 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Flexible Approach to Automated RNN Architecture Generation
Dec 20, 2017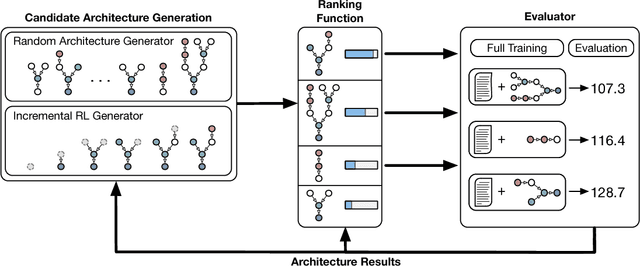
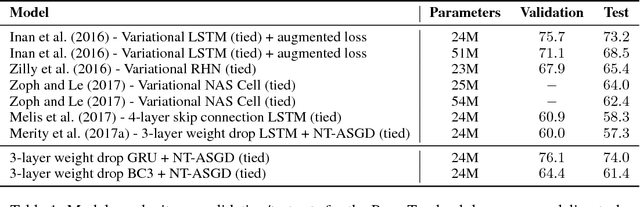
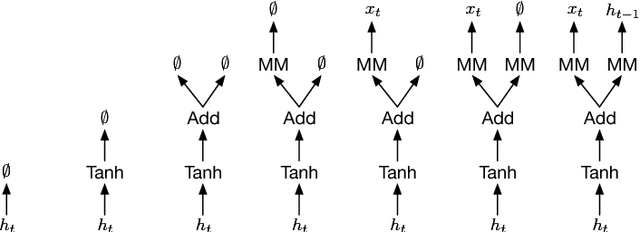

The process of designing neural architectures requires expert knowledge and extensive trial and error. While automated architecture search may simplify these requirements, the recurrent neural network (RNN) architectures generated by existing methods are limited in both flexibility and components. We propose a domain-specific language (DSL) for use in automated architecture search which can produce novel RNNs of arbitrary depth and width. The DSL is flexible enough to define standard architectures such as the Gated Recurrent Unit and Long Short Term Memory and allows the introduction of non-standard RNN components such as trigonometric curves and layer normalization. Using two different candidate generation techniques, random search with a ranking function and reinforcement learning, we explore the novel architectures produced by the RNN DSL for language modeling and machine translation domains. The resulting architectures do not follow human intuition yet perform well on their targeted tasks, suggesting the space of usable RNN architectures is far larger than previously assumed.
Block-diagonal Hessian-free Optimization for Training Neural Networks
Dec 20, 2017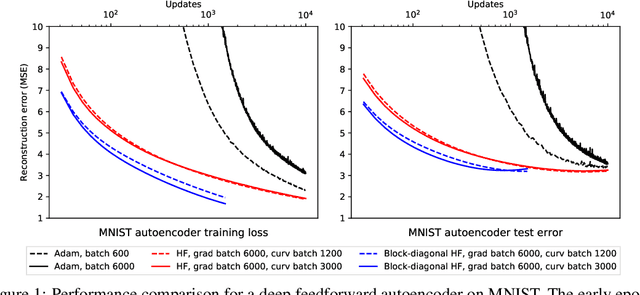
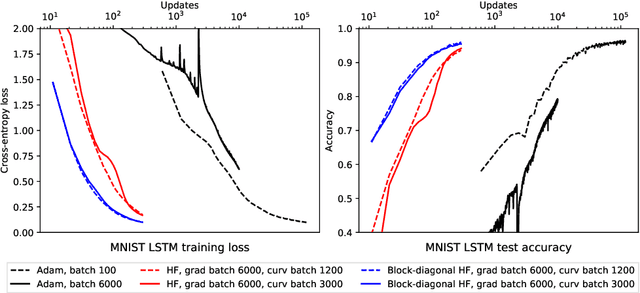
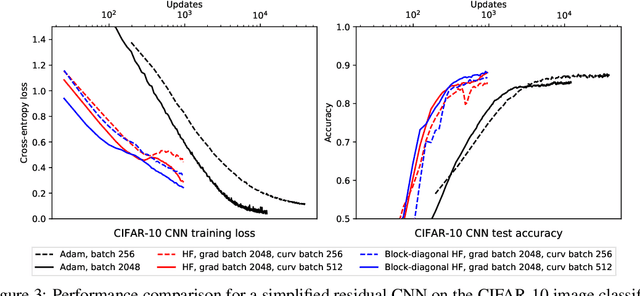
Second-order methods for neural network optimization have several advantages over methods based on first-order gradient descent, including better scaling to large mini-batch sizes and fewer updates needed for convergence. But they are rarely applied to deep learning in practice because of high computational cost and the need for model-dependent algorithmic variations. We introduce a variant of the Hessian-free method that leverages a block-diagonal approximation of the generalized Gauss-Newton matrix. Our method computes the curvature approximation matrix only for pairs of parameters from the same layer or block of the neural network and performs conjugate gradient updates independently for each block. Experiments on deep autoencoders, deep convolutional networks, and multilayer LSTMs demonstrate better convergence and generalization compared to the original Hessian-free approach and the Adam method.
Hierarchical and Interpretable Skill Acquisition in Multi-task Reinforcement Learning
Dec 20, 2017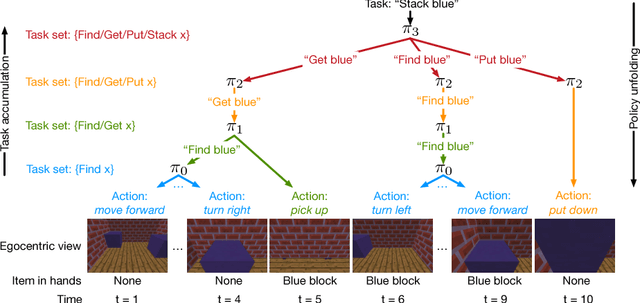

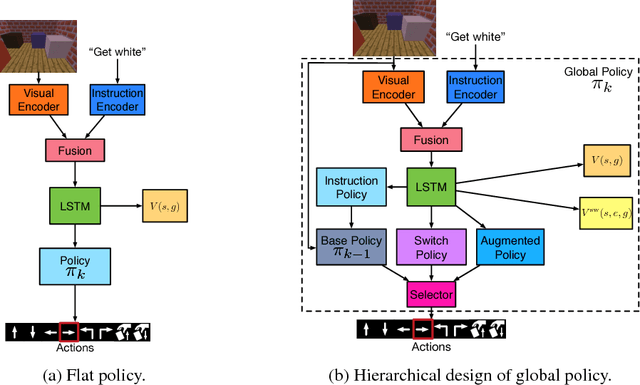
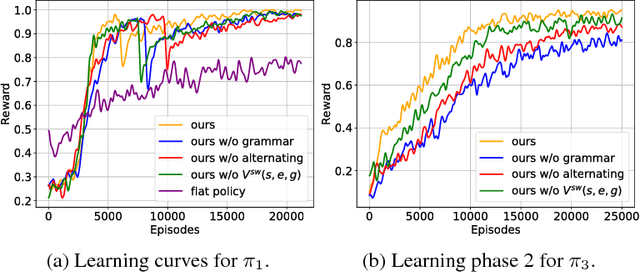
Learning policies for complex tasks that require multiple different skills is a major challenge in reinforcement learning (RL). It is also a requirement for its deployment in real-world scenarios. This paper proposes a novel framework for efficient multi-task reinforcement learning. Our framework trains agents to employ hierarchical policies that decide when to use a previously learned policy and when to learn a new skill. This enables agents to continually acquire new skills during different stages of training. Each learned task corresponds to a human language description. Because agents can only access previously learned skills through these descriptions, the agent can always provide a human-interpretable description of its choices. In order to help the agent learn the complex temporal dependencies necessary for the hierarchical policy, we provide it with a stochastic temporal grammar that modulates when to rely on previously learned skills and when to execute new skills. We validate our approach on Minecraft games designed to explicitly test the ability to reuse previously learned skills while simultaneously learning new skills.
Improved Regularization Techniques for End-to-End Speech Recognition
Dec 19, 2017
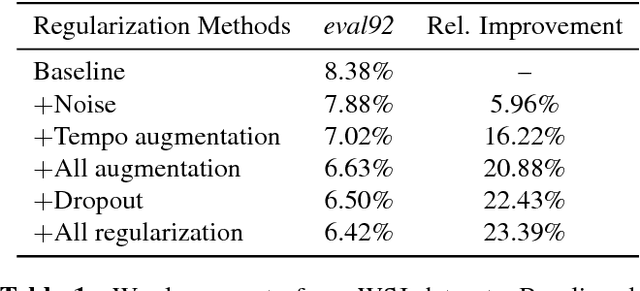
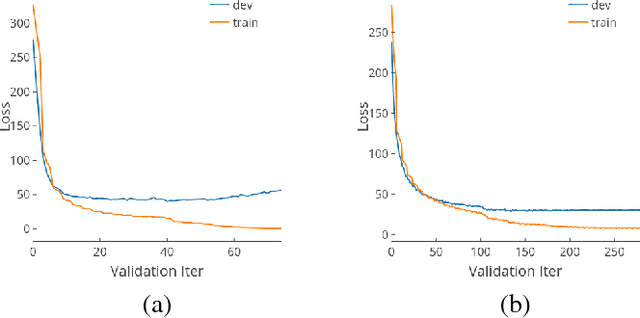

Regularization is important for end-to-end speech models, since the models are highly flexible and easy to overfit. Data augmentation and dropout has been important for improving end-to-end models in other domains. However, they are relatively under explored for end-to-end speech models. Therefore, we investigate the effectiveness of both methods for end-to-end trainable, deep speech recognition models. We augment audio data through random perturbations of tempo, pitch, volume, temporal alignment, and adding random noise.We further investigate the effect of dropout when applied to the inputs of all layers of the network. We show that the combination of data augmentation and dropout give a relative performance improvement on both Wall Street Journal (WSJ) and LibriSpeech dataset of over 20%. Our model performance is also competitive with other end-to-end speech models on both datasets.
Improving End-to-End Speech Recognition with Policy Learning
Dec 19, 2017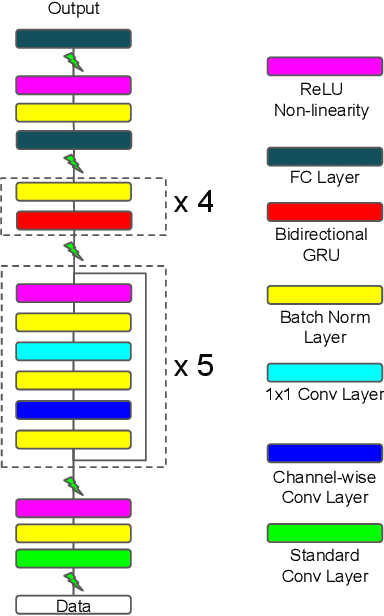
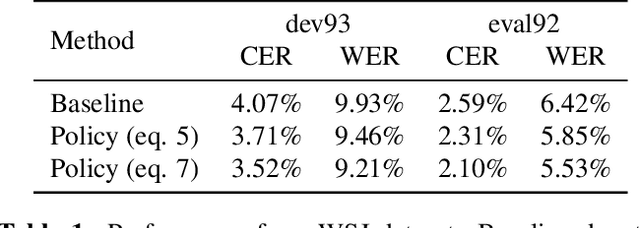
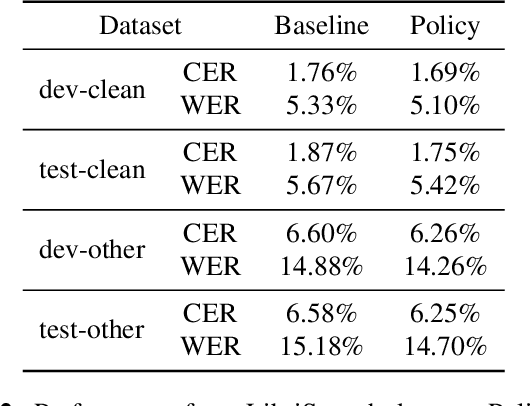
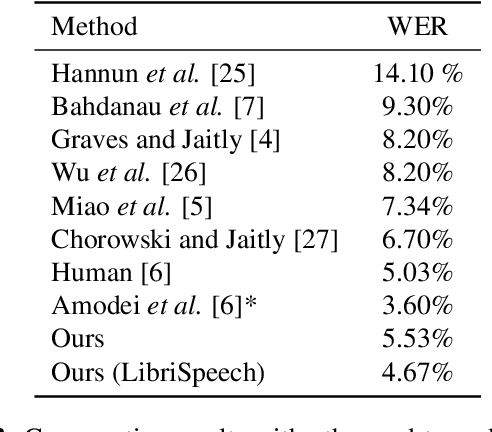
Connectionist temporal classification (CTC) is widely used for maximum likelihood learning in end-to-end speech recognition models. However, there is usually a disparity between the negative maximum likelihood and the performance metric used in speech recognition, e.g., word error rate (WER). This results in a mismatch between the objective function and metric during training. We show that the above problem can be mitigated by jointly training with maximum likelihood and policy gradient. In particular, with policy learning we are able to directly optimize on the (otherwise non-differentiable) performance metric. We show that joint training improves relative performance by 4% to 13% for our end-to-end model as compared to the same model learned through maximum likelihood. The model achieves 5.53% WER on Wall Street Journal dataset, and 5.42% and 14.70% on Librispeech test-clean and test-other set, respectively.
Learning when to skim and when to read
Dec 15, 2017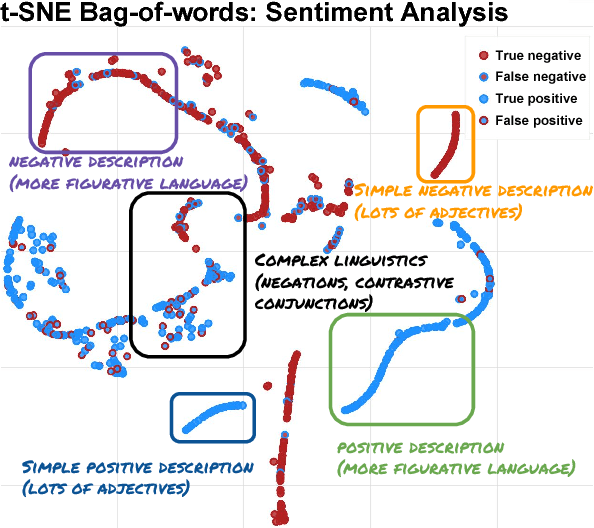

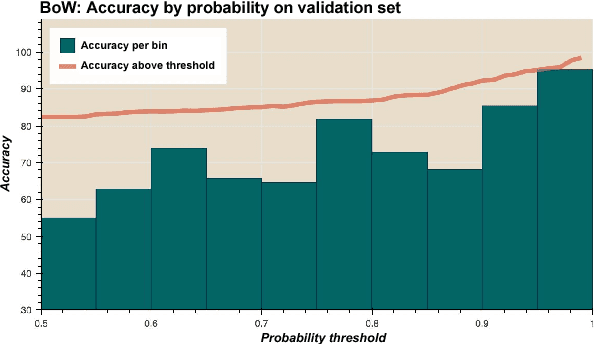
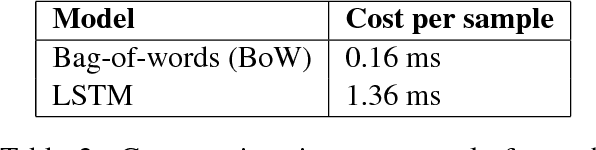
Many recent advances in deep learning for natural language processing have come at increasing computational cost, but the power of these state-of-the-art models is not needed for every example in a dataset. We demonstrate two approaches to reducing unnecessary computation in cases where a fast but weak baseline classier and a stronger, slower model are both available. Applying an AUC-based metric to the task of sentiment classification, we find significant efficiency gains with both a probability-threshold method for reducing computational cost and one that uses a secondary decision network.
A Deep Reinforced Model for Abstractive Summarization
Nov 13, 2017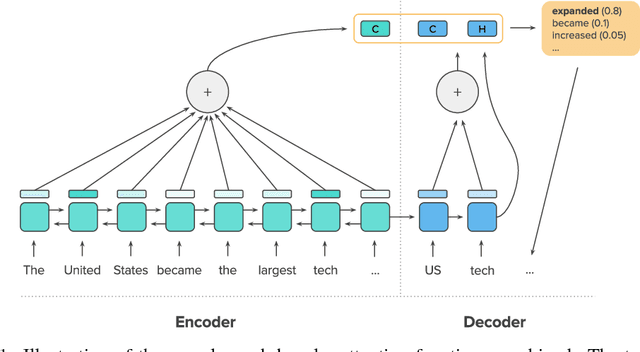
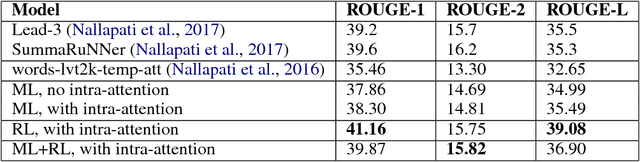

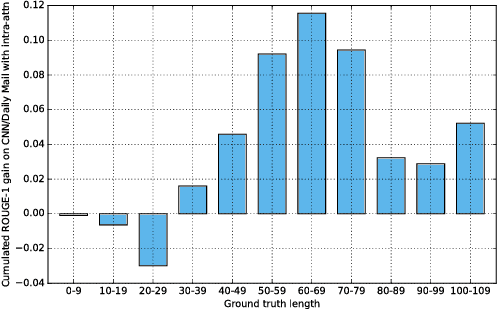
Attentional, RNN-based encoder-decoder models for abstractive summarization have achieved good performance on short input and output sequences. For longer documents and summaries however these models often include repetitive and incoherent phrases. We introduce a neural network model with a novel intra-attention that attends over the input and continuously generated output separately, and a new training method that combines standard supervised word prediction and reinforcement learning (RL). Models trained only with supervised learning often exhibit "exposure bias" - they assume ground truth is provided at each step during training. However, when standard word prediction is combined with the global sequence prediction training of RL the resulting summaries become more readable. We evaluate this model on the CNN/Daily Mail and New York Times datasets. Our model obtains a 41.16 ROUGE-1 score on the CNN/Daily Mail dataset, an improvement over previous state-of-the-art models. Human evaluation also shows that our model produces higher quality summaries.
DCN+: Mixed Objective and Deep Residual Coattention for Question Answering
Nov 10, 2017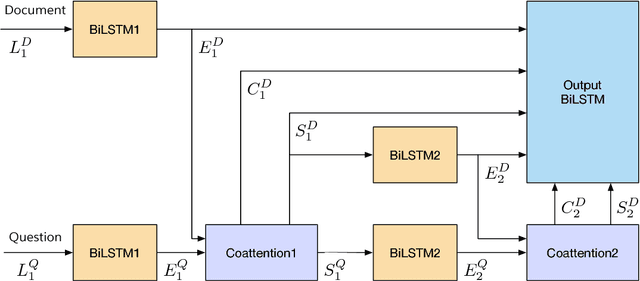
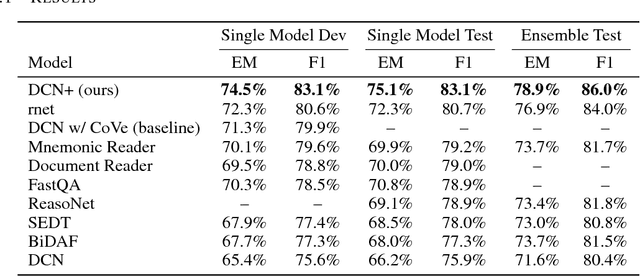
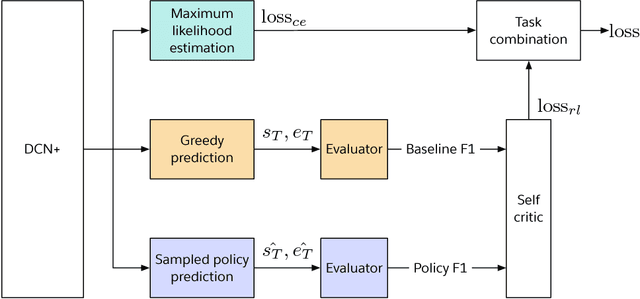
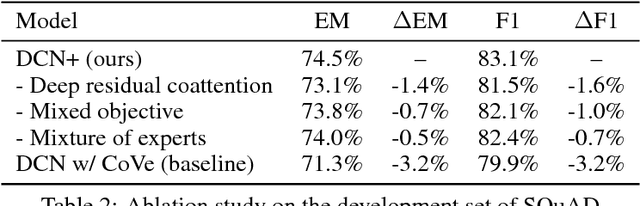
Traditional models for question answering optimize using cross entropy loss, which encourages exact answers at the cost of penalizing nearby or overlapping answers that are sometimes equally accurate. We propose a mixed objective that combines cross entropy loss with self-critical policy learning. The objective uses rewards derived from word overlap to solve the misalignment between evaluation metric and optimization objective. In addition to the mixed objective, we improve dynamic coattention networks (DCN) with a deep residual coattention encoder that is inspired by recent work in deep self-attention and residual networks. Our proposals improve model performance across question types and input lengths, especially for long questions that requires the ability to capture long-term dependencies. On the Stanford Question Answering Dataset, our model achieves state-of-the-art results with 75.1% exact match accuracy and 83.1% F1, while the ensemble obtains 78.9% exact match accuracy and 86.0% F1.
Weighted Transformer Network for Machine Translation
Nov 06, 2017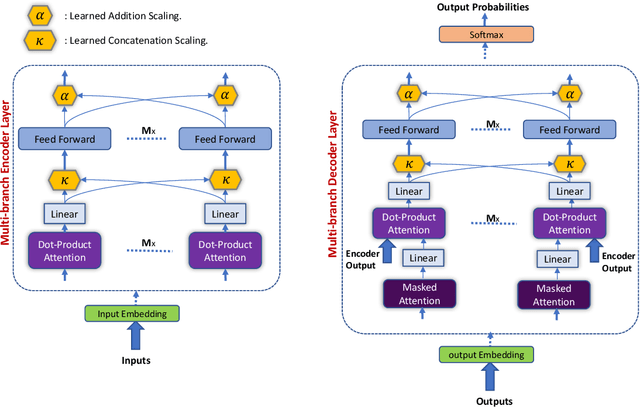
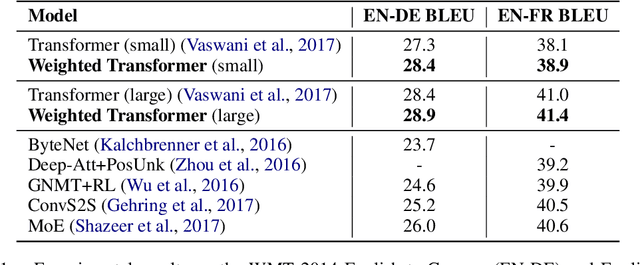
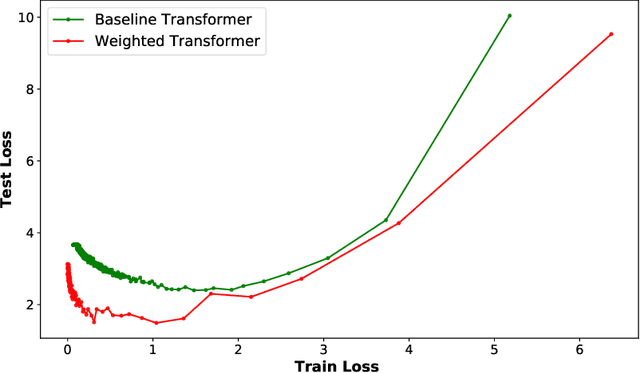
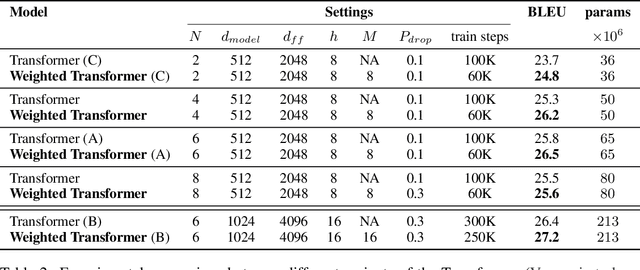
State-of-the-art results on neural machine translation often use attentional sequence-to-sequence models with some form of convolution or recursion. Vaswani et al. (2017) propose a new architecture that avoids recurrence and convolution completely. Instead, it uses only self-attention and feed-forward layers. While the proposed architecture achieves state-of-the-art results on several machine translation tasks, it requires a large number of parameters and training iterations to converge. We propose Weighted Transformer, a Transformer with modified attention layers, that not only outperforms the baseline network in BLEU score but also converges 15-40% faster. Specifically, we replace the multi-head attention by multiple self-attention branches that the model learns to combine during the training process. Our model improves the state-of-the-art performance by 0.5 BLEU points on the WMT 2014 English-to-German translation task and by 0.4 on the English-to-French translation task.
Towards Neural Machine Translation with Latent Tree Attention
Sep 06, 2017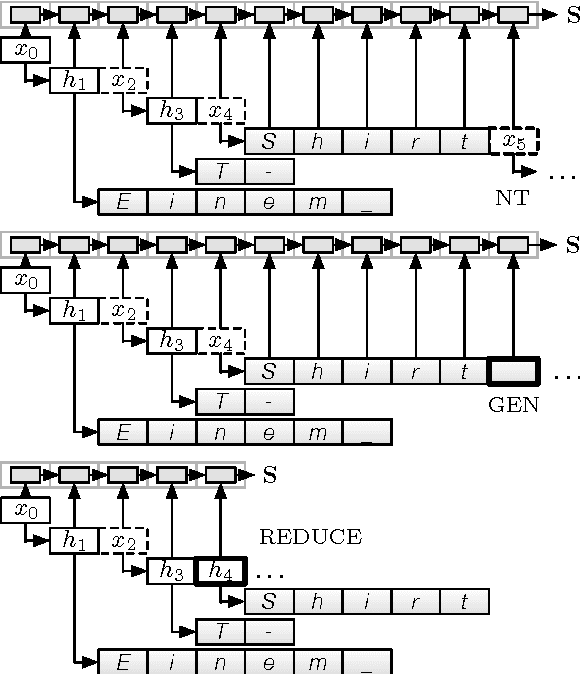
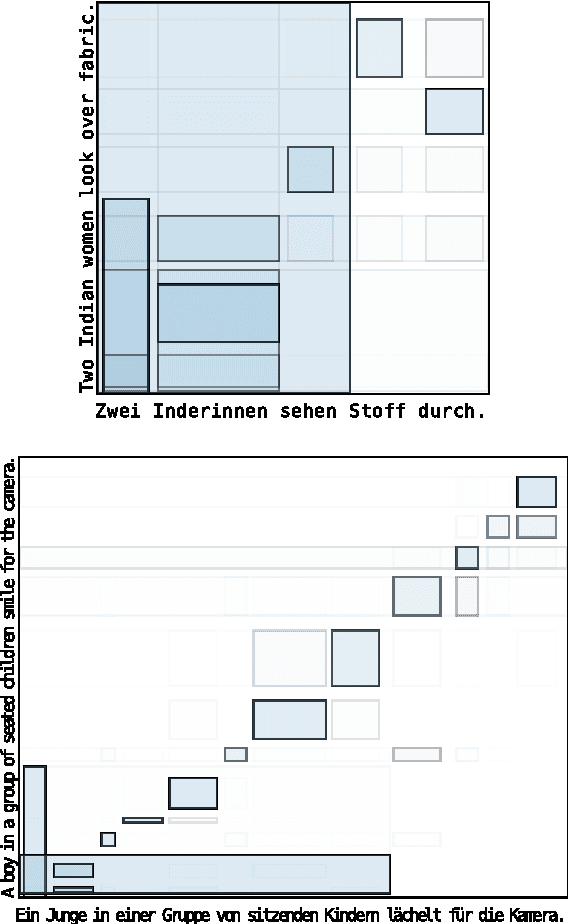
Building models that take advantage of the hierarchical structure of language without a priori annotation is a longstanding goal in natural language processing. We introduce such a model for the task of machine translation, pairing a recurrent neural network grammar encoder with a novel attentional RNNG decoder and applying policy gradient reinforcement learning to induce unsupervised tree structures on both the source and target. When trained on character-level datasets with no explicit segmentation or parse annotation, the model learns a plausible segmentation and shallow parse, obtaining performance close to an attentional baseline.