 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing and Optimizing LSTM Language Models
Aug 07, 2017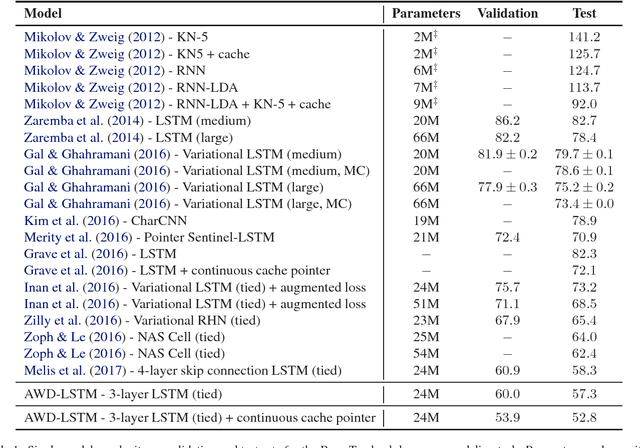

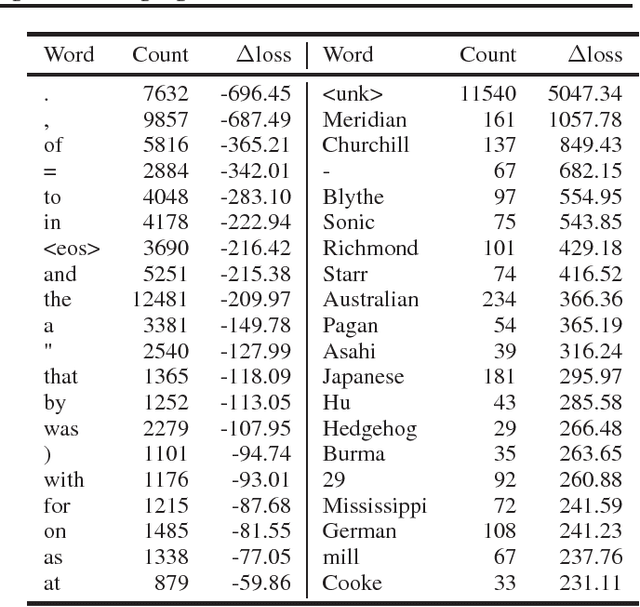
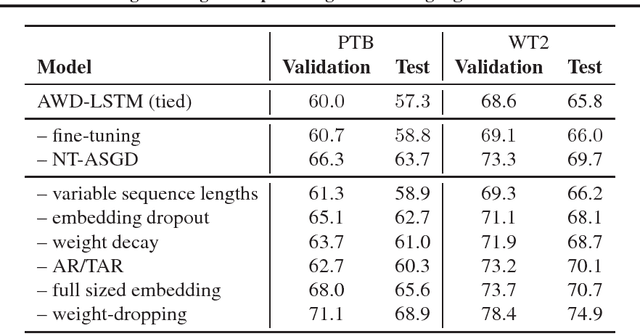
Recurrent neural networks (RNNs), such as long short-term memory networks (LSTMs), serve as a fundamental building block for many sequence learning tasks, including machine translation, language modeling, and question answering. In this paper, we consider the specific problem of word-level language modeling and investigate strategies for regularizing and optimizing LSTM-based models. We propose the weight-dropped LSTM which uses DropConnect on hidden-to-hidden weights as a form of recurrent regularization. Further, we introduce NT-ASGD, a variant of the averaged stochastic gradient method, wherein the averaging trigger is determined using a non-monotonic condition as opposed to being tuned by the user. Using these and other regularization strategies, we achieve state-of-the-art word level perplexities on two data sets: 57.3 on Penn Treebank and 65.8 on WikiText-2. In exploring the effectiveness of a neural cache in conjunction with our proposed model, we achieve an even lower state-of-the-art perplexity of 52.8 on Penn Treebank and 52.0 on WikiText-2.
Revisiting Activation Regularization for Language RNNs
Aug 03, 2017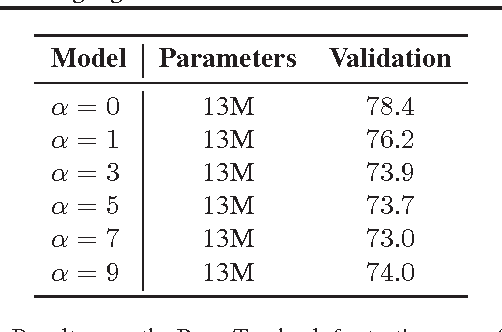
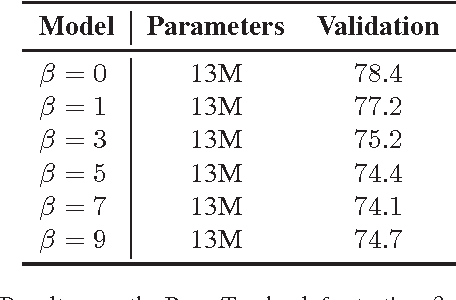


Recurrent neural networks (RNNs) serve as a fundamental building block for many sequence tasks across natural language processing. Recent research has focused on recurrent dropout techniques or custom RNN cells in order to improve performance. Both of these can require substantial modifications to the machine learning model or to the underlying RNN configurations. We revisit traditional regularization techniques, specifically L2 regularization on RNN activations and slowness regularization over successive hidden states, to improve the performance of RNNs on the task of language modeling. Both of these techniques require minimal modification to existing RNN architectures and result in performance improvements comparable or superior to more complicated regularization techniques or custom cell architectures. These regularization techniques can be used without any modification on optimized LSTM implementations such as the NVIDIA cuDNN LSTM.
A Joint Many-Task Model: Growing a Neural Network for Multiple NLP Tasks
Jul 24, 2017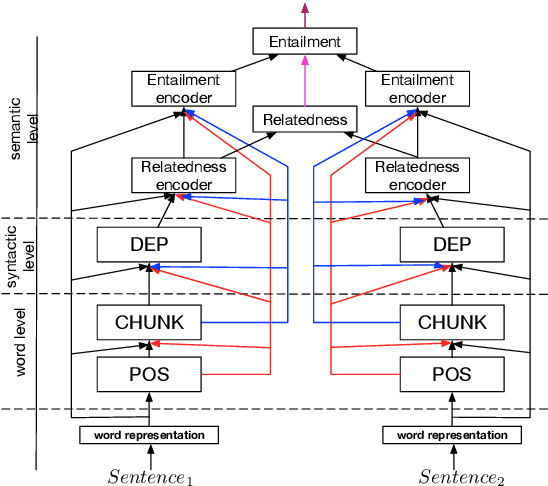
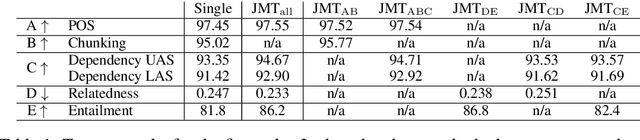
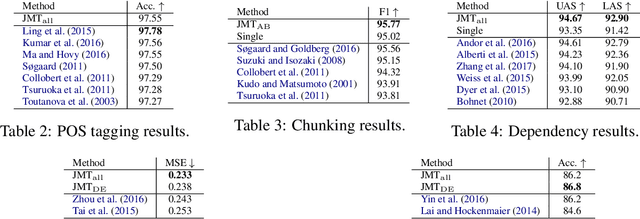
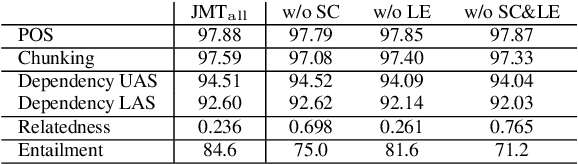
Transfer and multi-task learning have traditionally focused on either a single source-target pair or very few, similar tasks. Ideally, the linguistic levels of morphology, syntax and semantics would benefit each other by being trained in a single model. We introduce a joint many-task model together with a strategy for successively growing its depth to solve increasingly complex tasks. Higher layers include shortcut connections to lower-level task predictions to reflect linguistic hierarchies. We use a simple regularization term to allow for optimizing all model weights to improve one task's loss without exhibiting catastrophic interference of the other tasks. Our single end-to-end model obtains state-of-the-art or competitive results on five different tasks from tagging, parsing, relatedness, and entailment tasks.
Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning
Jun 06, 2017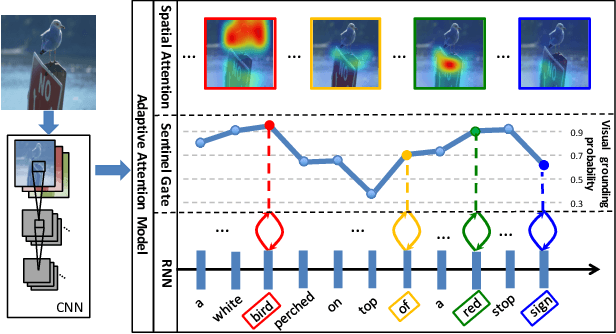
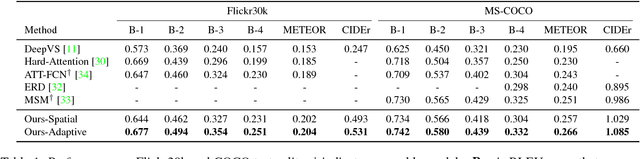
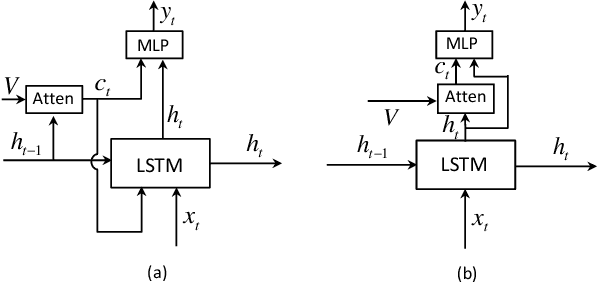
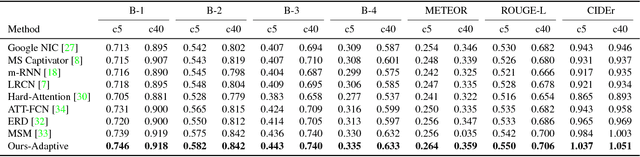
Attention-based neural encoder-decoder frameworks have been widely adopted for image captioning. Most methods force visual attention to be active for every generated word. However, the decoder likely requires little to no visual information from the image to predict non-visual words such as "the" and "of". Other words that may seem visual can often be predicted reliably just from the language model e.g., "sign" after "behind a red stop" or "phone" following "talking on a cell". In this paper, we propose a novel adaptive attention model with a visual sentinel. At each time step, our model decides whether to attend to the image (and if so, to which regions) or to the visual sentinel. The model decides whether to attend to the image and where, in order to extract meaningful information for sequential word generation. We test our method on the COCO image captioning 2015 challenge dataset and Flickr30K. Our approach sets the new state-of-the-art by a significant margin.
Tying Word Vectors and Word Classifiers: A Loss Framework for Language Modeling
Mar 11, 2017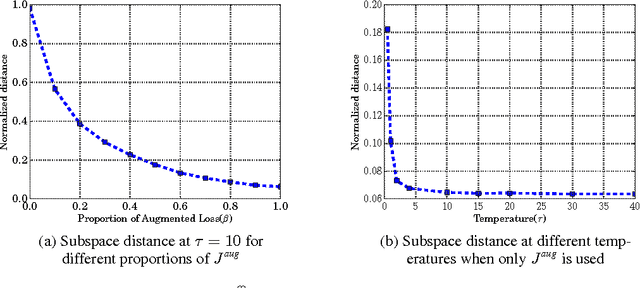
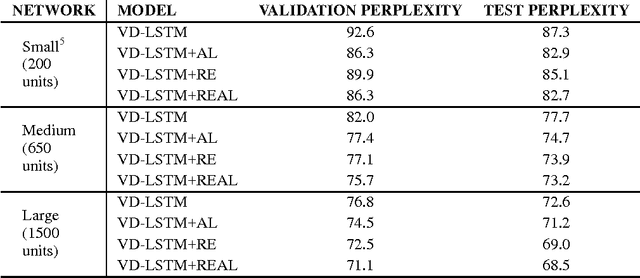
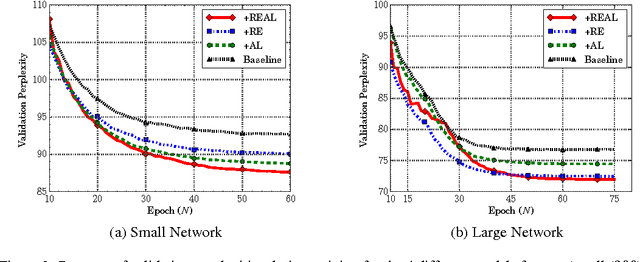
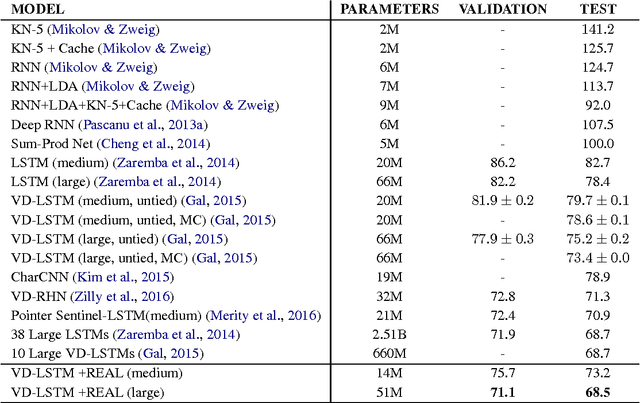
Recurrent neural networks have been very successful at predicting sequences of words in tasks such as language modeling. However, all such models are based on the conventional classification framework, where the model is trained against one-hot targets, and each word is represented both as an input and as an output in isolation. This causes inefficiencies in learning both in terms of utilizing all of the information and in terms of the number of parameters needed to train. We introduce a novel theoretical framework that facilitates better learning in language modeling, and show that our framework leads to tying together the input embedding and the output projection matrices, greatly reducing the number of trainable variables. Our framework leads to state of the art performance on the Penn Treebank with a variety of network models.
A Way out of the Odyssey: Analyzing and Combining Recent Insights for LSTMs
Dec 17, 2016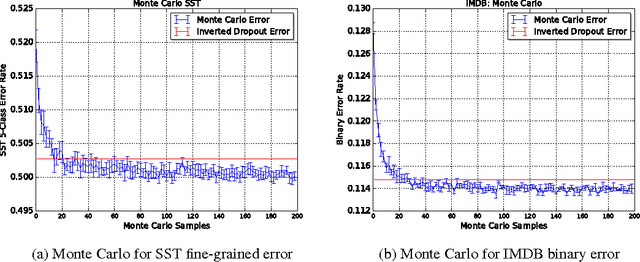
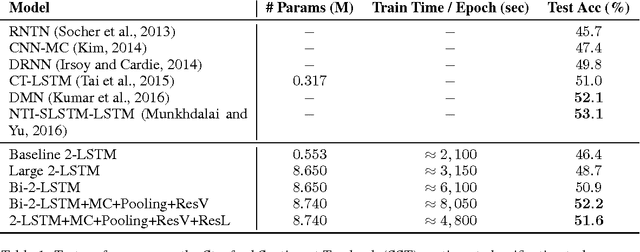
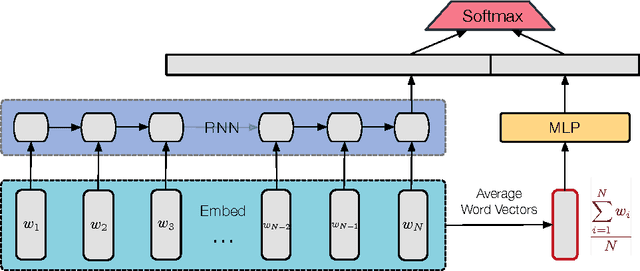
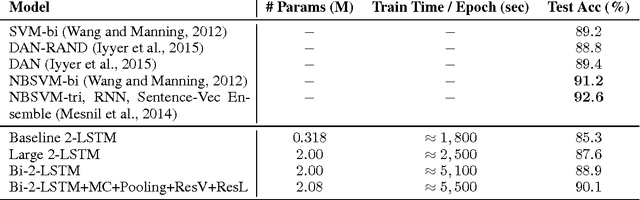
LSTMs have become a basic building block for many deep NLP models. In recent years, many improvements and variations have been proposed for deep sequence models in general, and LSTMs in particular. We propose and analyze a series of augmentations and modifications to LSTM networks resulting in improved performance for text classification datasets. We observe compounding improvements on traditional LSTMs using Monte Carlo test-time model averaging, average pooling, and residual connections, along with four other suggested modifications. Our analysis provides a simple, reliable, and high quality baseline model.
Quasi-Recurrent Neural Networks
Nov 21, 2016
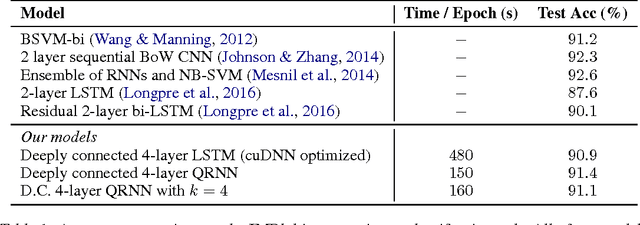
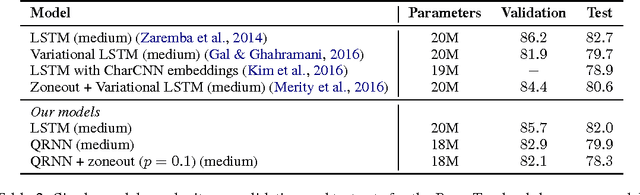
Recurrent neural networks are a powerful tool for modeling sequential data, but the dependence of each timestep's computation on the previous timestep's output limits parallelism and makes RNNs unwieldy for very long sequences. We introduce quasi-recurrent neural networks (QRNNs), an approach to neural sequence modeling that alternates convolutional layers, which apply in parallel across timesteps, and a minimalist recurrent pooling function that applies in parallel across channels. Despite lacking trainable recurrent layers, stacked QRNNs have better predictive accuracy than stacked LSTMs of the same hidden size. Due to their increased parallelism, they are up to 16 times faster at train and test time. Experiments on language modeling, sentiment classification, and character-level neural machine translation demonstrate these advantages and underline the viability of QRNNs as a basic building block for a variety of sequence tasks.
Pointer Sentinel Mixture Models
Sep 26, 2016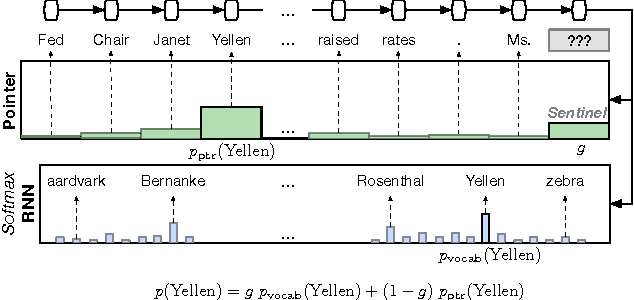
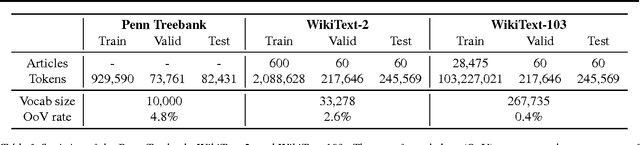
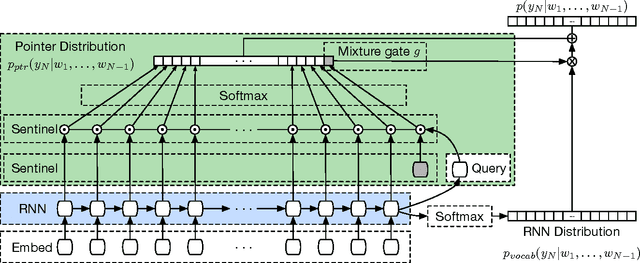
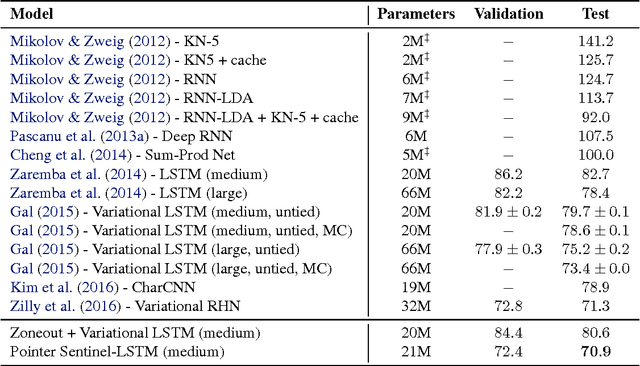
Recent neural network sequence models with softmax classifiers have achieved their best language modeling performance only with very large hidden states and large vocabularies. Even then they struggle to predict rare or unseen words even if the context makes the prediction unambiguous. We introduce the pointer sentinel mixture architecture for neural sequence models which has the ability to either reproduce a word from the recent context or produce a word from a standard softmax classifier. Our pointer sentinel-LSTM model achieves state of the art language modeling performance on the Penn Treebank (70.9 perplexity) while using far fewer parameters than a standard softmax LSTM. In order to evaluate how well language models can exploit longer contexts and deal with more realistic vocabularies and larger corpora we also introduce the freely available WikiText corpus.
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
Mar 05, 2016
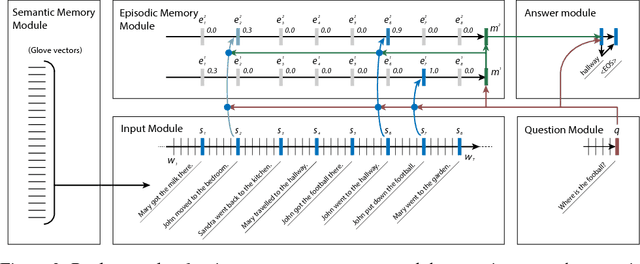
Most tasks in natural language processing can be cast into question answering (QA) problems over language input. We introduce the dynamic memory network (DMN), a neural network architecture which processes input sequences and questions, forms episodic memories, and generates relevant answers. Questions trigger an iterative attention process which allows the model to condition its attention on the inputs and the result of previous iterations. These results are then reasoned over in a hierarchical recurrent sequence model to generate answers. The DMN can be trained end-to-end and obtains state-of-the-art results on several types of tasks and datasets: question answering (Facebook's bAbI dataset), text classification for sentiment analysis (Stanford Sentiment Treebank) and sequence modeling for part-of-speech tagging (WSJ-PTB). The training for these different tasks relies exclusively on trained word vector representations and input-question-answer triplets.
Dynamic Memory Networks for Visual and Textual Question Answering
Mar 04, 2016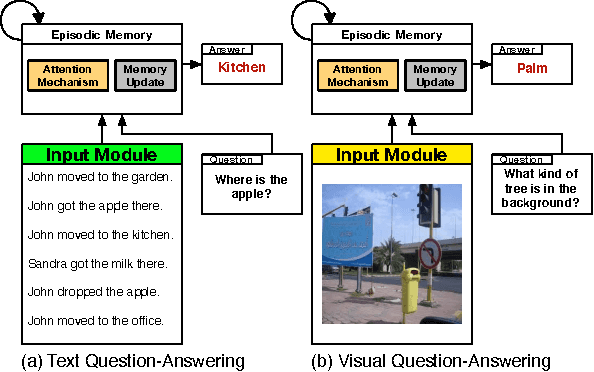
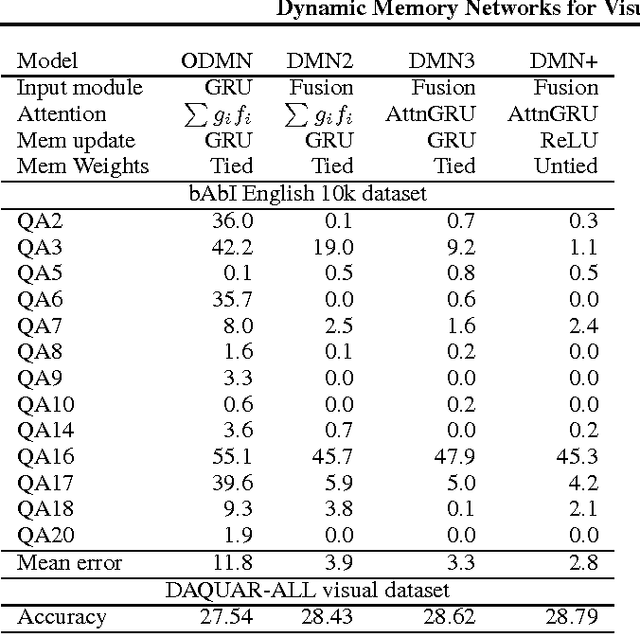
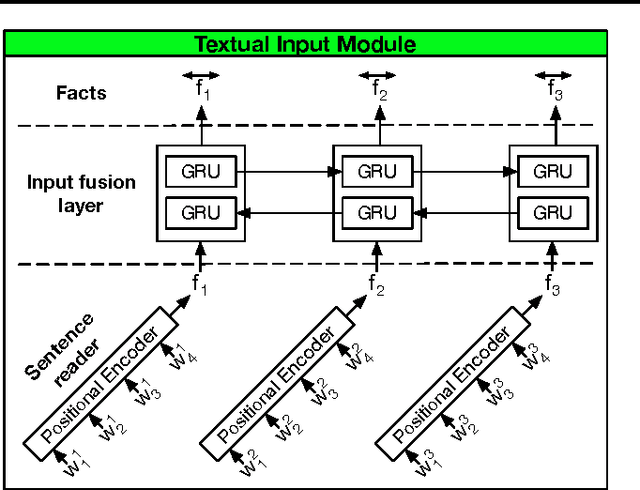
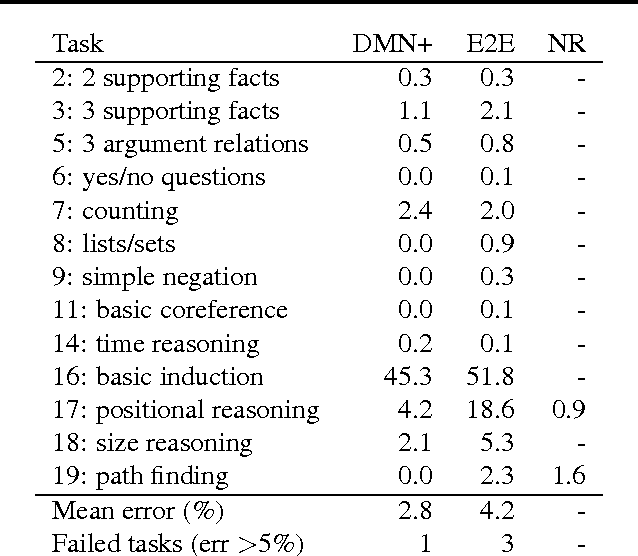
Neural network architectures with memory and attention mechanisms exhibit certain reasoning capabilities required for question answering. One such architecture, the dynamic memory network (DMN), obtained high accuracy on a variety of language tasks. However, it was not shown whether the architecture achieves strong results for question answering when supporting facts are not marked during training or whether it could be applied to other modalities such as images. Based on an analysis of the DMN, we propose several improvements to its memory and input modules. Together with these changes we introduce a novel input module for images in order to be able to answer visual questions. Our new DMN+ model improves the state of the art on both the Visual Question Answering dataset and the \babi-10k text question-answering dataset without supporting fact supervision.