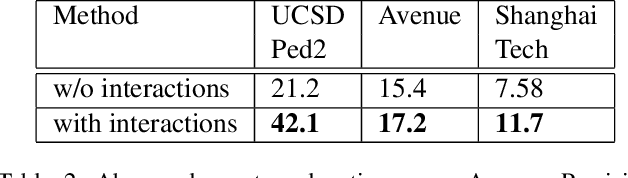
Our objective is to detect anomalies in video while also automatically explaining the reason behind the detector's response. In a practical sense, explainability is crucial for this task as the required response to an anomaly depends on its nature and severity. However, most leading methods (based on deep neural networks) are not interpretable and hide the decision making process in uninterpretable feature representations. In an effort to tackle this problem we make the following contributions: (1) we show how to build interpretable feature representations suitable for detecting anomalies with state of the art performance, (2) we propose an interpretable probabilistic anomaly detector which can describe the reason behind it's response using high level concepts, (3) we are the first to directly consider object interactions for anomaly detection and (4) we propose a new task of explaining anomalies and release a large dataset for evaluating methods on this task. Our method competes well with the state of the art on public datasets while also providing anomaly explanation based on objects and their interactions.
LUCES: A Dataset for Near-Field Point Light Source Photometric Stereo
Apr 27, 2021


Three-dimensional reconstruction of objects from shading information is a challenging task in computer vision. As most of the approaches facing the Photometric Stereo problem use simplified far-field assumptions, real-world scenarios have essentially more complex physical effects that need to be handled for accurately reconstructing the 3D shape. An increasing number of methods have been proposed to address the problem when point light sources are assumed to be nearby the target object. The proximity of the light sources complicates the modeling of the image formation as the light behaviour requires non-linear parameterisation to describe its propagation and attenuation. To understand the capability of the approaches dealing with this near-field scenario, the literature till now has used synthetically rendered photometric images or minimal and very customised real-world data. In order to fill the gap in evaluating near-field photometric stereo methods, we introduce LUCES the first real-world 'dataset for near-fieLd point light soUrCe photomEtric Stereo' of 14 objects of a varying of materials. A device counting 52 LEDs has been designed to lit each object positioned 10 to 30 centimeters away from the camera. Together with the raw images, in order to evaluate the 3D reconstructions, the dataset includes both normal and depth maps for comparing different features of the retrieved 3D geometry. Furthermore, we evaluate the performance of the latest near-field Photometric Stereo algorithms on the proposed dataset to assess the SOTA method with respect to actual close range effects and object materials.
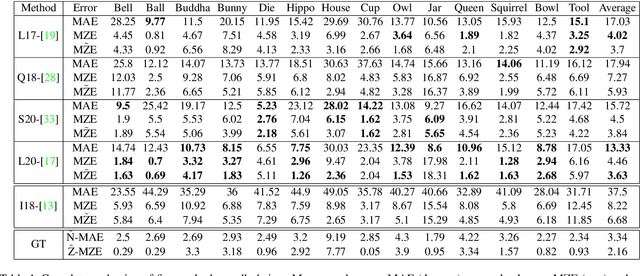
FIERY: Future Instance Prediction in Bird's-Eye View from Surround Monocular Cameras
Apr 21, 2021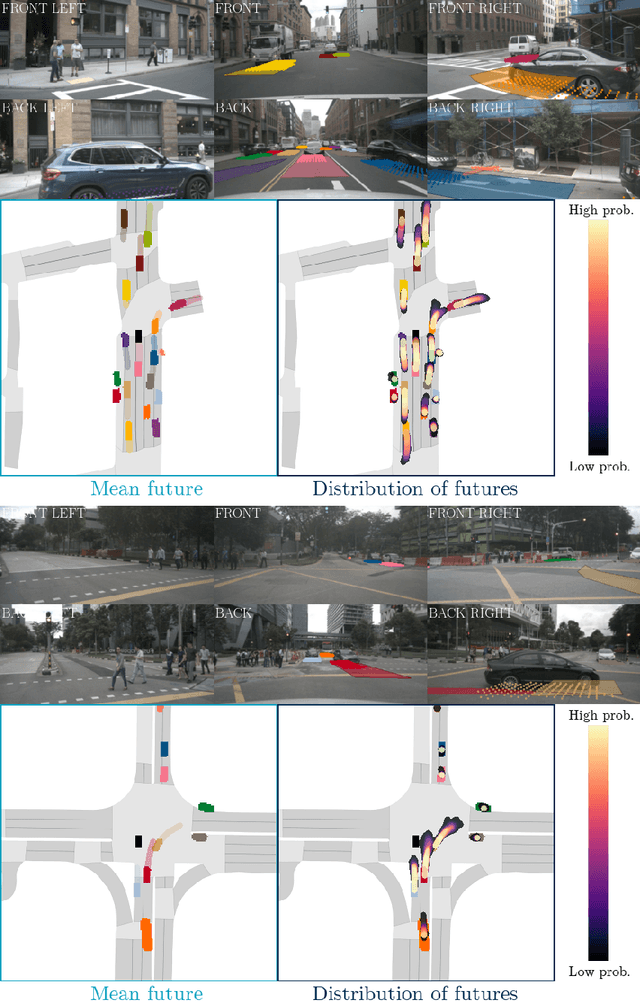
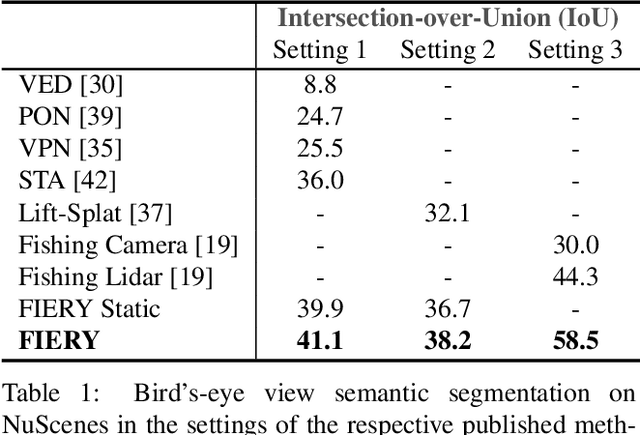
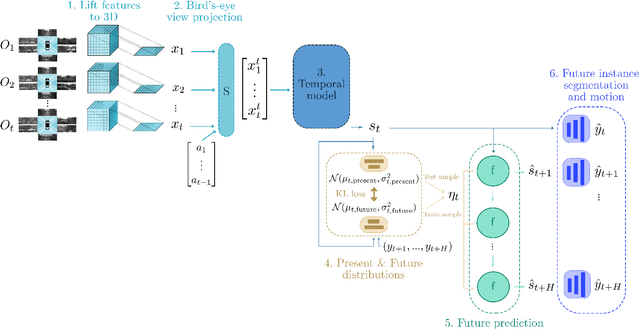
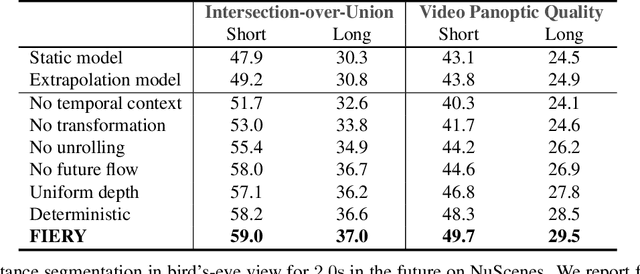
Driving requires interacting with road agents and predicting their future behaviour in order to navigate safely. We present FIERY: a probabilistic future prediction model in bird's-eye view from monocular cameras. Our model predicts future instance segmentation and motion of dynamic agents that can be transformed into non-parametric future trajectories. Our approach combines the perception, sensor fusion and prediction components of a traditional autonomous driving stack by estimating bird's-eye-view prediction directly from surround RGB monocular camera inputs. FIERY learns to model the inherent stochastic nature of the future directly from camera driving data in an end-to-end manner, without relying on HD maps, and predicts multimodal future trajectories. We show that our model outperforms previous prediction baselines on the NuScenes and Lyft datasets. Code is available at https://github.com/wayveai/fiery
Probabilistic 3D Human Shape and Pose Estimation from Multiple Unconstrained Images in the Wild
Mar 30, 2021
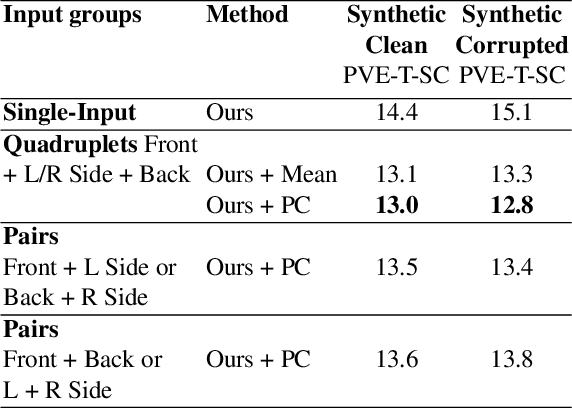
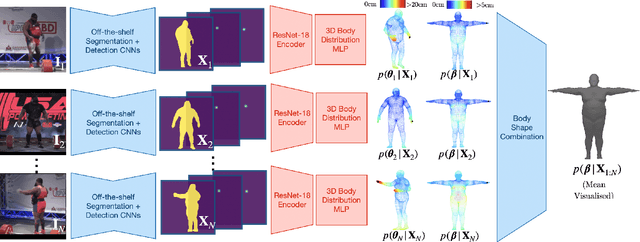
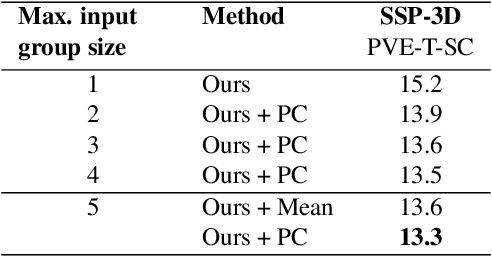
This paper addresses the problem of 3D human body shape and pose estimation from RGB images. Recent progress in this field has focused on single images, video or multi-view images as inputs. In contrast, we propose a new task: shape and pose estimation from a group of multiple images of a human subject, without constraints on subject pose, camera viewpoint or background conditions between images in the group. Our solution to this task predicts distributions over SMPL body shape and pose parameters conditioned on the input images in the group. We probabilistically combine predicted body shape distributions from each image to obtain a final multi-image shape prediction. We show that the additional body shape information present in multi-image input groups improves 3D human shape estimation metrics compared to single-image inputs on the SSP-3D dataset and a private dataset of tape-measured humans. In addition, predicting distributions over 3D bodies allows us to quantify pose prediction uncertainty, which is useful when faced with challenging input images with significant occlusion. Our method demonstrates meaningful pose uncertainty on the 3DPW dataset and is competitive with the state-of-the-art in terms of pose estimation metrics.