 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Suitable Are Subword Segmentation Strategies for Translating Non-Concatenative Morphology?
Sep 02, 2021
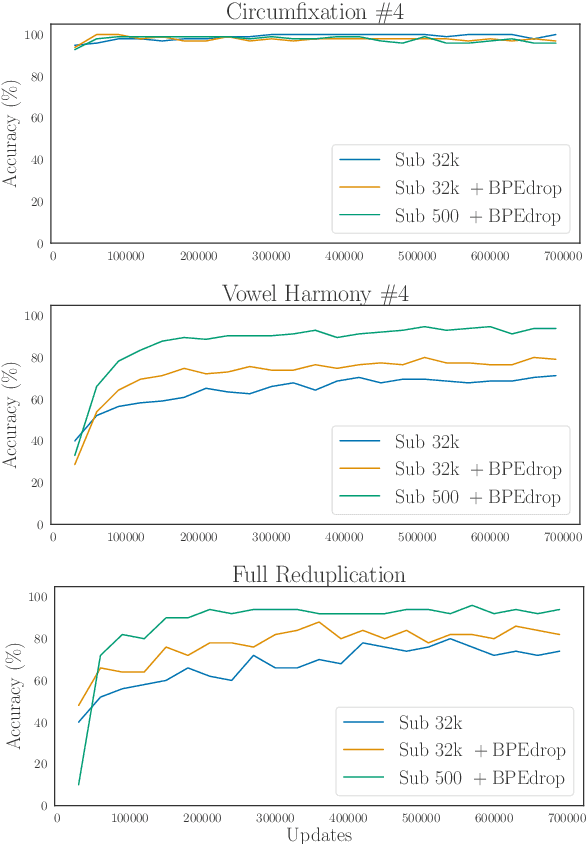

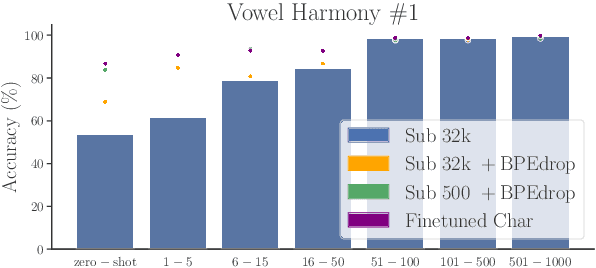
Data-driven subword segmentation has become the default strategy for open-vocabulary machine translation and other NLP tasks, but may not be sufficiently generic for optimal learning of non-concatenative morphology. We design a test suite to evaluate segmentation strategies on different types of morphological phenomena in a controlled, semi-synthetic setting. In our experiments, we compare how well machine translation models trained on subword- and character-level can translate these morphological phenomena. We find that learning to analyse and generate morphologically complex surface representations is still challenging, especially for non-concatenative morphological phenomena like reduplication or vowel harmony and for rare word stems. Based on our results, we recommend that novel text representation strategies be tested on a range of typologically diverse languages to minimise the risk of adopting a strategy that inadvertently disadvantages certain languages.
Revisiting Negation in Neural Machine Translation
Jul 26, 2021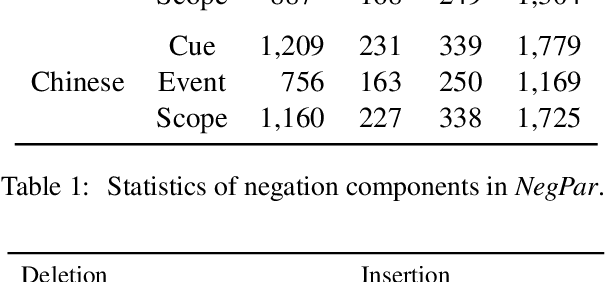
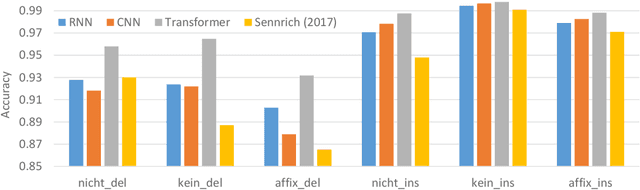

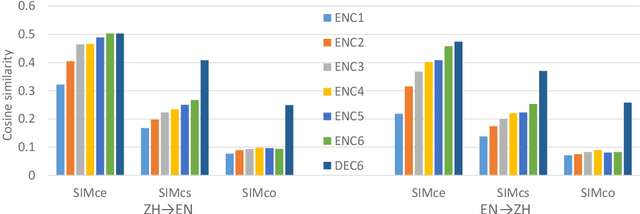
In this paper, we evaluate the translation of negation both automatically and manually, in English--German (EN--DE) and English--Chinese (EN--ZH). We show that the ability of neural machine translation (NMT) models to translate negation has improved with deeper and more advanced networks, although the performance varies between language pairs and translation directions. The accuracy of manual evaluation in EN-DE, DE-EN, EN-ZH, and ZH-EN is 95.7%, 94.8%, 93.4%, and 91.7%, respectively. In addition, we show that under-translation is the most significant error type in NMT, which contrasts with the more diverse error profile previously observed for statistical machine translation. To better understand the root of the under-translation of negation, we study the model's information flow and training data. While our information flow analysis does not reveal any deficiencies that could be used to detect or fix the under-translation of negation, we find that negation is often rephrased during training, which could make it more difficult for the model to learn a reliable link between source and target negation. We finally conduct intrinsic analysis and extrinsic probing tasks on negation, showing that NMT models can distinguish negation and non-negation tokens very well and encode a lot of information about negation in hidden states but nevertheless leave room for improvement.
Understanding the Properties of Minimum Bayes Risk Decoding in Neural Machine Translation
May 18, 2021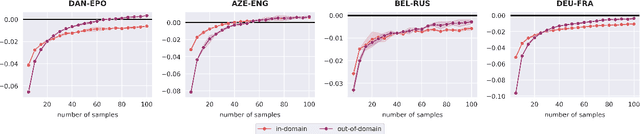
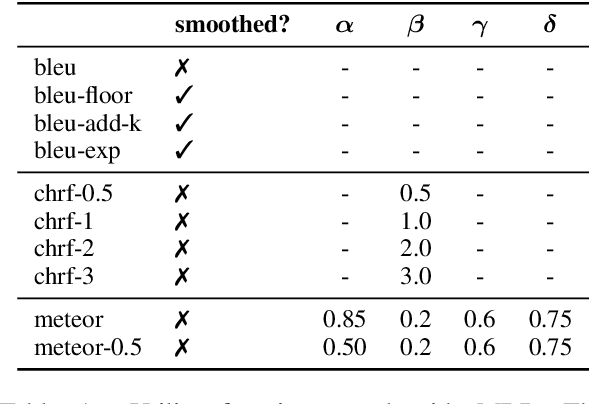
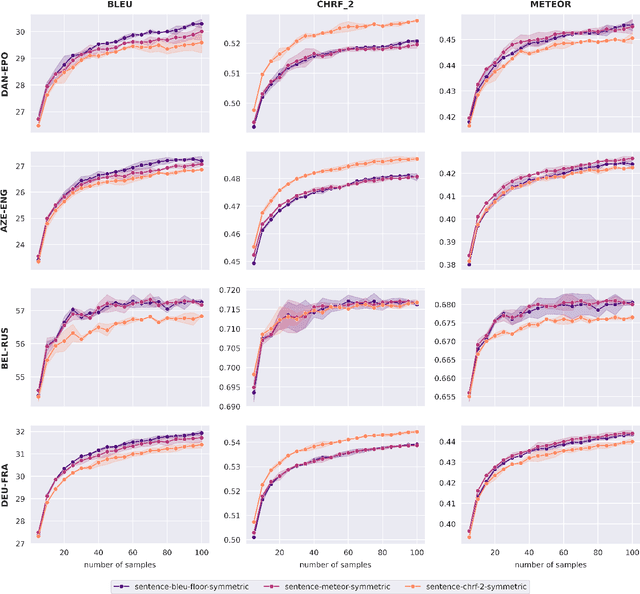
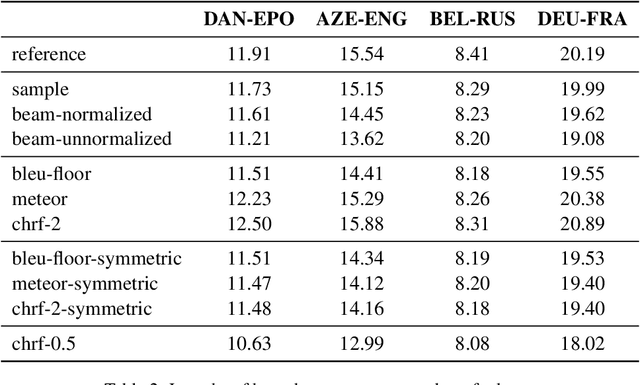
Neural Machine Translation (NMT) currently exhibits biases such as producing translations that are too short and overgenerating frequent words, and shows poor robustness to copy noise in training data or domain shift. Recent work has tied these shortcomings to beam search -- the de facto standard inference algorithm in NMT -- and Eikema & Aziz (2020) propose to use Minimum Bayes Risk (MBR) decoding on unbiased samples instead. In this paper, we empirically investigate the properties of MBR decoding on a number of previously reported biases and failure cases of beam search. We find that MBR still exhibits a length and token frequency bias, owing to the MT metrics used as utility functions, but that MBR also increases robustness against copy noise in the training data and domain shift.
Sparse Attention with Linear Units
Apr 14, 2021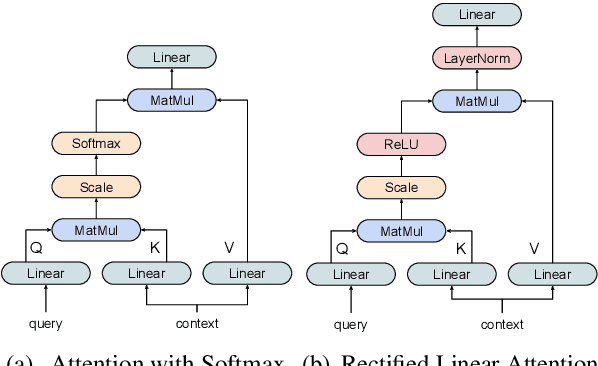
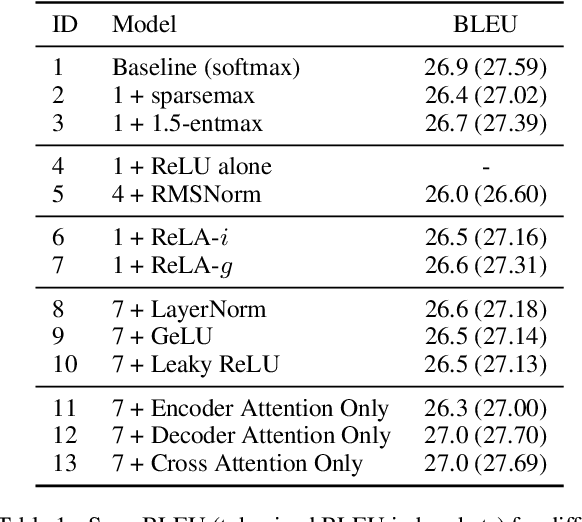
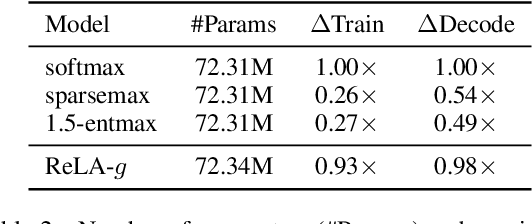
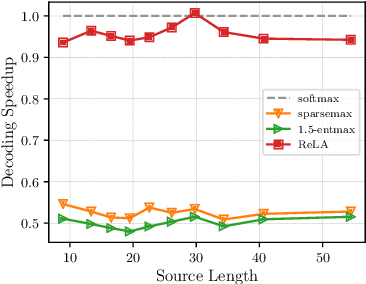
Recently, it has been argued that encoder-decoder models can be made more interpretable by replacing the softmax function in the attention with its sparse variants. In this work, we introduce a novel, simple method for achieving sparsity in attention: we replace the softmax activation with a ReLU, and show that sparsity naturally emerges from such a formulation. Training stability is achieved with layer normalization with either a specialized initialization or an additional gating function. Our model, which we call Rectified Linear Attention (ReLA), is easy to implement and more efficient than previously proposed sparse attention mechanisms. We apply ReLA to the Transformer and conduct experiments on five machine translation tasks. ReLA achieves translation performance comparable to several strong baselines, with training and decoding speed similar to that of the vanilla attention. Our analysis shows that ReLA delivers high sparsity rate and head diversity, and the induced cross attention achieves better accuracy with respect to source-target word alignment than recent sparsified softmax-based models. Intriguingly, ReLA heads also learn to attend to nothing (i.e. 'switch off') for some queries, which is not possible with sparsified softmax alternatives.
On Biasing Transformer Attention Towards Monotonicity
Apr 08, 2021
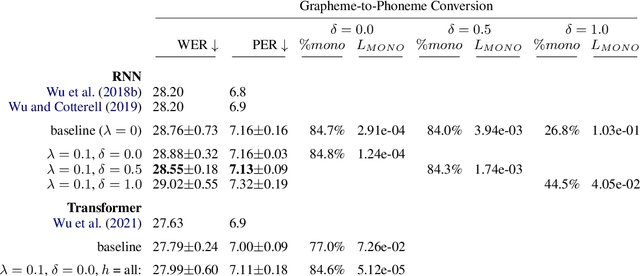

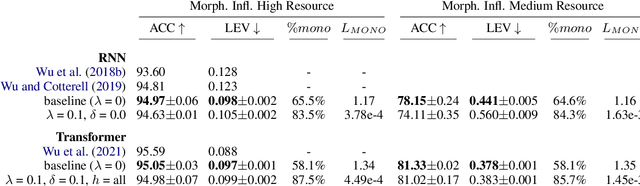
Many sequence-to-sequence tasks in natural language processing are roughly monotonic in the alignment between source and target sequence, and previous work has facilitated or enforced learning of monotonic attention behavior via specialized attention functions or pretraining. In this work, we introduce a monotonicity loss function that is compatible with standard attention mechanisms and test it on several sequence-to-sequence tasks: grapheme-to-phoneme conversion, morphological inflection, transliteration, and dialect normalization. Experiments show that we can achieve largely monotonic behavior. Performance is mixed, with larger gains on top of RNN baselines. General monotonicity does not benefit transformer multihead attention, however, we see isolated improvements when only a subset of heads is biased towards monotonic behavior.
The Impact of Text Presentation on Translator Performance
Nov 11, 2020

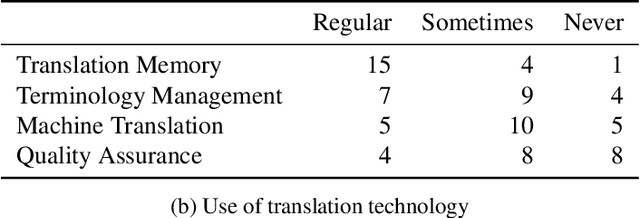
Widely used computer-aided translation (CAT) tools divide documents into segments such as sentences and arrange them in a side-by-side, spreadsheet-like view. We present the first controlled evaluation of these design choices on translator performance, measuring speed and accuracy in three experimental text processing tasks. We find significant evidence that sentence-by-sentence presentation enables faster text reproduction and within-sentence error identification compared to unsegmented text, and that a top-and-bottom arrangement of source and target sentences enables faster text reproduction compared to a side-by-side arrangement. For revision, on the other hand, our results suggest that presenting unsegmented text results in the highest accuracy and time efficiency. Our findings have direct implications for best practices in designing CAT tools.
Understanding Pure Character-Based Neural Machine Translation: The Case of Translating Finnish into English
Nov 06, 2020
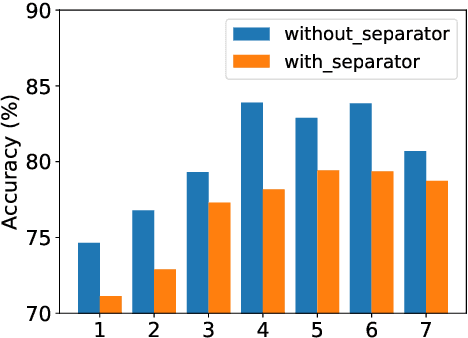

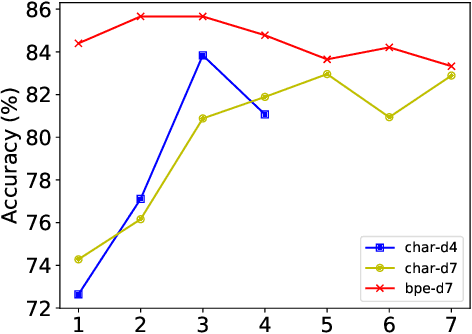
Recent work has shown that deeper character-based neural machine translation (NMT) models can outperform subword-based models. However, it is still unclear what makes deeper character-based models successful. In this paper, we conduct an investigation into pure character-based models in the case of translating Finnish into English, including exploring the ability to learn word senses and morphological inflections and the attention mechanism. We demonstrate that word-level information is distributed over the entire character sequence rather than over a single character, and characters at different positions play different roles in learning linguistic knowledge. In addition, character-based models need more layers to encode word senses which explains why only deeper models outperform subword-based models. The attention distribution pattern shows that separators attract a lot of attention and we explore a sparse word-level attention to enforce character hidden states to capture the full word-level information. Experimental results show that the word-level attention with a single head results in 1.2 BLEU points drop.
Detecting Word Sense Disambiguation Biases in Machine Translation for Model-Agnostic Adversarial Attacks
Nov 03, 2020
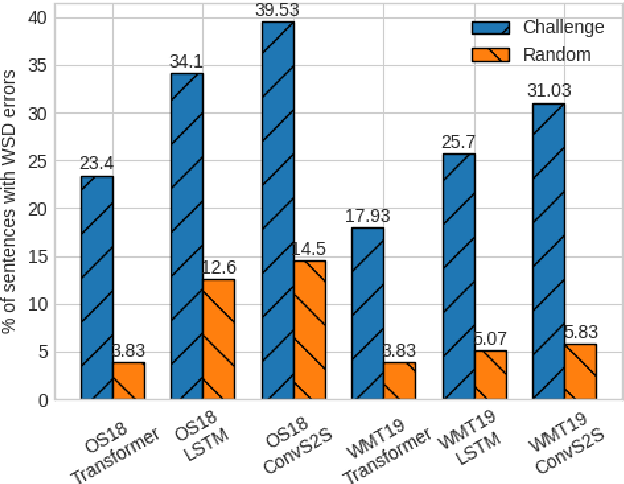
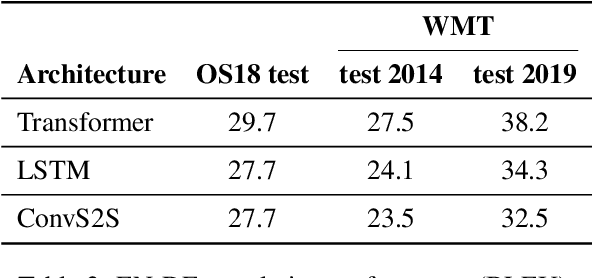
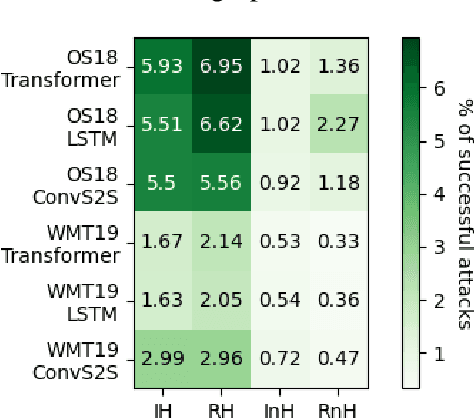
Word sense disambiguation is a well-known source of translation errors in NMT. We posit that some of the incorrect disambiguation choices are due to models' over-reliance on dataset artifacts found in training data, specifically superficial word co-occurrences, rather than a deeper understanding of the source text. We introduce a method for the prediction of disambiguation errors based on statistical data properties, demonstrating its effectiveness across several domains and model types. Moreover, we develop a simple adversarial attack strategy that minimally perturbs sentences in order to elicit disambiguation errors to further probe the robustness of translation models. Our findings indicate that disambiguation robustness varies substantially between domains and that different models trained on the same data are vulnerable to different attacks.
Subword Segmentation and a Single Bridge Language Affect Zero-Shot Neural Machine Translation
Nov 03, 2020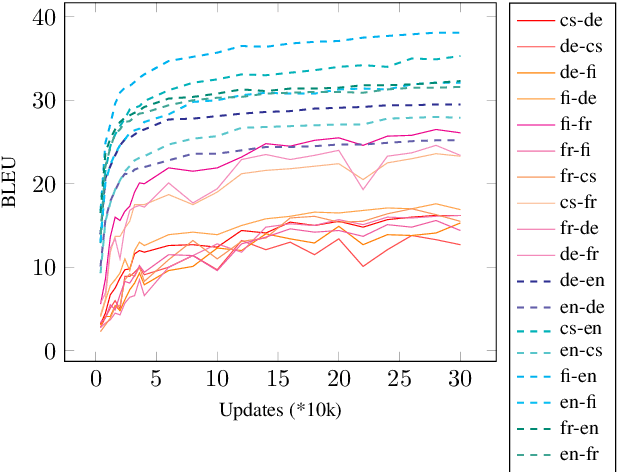
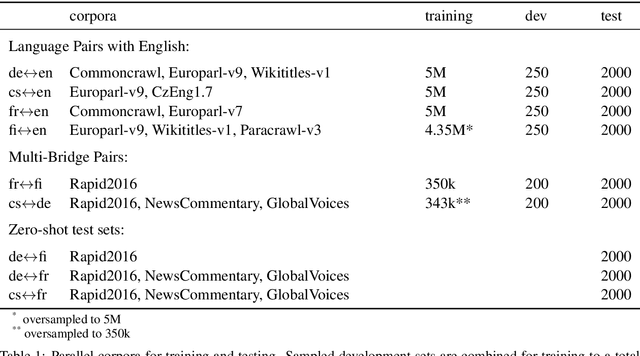
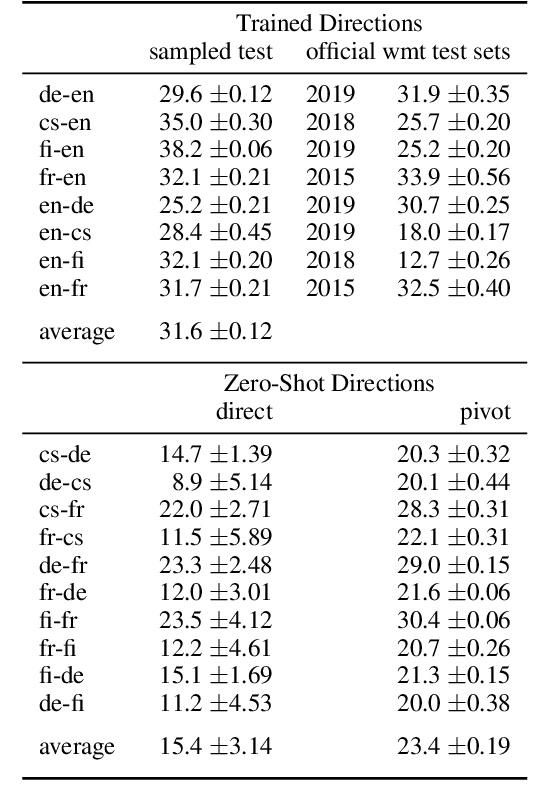
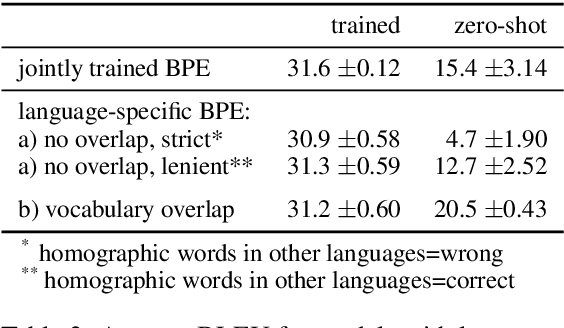
Zero-shot neural machine translation is an attractive goal because of the high cost of obtaining data and building translation systems for new translation directions. However, previous papers have reported mixed success in zero-shot translation. It is hard to predict in which settings it will be effective, and what limits performance compared to a fully supervised system. In this paper, we investigate zero-shot performance of a multilingual EN$\leftrightarrow${FR,CS,DE,FI} system trained on WMT data. We find that zero-shot performance is highly unstable and can vary by more than 6 BLEU between training runs, making it difficult to reliably track improvements. We observe a bias towards copying the source in zero-shot translation, and investigate how the choice of subword segmentation affects this bias. We find that language-specific subword segmentation results in less subword copying at training time, and leads to better zero-shot performance compared to jointly trained segmentation. A recent trend in multilingual models is to not train on parallel data between all language pairs, but have a single bridge language, e.g. English. We find that this negatively affects zero-shot translation and leads to a failure mode where the model ignores the language tag and instead produces English output in zero-shot directions. We show that this bias towards English can be effectively reduced with even a small amount of parallel data in some of the non-English pairs.
Fast Interleaved Bidirectional Sequence Generation
Oct 27, 2020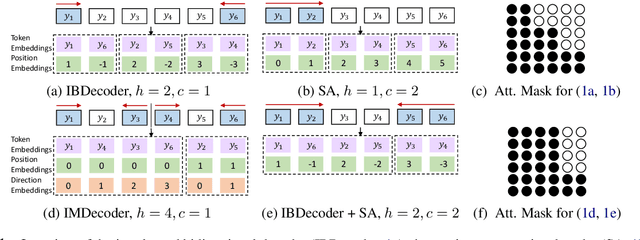
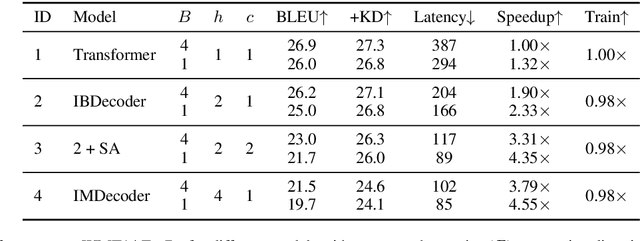

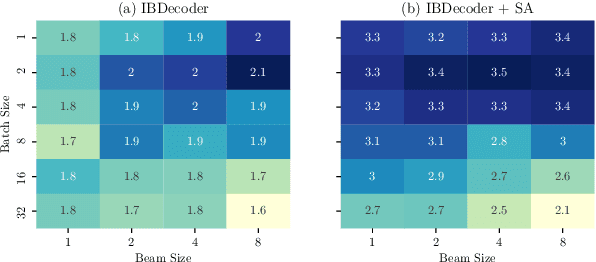
Independence assumptions during sequence generation can speed up inference, but parallel generation of highly inter-dependent tokens comes at a cost in quality. Instead of assuming independence between neighbouring tokens (semi-autoregressive decoding, SA), we take inspiration from bidirectional sequence generation and introduce a decoder that generates target words from the left-to-right and right-to-left directions simultaneously. We show that we can easily convert a standard architecture for unidirectional decoding into a bidirectional decoder by simply interleaving the two directions and adapting the word positions and self-attention masks. Our interleaved bidirectional decoder (IBDecoder) retains the model simplicity and training efficiency of the standard Transformer, and on five machine translation tasks and two document summarization tasks, achieves a decoding speedup of ~2X compared to autoregressive decoding with comparable quality. Notably, it outperforms left-to-right SA because the independence assumptions in IBDecoder are more felicitous. To achieve even higher speedups, we explore hybrid models where we either simultaneously predict multiple neighbouring tokens per direction, or perform multi-directional decoding by partitioning the target sequence. These methods achieve speedups to 4X-11X across different tasks at the cost of <1 BLEU or <0.5 ROUGE (on average). Source code is released at https://github.com/bzhangGo/zero.