 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolding AI to Account: Challenges for the Delivery of Trustworthy AI in Healthcare
Nov 29, 2022The need for AI systems to provide explanations for their behaviour is now widely recognised as key to their adoption. In this paper, we examine the problem of trustworthy AI and explore what delivering this means in practice, with a focus on healthcare applications. Work in this area typically treats trustworthy AI as a problem of Human-Computer Interaction involving the individual user and an AI system. However, we argue here that this overlooks the important part played by organisational accountability in how people reason about and trust AI in socio-technical settings. To illustrate the importance of organisational accountability, we present findings from ethnographic studies of breast cancer screening and cancer treatment planning in multidisciplinary team meetings to show how participants made themselves accountable both to each other and to the organisations of which they are members. We use these findings to enrich existing understandings of the requirements for trustworthy AI and to outline some candidate solutions to the problems of making AI accountable both to individual users and organisationally. We conclude by outlining the implications of this for future work on the development of trustworthy AI, including ways in which our proposed solutions may be re-used in different application settings.
Unsupervised Opinion Summarisation in the Wasserstein Space
Nov 27, 2022



Opinion summarisation synthesises opinions expressed in a group of documents discussing the same topic to produce a single summary. Recent work has looked at opinion summarisation of clusters of social media posts. Such posts are noisy and have unpredictable structure, posing additional challenges for the construction of the summary distribution and the preservation of meaning compared to online reviews, which has been so far the focus of opinion summarisation. To address these challenges we present \textit{WassOS}, an unsupervised abstractive summarization model which makes use of the Wasserstein distance. A Variational Autoencoder is used to get the distribution of documents/posts, and the distributions are disentangled into separate semantic and syntactic spaces. The summary distribution is obtained using the Wasserstein barycenter of the semantic and syntactic distributions. A latent variable sampled from the summary distribution is fed into a GRU decoder with a transformer layer to produce the final summary. Our experiments on multiple datasets including Twitter clusters, Reddit threads, and reviews show that WassOS almost always outperforms the state-of-the-art on ROUGE metrics and consistently produces the best summaries with respect to meaning preservation according to human evaluations.
Template-based Abstractive Microblog Opinion Summarisation
Aug 08, 2022
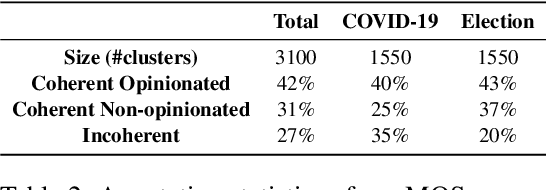


We introduce the task of microblog opinion summarisation (MOS) and share a dataset of 3100 gold-standard opinion summaries to facilitate research in this domain. The dataset contains summaries of tweets spanning a 2-year period and covers more topics than any other public Twitter summarisation dataset. Summaries are abstractive in nature and have been created by journalists skilled in summarising news articles following a template separating factual information (main story) from author opinions. Our method differs from previous work on generating gold-standard summaries from social media, which usually involves selecting representative posts and thus favours extractive summarisation models. To showcase the dataset's utility and challenges, we benchmark a range of abstractive and extractive state-of-the-art summarisation models and achieve good performance, with the former outperforming the latter. We also show that fine-tuning is necessary to improve performance and investigate the benefits of using different sample sizes.
Supporting peace negotiations in the Yemen war through machine learning
Jul 23, 2022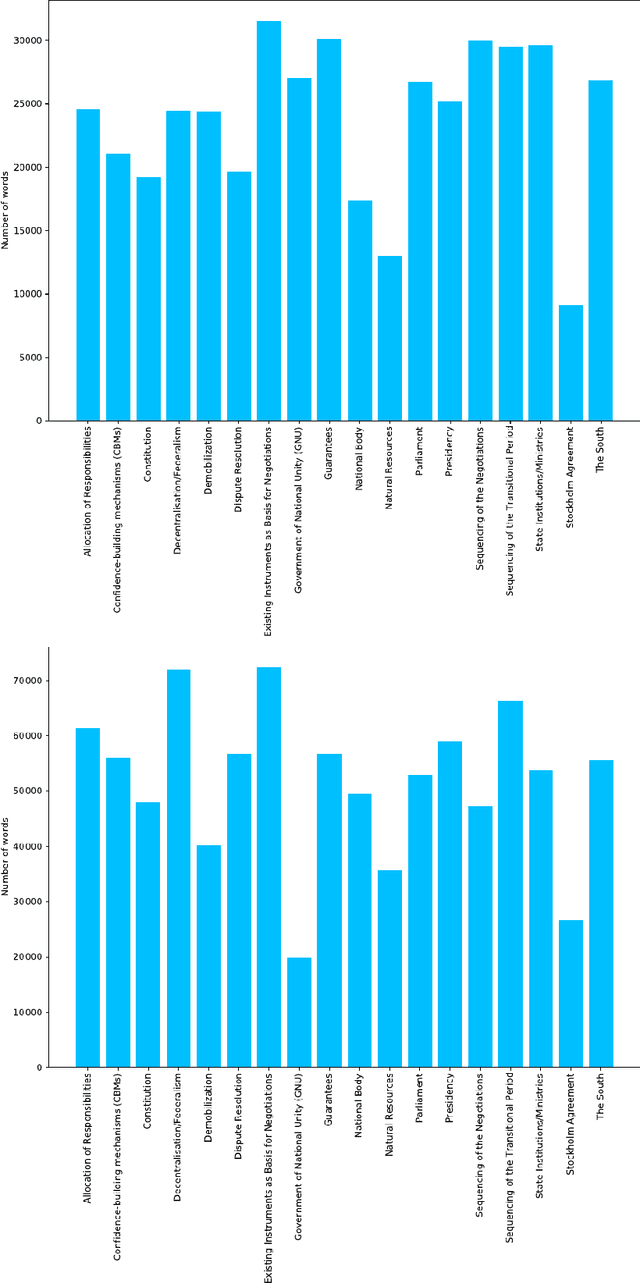
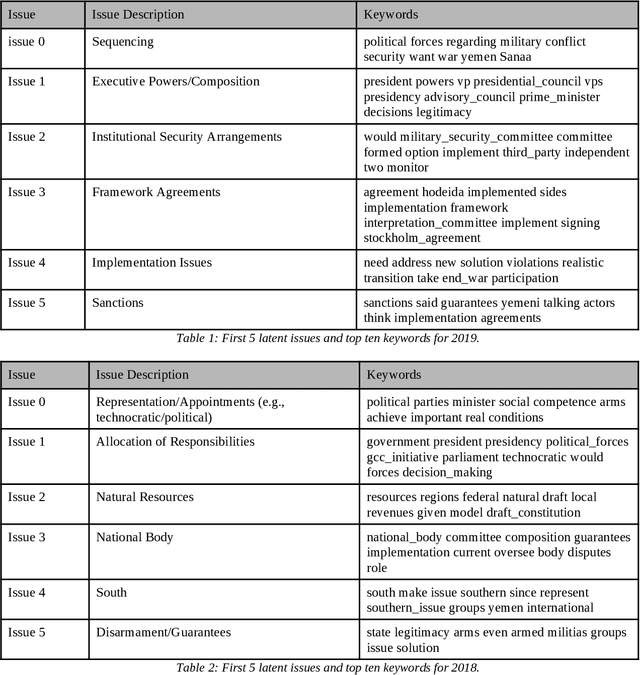
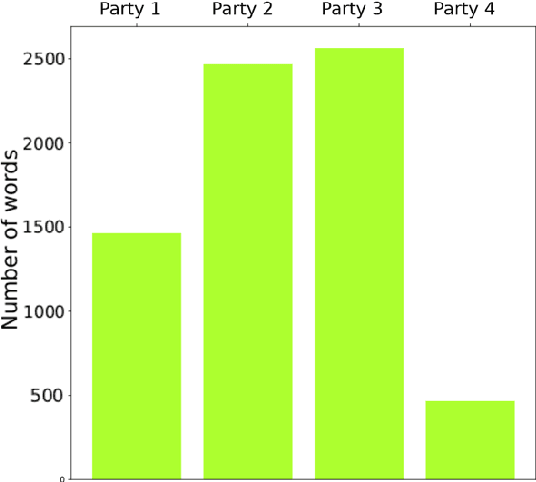
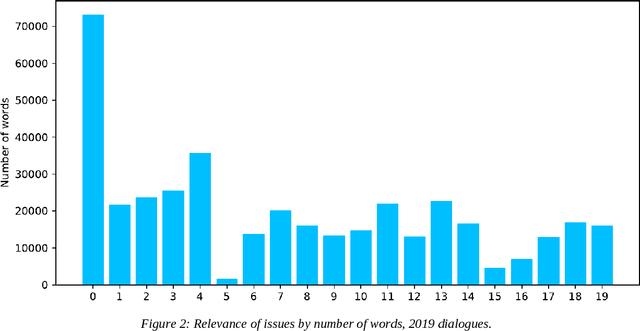
Today's conflicts are becoming increasingly complex, fluid and fragmented, often involving a host of national and international actors with multiple and often divergent interests. This development poses significant challenges for conflict mediation, as mediators struggle to make sense of conflict dynamics, such as the range of conflict parties and the evolution of their political positions, the distinction between relevant and less relevant actors in peace-making, or the identification of key conflict issues and their interdependence. International peace efforts appear ill-equipped to successfully address these challenges. While technology is already being experimented with and used in a range of conflict related fields, such as conflict predicting or information gathering, less attention has been given to how technology can contribute to conflict mediation. This case study contributes to emerging research on the use of state-of-the-art machine learning technologies and techniques in conflict mediation processes. Using dialogue transcripts from peace negotiations in Yemen, this study shows how machine-learning can effectively support mediating teams by providing them with tools for knowledge management, extraction and conflict analysis. Apart from illustrating the potential of machine learning tools in conflict mediation, the paper also emphasises the importance of interdisciplinary and participatory, co-creation methodology for the development of context-sensitive and targeted tools and to ensure meaningful and responsible implementation.
Disentangled Learning of Stance and Aspect Topics for Vaccine Attitude Detection in Social Media
May 06, 2022
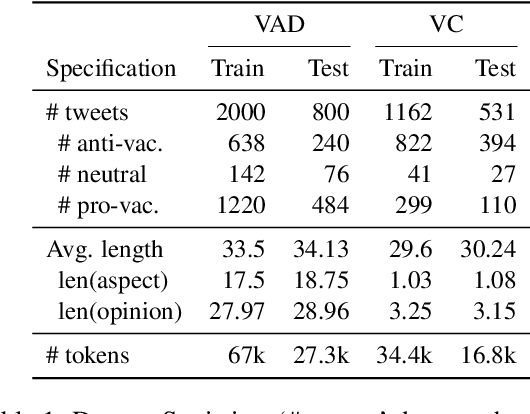
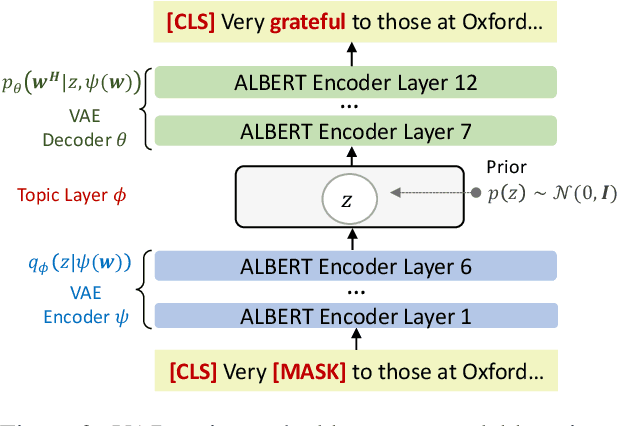
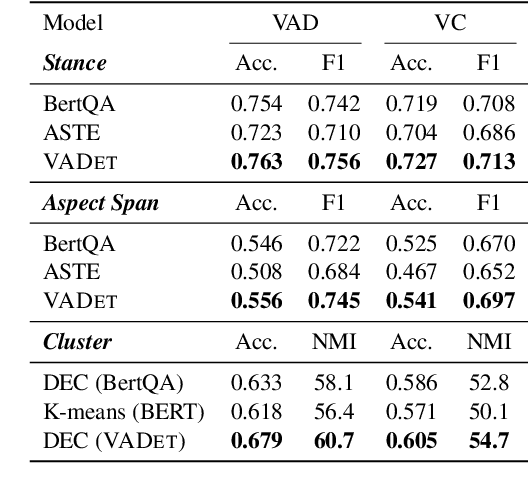
Building models to detect vaccine attitudes on social media is challenging because of the composite, often intricate aspects involved, and the limited availability of annotated data. Existing approaches have relied heavily on supervised training that requires abundant annotations and pre-defined aspect categories. Instead, with the aim of leveraging the large amount of unannotated data now available on vaccination, we propose a novel semi-supervised approach for vaccine attitude detection, called VADet. A variational autoencoding architecture based on language models is employed to learn from unlabelled data the topical information of the domain. Then, the model is fine-tuned with a few manually annotated examples of user attitudes. We validate the effectiveness of VADet on our annotated data and also on an existing vaccination corpus annotated with opinions on vaccines. Our results show that VADet is able to learn disentangled stance and aspect topics, and outperforms existing aspect-based sentiment analysis models on both stance detection and tweet clustering.
Natural Language Inference with Self-Attention for Veracity Assessment of Pandemic Claims
May 05, 2022
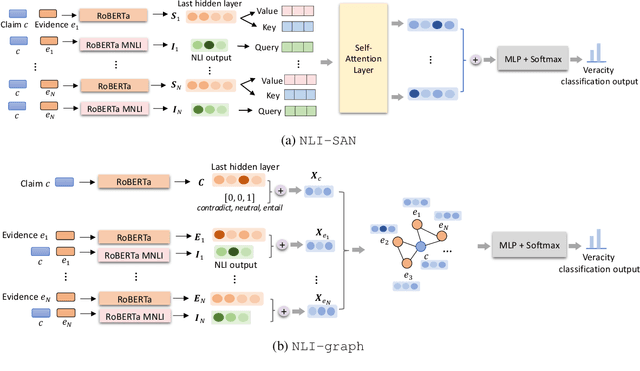

We present a comprehensive work on automated veracity assessment from dataset creation to developing novel methods based on Natural Language Inference (NLI), focusing on misinformation related to the COVID-19 pandemic. We first describe the construction of the novel PANACEA dataset consisting of heterogeneous claims on COVID-19 and their respective information sources. The dataset construction includes work on retrieval techniques and similarity measurements to ensure a unique set of claims. We then propose novel techniques for automated veracity assessment based on Natural Language Inference including graph convolutional networks and attention based approaches. We have carried out experiments on evidence retrieval and veracity assessment on the dataset using the proposed techniques and found them competitive with SOTA methods, and provided a detailed discussion.
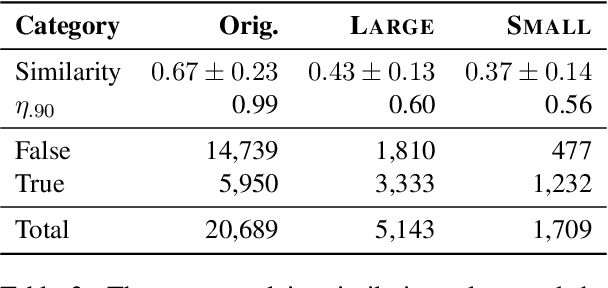
Using Computational Grounded Theory to Understand Tutors' Experiences in the Gig Economy
Jan 24, 2022


The introduction of online marketplace platforms has led to the advent of new forms of flexible, on-demand (or 'gig') work. Yet, most prior research concerning the experience of gig workers examines delivery or crowdsourcing platforms, while the experience of the large numbers of workers who undertake educational labour in the form of tutoring gigs remains understudied. To address this, we use a computational grounded theory approach to analyse tutors' discussions on Reddit. This approach consists of three phases including data exploration, modelling and human-centred interpretation. We use both validation and human evaluation to increase the trustworthiness and reliability of the computational methods. This paper is a work in progress and reports on the first of the three phases of this approach.
Evaluating the application of NLP tools in mainstream participatory budgeting processes in Scotland
Nov 23, 2021In recent years participatory budgeting (PB) in Scotland has grown from a handful of community-led processes to a movement supported by local and national government. This is epitomized by an agreement between the Scottish Government and the Convention of Scottish Local Authorities (COSLA) that at least 1% of local authority budgets will be subject to PB. This ongoing research paper explores the challenges that emerge from this 'scaling up' or 'mainstreaming' across the 32 local authorities that make up Scotland. The main objective is to evaluate local authority use of the digital platform Consul, which applies Natural Language Processing (NLP) to address these challenges. This project adopts a qualitative longitudinal design with interviews, observations of PB processes, and analysis of the digital platform data. Thematic analysis is employed to capture the major issues and themes which emerge. Longitudinal analysis then explores how these evolve over time. The potential for 32 live study sites provides a unique opportunity to explore discrete political and social contexts which materialize and allow for a deeper dive into the challenges and issues that may exist, something a wider cross-sectional study would miss. Initial results show that issues and challenges which come from scaling up may be tackled using NLP technology which, in a previous controlled use case-based evaluation, has shown to improve the effectiveness of citizen participation.
Evaluation of Abstractive Summarisation Models with Machine Translation in Deliberative Processes
Oct 12, 2021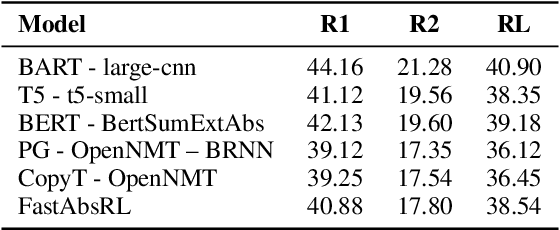
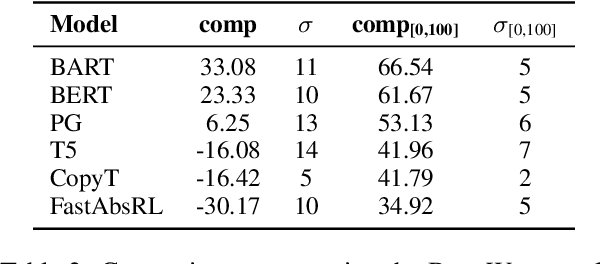
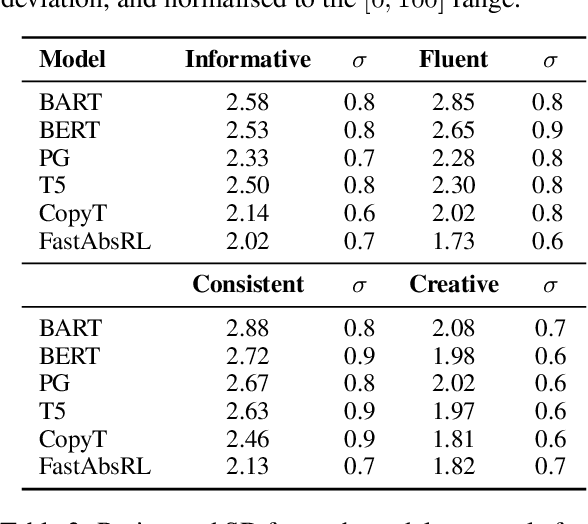
We present work on summarising deliberative processes for non-English languages. Unlike commonly studied datasets, such as news articles, this deliberation dataset reflects difficulties of combining multiple narratives, mostly of poor grammatical quality, in a single text. We report an extensive evaluation of a wide range of abstractive summarisation models in combination with an off-the-shelf machine translation model. Texts are translated into English, summarised, and translated back to the original language. We obtain promising results regarding the fluency, consistency and relevance of the summaries produced. Our approach is easy to implement for many languages for production purposes by simply changing the translation model.
A mixed-methods ethnographic approach to participatory budgeting in Scotland
Sep 20, 2021Participatory budgeting (PB) is already well established in Scotland in the form of community led grant-making yet has recently transformed from a grass-roots activity to a mainstream process or embedded 'policy instrument'. An integral part of this turn is the use of the Consul digital platform as the primary means of citizen participation. Using a mixed method approach, this ongoing research paper explores how each of the 32 local authorities that make up Scotland utilise the Consul platform to engage their citizens in the PB process and how they then make sense of citizens' contributions. In particular, we focus on whether natural language processing (NLP) tools can facilitate both citizen engagement, and the processes by which citizens' contributions are analysed and translated into policies.