 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel, Human-in-the-Loop Computational Grounded Theory Framework for Big Social Data
Jun 06, 2025The availability of big data has significantly influenced the possibilities and methodological choices for conducting large-scale behavioural and social science research. In the context of qualitative data analysis, a major challenge is that conventional methods require intensive manual labour and are often impractical to apply to large datasets. One effective way to address this issue is by integrating emerging computational methods to overcome scalability limitations. However, a critical concern for researchers is the trustworthiness of results when Machine Learning (ML) and Natural Language Processing (NLP) tools are used to analyse such data. We argue that confidence in the credibility and robustness of results depends on adopting a 'human-in-the-loop' methodology that is able to provide researchers with control over the analytical process, while retaining the benefits of using ML and NLP. With this in mind, we propose a novel methodological framework for Computational Grounded Theory (CGT) that supports the analysis of large qualitative datasets, while maintaining the rigour of established Grounded Theory (GT) methodologies. To illustrate the framework's value, we present the results of testing it on a dataset collected from Reddit in a study aimed at understanding tutors' experiences in the gig economy.
Using Computational Grounded Theory to Understand Tutors' Experiences in the Gig Economy
Jan 24, 2022
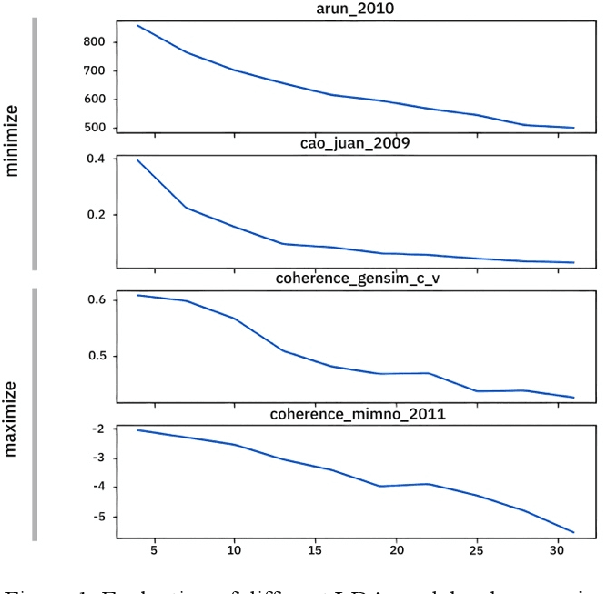


The introduction of online marketplace platforms has led to the advent of new forms of flexible, on-demand (or 'gig') work. Yet, most prior research concerning the experience of gig workers examines delivery or crowdsourcing platforms, while the experience of the large numbers of workers who undertake educational labour in the form of tutoring gigs remains understudied. To address this, we use a computational grounded theory approach to analyse tutors' discussions on Reddit. This approach consists of three phases including data exploration, modelling and human-centred interpretation. We use both validation and human evaluation to increase the trustworthiness and reliability of the computational methods. This paper is a work in progress and reports on the first of the three phases of this approach.
Cost-Sensitive BERT for Generalisable Sentence Classification with Imbalanced Data
Mar 16, 2020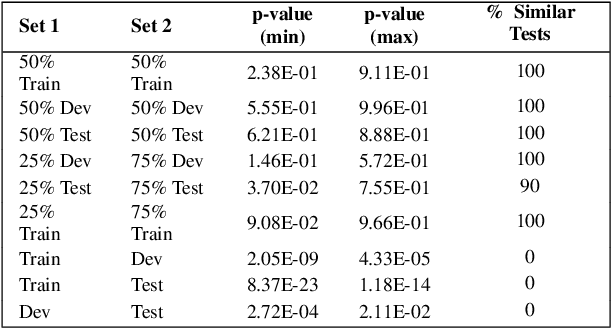

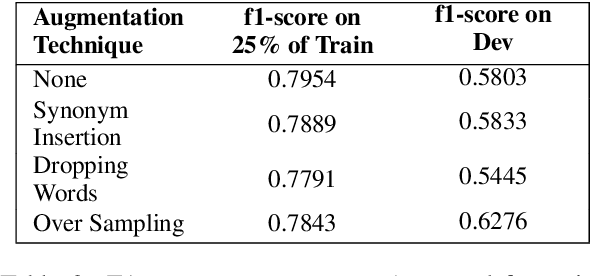
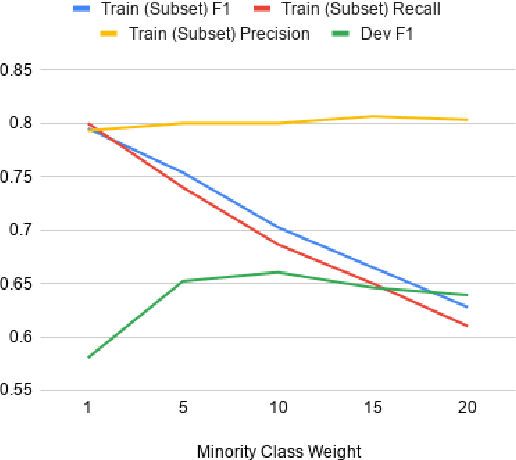
The automatic identification of propaganda has gained significance in recent years due to technological and social changes in the way news is generated and consumed. That this task can be addressed effectively using BERT, a powerful new architecture which can be fine-tuned for text classification tasks, is not surprising. However, propaganda detection, like other tasks that deal with news documents and other forms of decontextualized social communication (e.g. sentiment analysis), inherently deals with data whose categories are simultaneously imbalanced and dissimilar. We show that BERT, while capable of handling imbalanced classes with no additional data augmentation, does not generalise well when the training and test data are sufficiently dissimilar (as is often the case with news sources, whose topics evolve over time). We show how to address this problem by providing a statistical measure of similarity between datasets and a method of incorporating cost-weighting into BERT when the training and test sets are dissimilar. We test these methods on the Propaganda Techniques Corpus (PTC) and achieve the second-highest score on sentence-level propaganda classification.