 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompetitive Audio-Language Models with Data-Efficient Single-Stage Training on Public Data
Sep 09, 2025Large language models (LLMs) have transformed NLP, yet their integration with audio remains underexplored -- despite audio's centrality to human communication. We introduce Falcon3-Audio, a family of Audio-Language Models (ALMs) built on instruction-tuned LLMs and Whisper encoders. Using a remarkably small amount of public audio data -- less than 30K hours (5K unique) -- Falcon3-Audio-7B matches the best reported performance among open-weight models on the MMAU benchmark, with a score of 64.14, matching R1-AQA, while distinguishing itself through superior data and parameter efficiency, single-stage training, and transparency. Notably, our smallest 1B model remains competitive with larger open models ranging from 2B to 13B parameters. Through extensive ablations, we find that common complexities -- such as curriculum learning, multiple audio encoders, and intricate cross-attention connectors -- are not required for strong performance, even compared to models trained on over 500K hours of data.
Learning Video Models from Text: Zero-Shot Anticipation for Procedural Actions
Jun 06, 2021
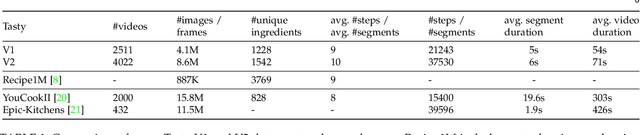
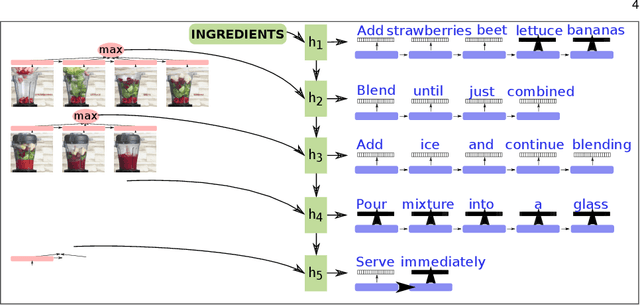
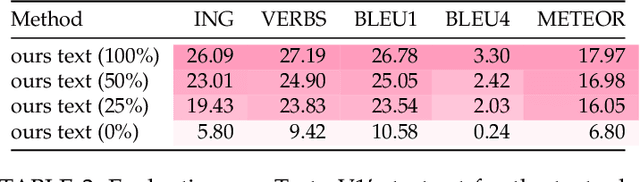
Can we teach a robot to recognize and make predictions for activities that it has never seen before? We tackle this problem by learning models for video from text. This paper presents a hierarchical model that generalizes instructional knowledge from large-scale text-corpora and transfers the knowledge to video. Given a portion of an instructional video, our model recognizes and predicts coherent and plausible actions multiple steps into the future, all in rich natural language. To demonstrate the capabilities of our model, we introduce the \emph{Tasty Videos Dataset V2}, a collection of 4022 recipes for zero-shot learning, recognition and anticipation. Extensive experiments with various evaluation metrics demonstrate the potential of our method for generalization, given limited video data for training models.