 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Headed Attention RNN: Stop Thinking With Your Head
Nov 27, 2019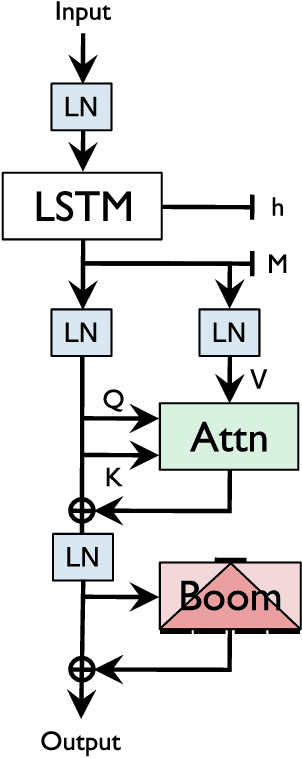
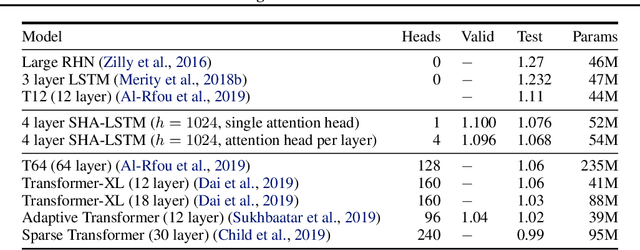
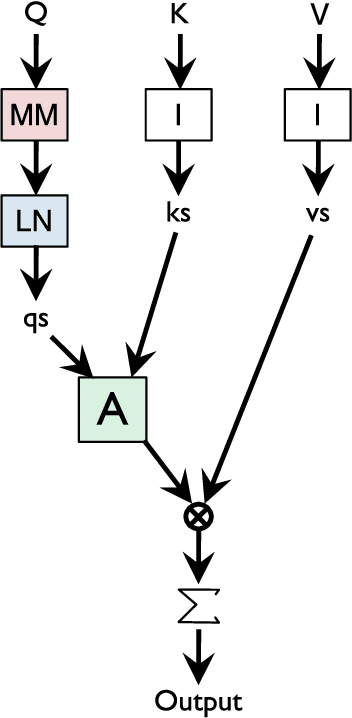
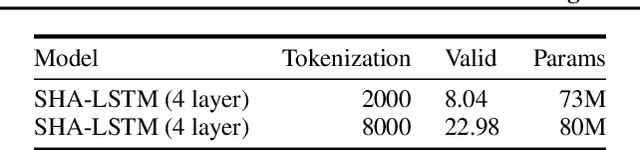
The leading approaches in language modeling are all obsessed with TV shows of my youth - namely Transformers and Sesame Street. Transformers this, Transformers that, and over here a bonfire worth of GPU-TPU-neuromorphic wafer scale silicon. We opt for the lazy path of old and proven techniques with a fancy crypto inspired acronym: the Single Headed Attention RNN (SHA-RNN). The author's lone goal is to show that the entire field might have evolved a different direction if we had instead been obsessed with a slightly different acronym and slightly different result. We take a previously strong language model based only on boring LSTMs and get it to within a stone's throw of a stone's throw of state-of-the-art byte level language model results on enwik8. This work has undergone no intensive hyperparameter optimization and lived entirely on a commodity desktop machine that made the author's small studio apartment far too warm in the midst of a San Franciscan summer. The final results are achievable in plus or minus 24 hours on a single GPU as the author is impatient. The attention mechanism is also readily extended to large contexts with minimal computation. Take that Sesame Street.
An Analysis of Neural Language Modeling at Multiple Scales
Mar 22, 2018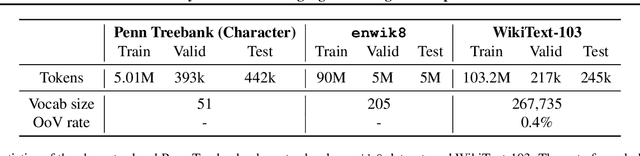
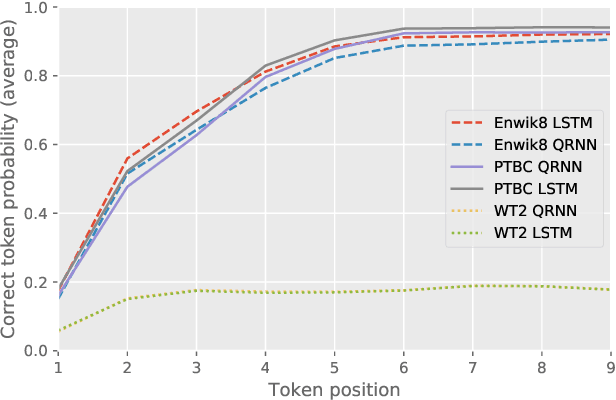
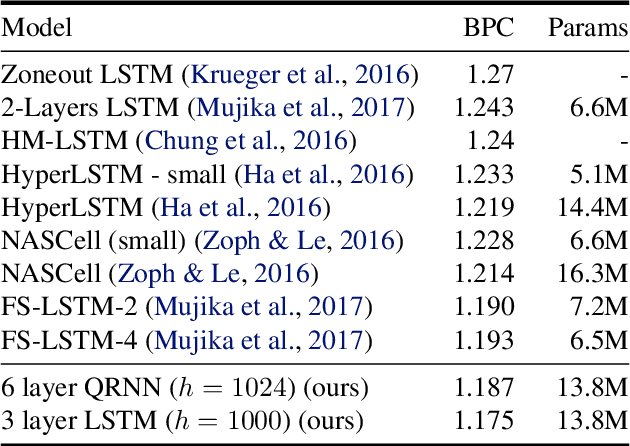
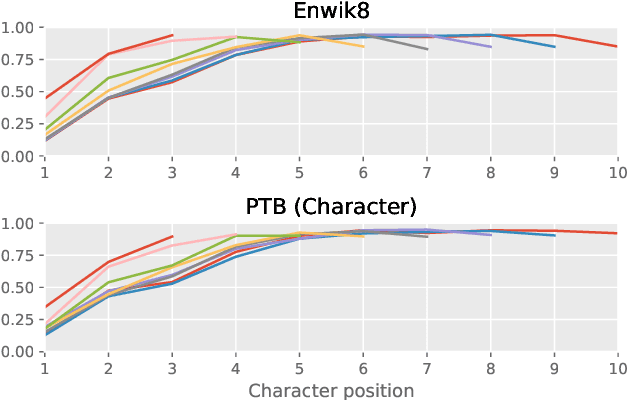
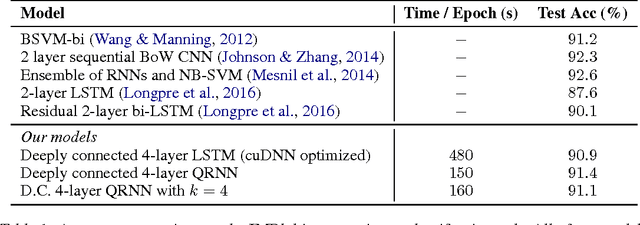
Many of the leading approaches in language modeling introduce novel, complex and specialized architectures. We take existing state-of-the-art word level language models based on LSTMs and QRNNs and extend them to both larger vocabularies as well as character-level granularity. When properly tuned, LSTMs and QRNNs achieve state-of-the-art results on character-level (Penn Treebank, enwik8) and word-level (WikiText-103) datasets, respectively. Results are obtained in only 12 hours (WikiText-103) to 2 days (enwik8) using a single modern GPU.
A Flexible Approach to Automated RNN Architecture Generation
Dec 20, 2017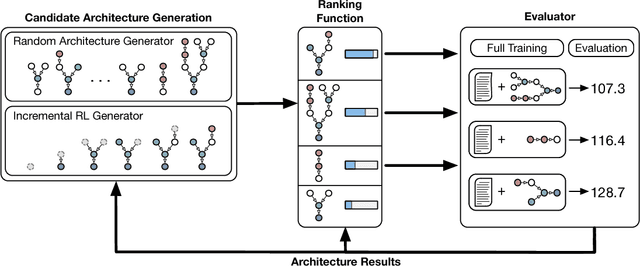
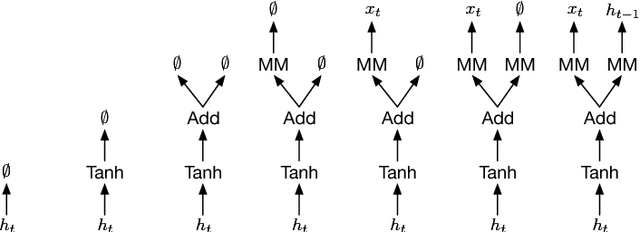

The process of designing neural architectures requires expert knowledge and extensive trial and error. While automated architecture search may simplify these requirements, the recurrent neural network (RNN) architectures generated by existing methods are limited in both flexibility and components. We propose a domain-specific language (DSL) for use in automated architecture search which can produce novel RNNs of arbitrary depth and width. The DSL is flexible enough to define standard architectures such as the Gated Recurrent Unit and Long Short Term Memory and allows the introduction of non-standard RNN components such as trigonometric curves and layer normalization. Using two different candidate generation techniques, random search with a ranking function and reinforcement learning, we explore the novel architectures produced by the RNN DSL for language modeling and machine translation domains. The resulting architectures do not follow human intuition yet perform well on their targeted tasks, suggesting the space of usable RNN architectures is far larger than previously assumed.
Regularizing and Optimizing LSTM Language Models
Aug 07, 2017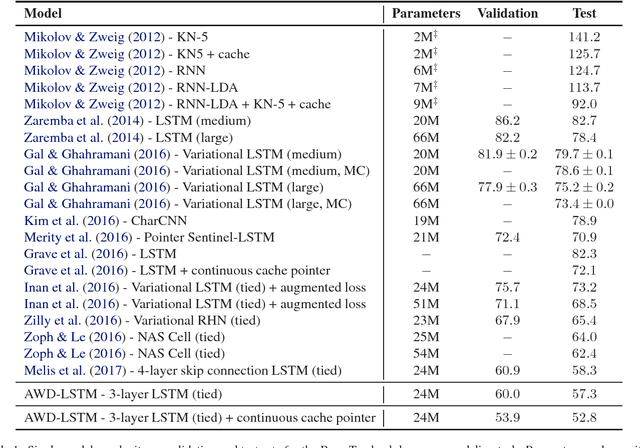

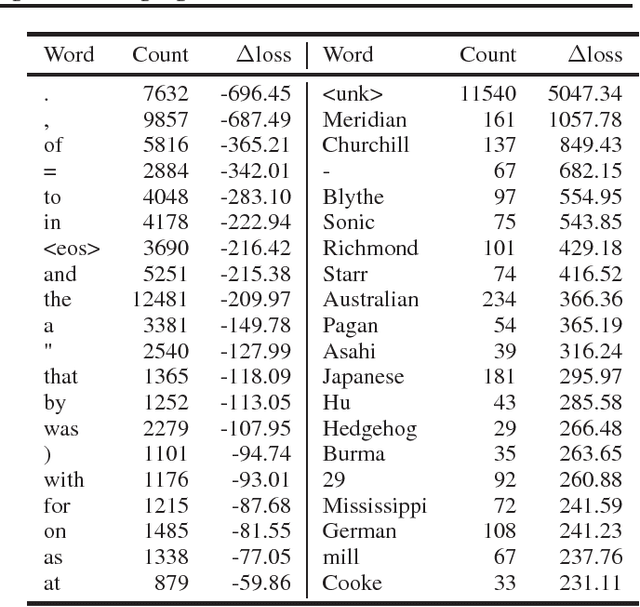
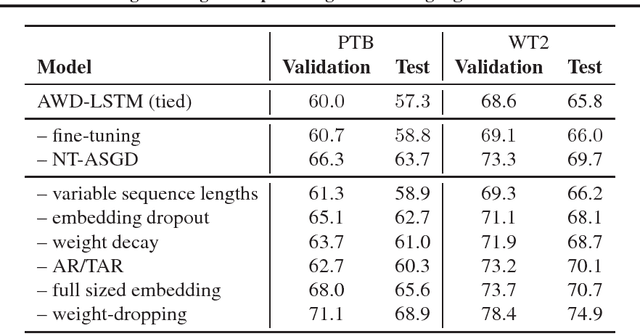
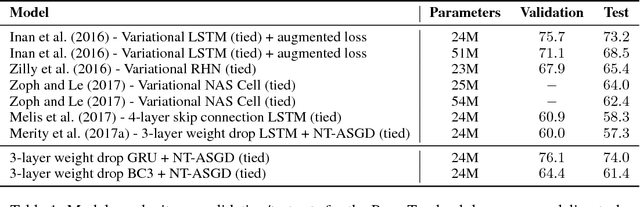
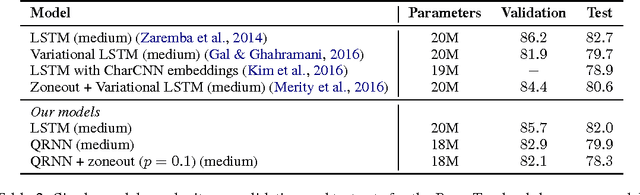
Recurrent neural networks (RNNs), such as long short-term memory networks (LSTMs), serve as a fundamental building block for many sequence learning tasks, including machine translation, language modeling, and question answering. In this paper, we consider the specific problem of word-level language modeling and investigate strategies for regularizing and optimizing LSTM-based models. We propose the weight-dropped LSTM which uses DropConnect on hidden-to-hidden weights as a form of recurrent regularization. Further, we introduce NT-ASGD, a variant of the averaged stochastic gradient method, wherein the averaging trigger is determined using a non-monotonic condition as opposed to being tuned by the user. Using these and other regularization strategies, we achieve state-of-the-art word level perplexities on two data sets: 57.3 on Penn Treebank and 65.8 on WikiText-2. In exploring the effectiveness of a neural cache in conjunction with our proposed model, we achieve an even lower state-of-the-art perplexity of 52.8 on Penn Treebank and 52.0 on WikiText-2.
Revisiting Activation Regularization for Language RNNs
Aug 03, 2017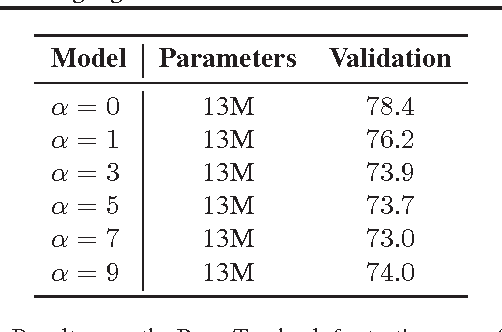
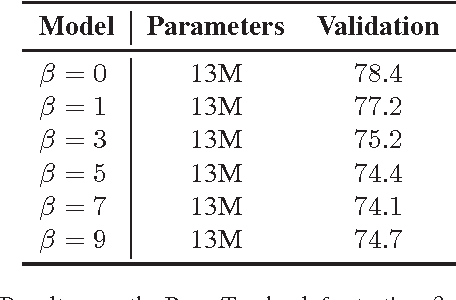


Recurrent neural networks (RNNs) serve as a fundamental building block for many sequence tasks across natural language processing. Recent research has focused on recurrent dropout techniques or custom RNN cells in order to improve performance. Both of these can require substantial modifications to the machine learning model or to the underlying RNN configurations. We revisit traditional regularization techniques, specifically L2 regularization on RNN activations and slowness regularization over successive hidden states, to improve the performance of RNNs on the task of language modeling. Both of these techniques require minimal modification to existing RNN architectures and result in performance improvements comparable or superior to more complicated regularization techniques or custom cell architectures. These regularization techniques can be used without any modification on optimized LSTM implementations such as the NVIDIA cuDNN LSTM.
Quasi-Recurrent Neural Networks
Nov 21, 2016
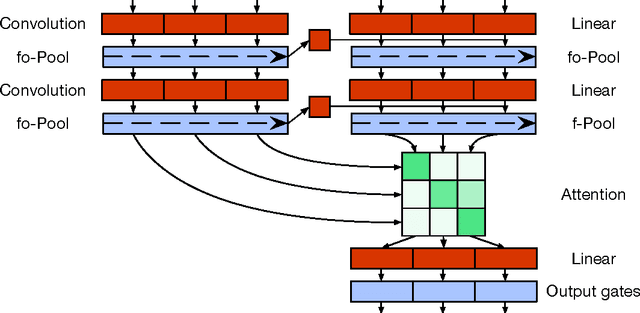
Recurrent neural networks are a powerful tool for modeling sequential data, but the dependence of each timestep's computation on the previous timestep's output limits parallelism and makes RNNs unwieldy for very long sequences. We introduce quasi-recurrent neural networks (QRNNs), an approach to neural sequence modeling that alternates convolutional layers, which apply in parallel across timesteps, and a minimalist recurrent pooling function that applies in parallel across channels. Despite lacking trainable recurrent layers, stacked QRNNs have better predictive accuracy than stacked LSTMs of the same hidden size. Due to their increased parallelism, they are up to 16 times faster at train and test time. Experiments on language modeling, sentiment classification, and character-level neural machine translation demonstrate these advantages and underline the viability of QRNNs as a basic building block for a variety of sequence tasks.
Pointer Sentinel Mixture Models
Sep 26, 2016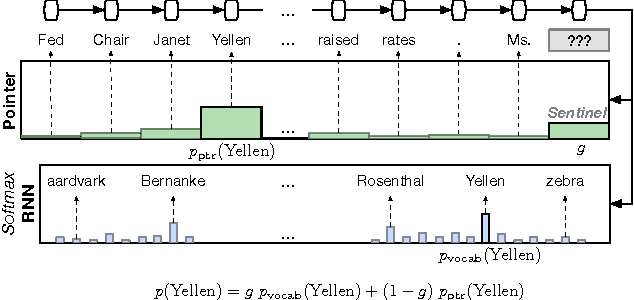
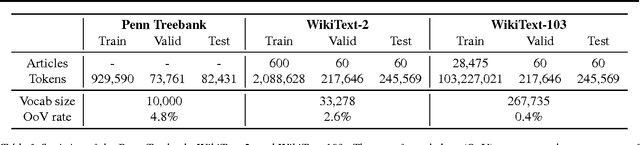
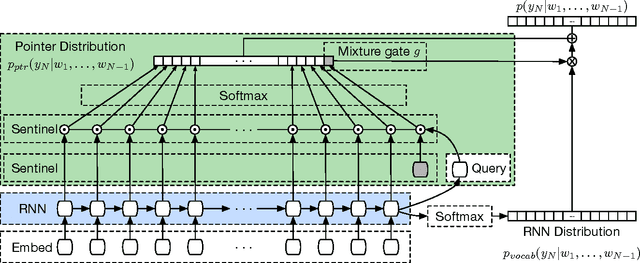
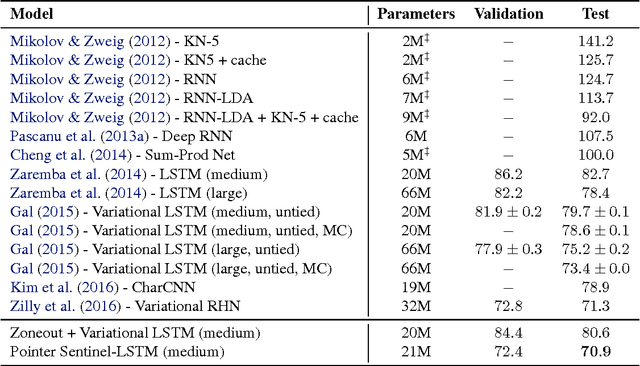
Recent neural network sequence models with softmax classifiers have achieved their best language modeling performance only with very large hidden states and large vocabularies. Even then they struggle to predict rare or unseen words even if the context makes the prediction unambiguous. We introduce the pointer sentinel mixture architecture for neural sequence models which has the ability to either reproduce a word from the recent context or produce a word from a standard softmax classifier. Our pointer sentinel-LSTM model achieves state of the art language modeling performance on the Penn Treebank (70.9 perplexity) while using far fewer parameters than a standard softmax LSTM. In order to evaluate how well language models can exploit longer contexts and deal with more realistic vocabularies and larger corpora we also introduce the freely available WikiText corpus.
Dynamic Memory Networks for Visual and Textual Question Answering
Mar 04, 2016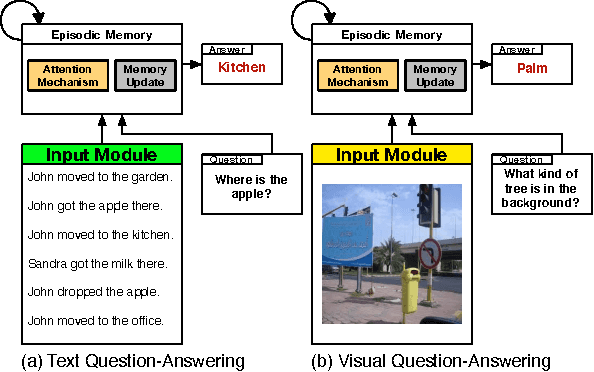
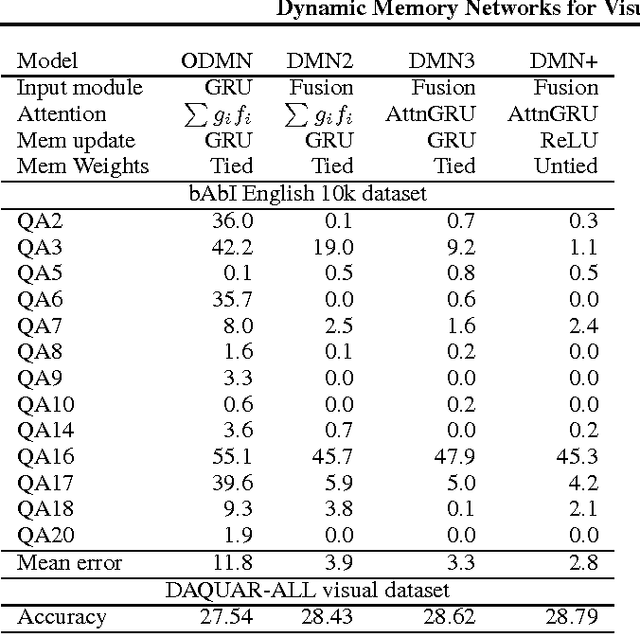
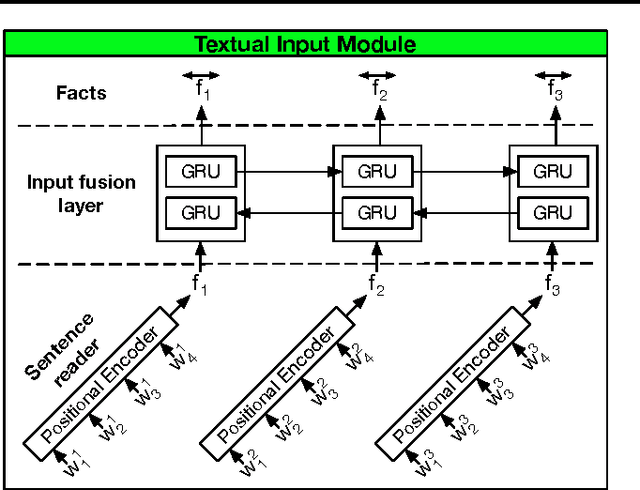
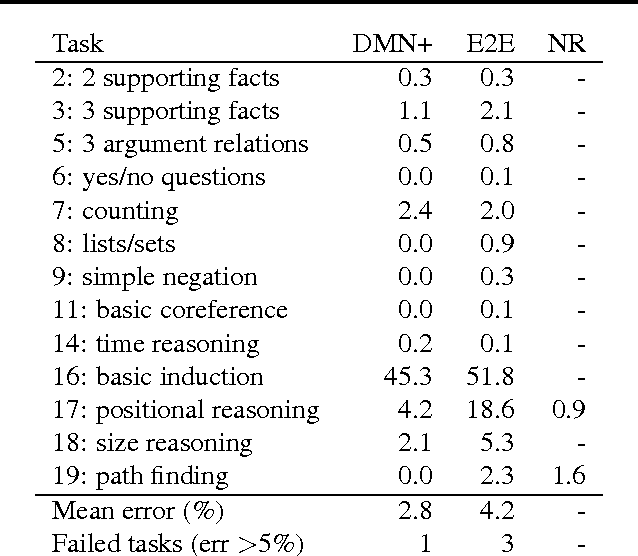
Neural network architectures with memory and attention mechanisms exhibit certain reasoning capabilities required for question answering. One such architecture, the dynamic memory network (DMN), obtained high accuracy on a variety of language tasks. However, it was not shown whether the architecture achieves strong results for question answering when supporting facts are not marked during training or whether it could be applied to other modalities such as images. Based on an analysis of the DMN, we propose several improvements to its memory and input modules. Together with these changes we introduce a novel input module for images in order to be able to answer visual questions. Our new DMN+ model improves the state of the art on both the Visual Question Answering dataset and the \babi-10k text question-answering dataset without supporting fact supervision.