 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegral Privacy for Sampling from Mollifier Densities with Approximation Guarantees
Sep 12, 2018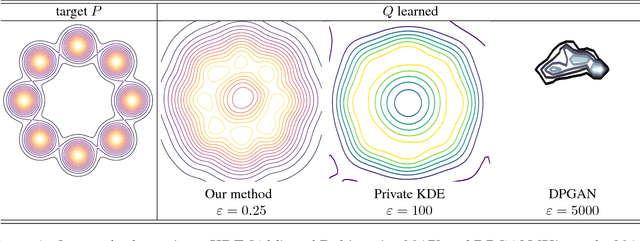
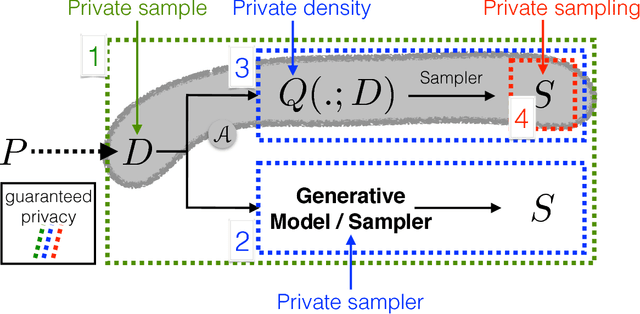
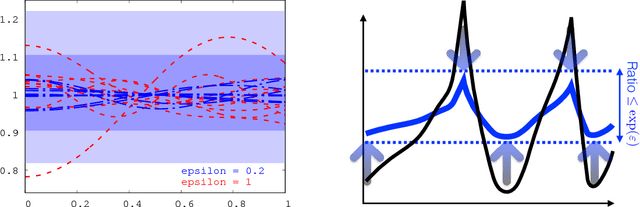
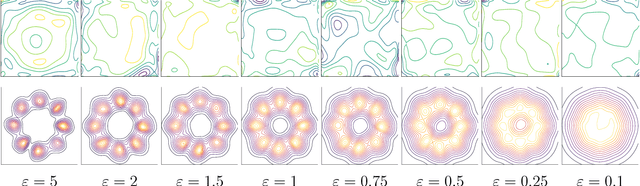
Sampling encompasses old and central problems in statistics and machine learning. There exists several approaches to cast this problem in a differential privacy framework but little is still comparatively known about the approximation guarantees of the unknown density by the private one learned. In this paper, we first introduce a general condition for a set of densities, called an $\varepsilon$-mollifier, to grant privacy for sampling in the $\varepsilon$-differential privacy model, and even in a stronger model where we remove the famed adjacency condition of inputs. We then show how to exploit the boosting toolkit to learn a density within an $\varepsilon$-mollifier with guaranteed approximation of the target density that degrade gracefully with the privacy budget. Approximation guarantees cover the mode capture problem, a problem which is receiving a lot of attention in the generative models literature. To our knowledge, the way we exploit the boosting toolkit has never been done before in the context of density estimation or sampling: we require access to a weak learner in the original boosting sense, so we learn a density out of \textit{classifiers}. Experimental results against a state of the art implementation of private kernel density estimation display that our technique consistently obtains improved results, managing in particular to get similar outputs for a privacy budget $\epsilon$ which is however orders of magnitude smaller.
Lipschitz Networks and Distributional Robustness
Sep 04, 2018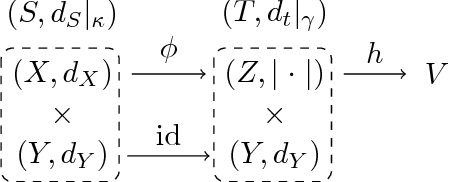
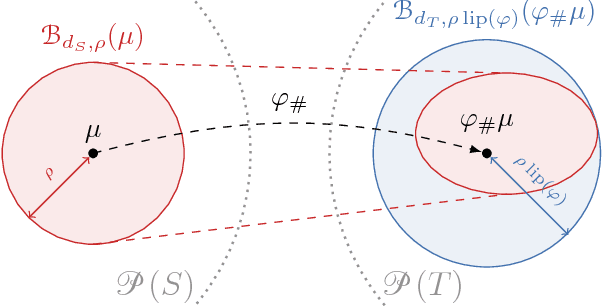
Robust risk minimisation has several advantages: it has been studied with regards to improving the generalisation properties of models and robustness to adversarial perturbation. We bound the distributionally robust risk for a model class rich enough to include deep neural networks by a regularised empirical risk involving the Lipschitz constant of the model. This allows us to interpretand quantify the robustness properties of a deep neural network. As an application we show the distributionally robust risk upperbounds the adversarial training risk.
D-PAGE: Diverse Paraphrase Generation
Aug 13, 2018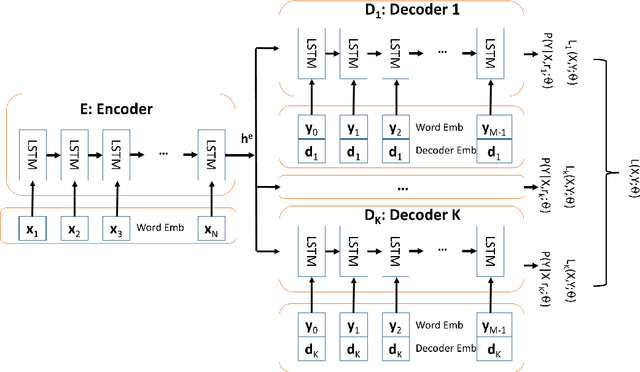
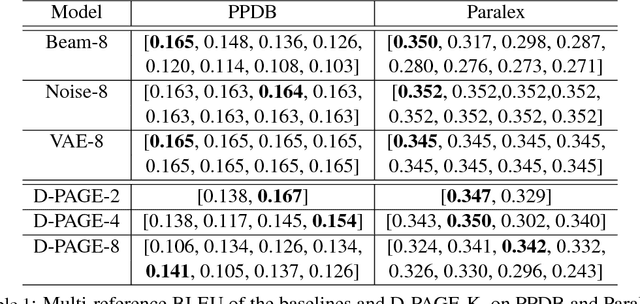

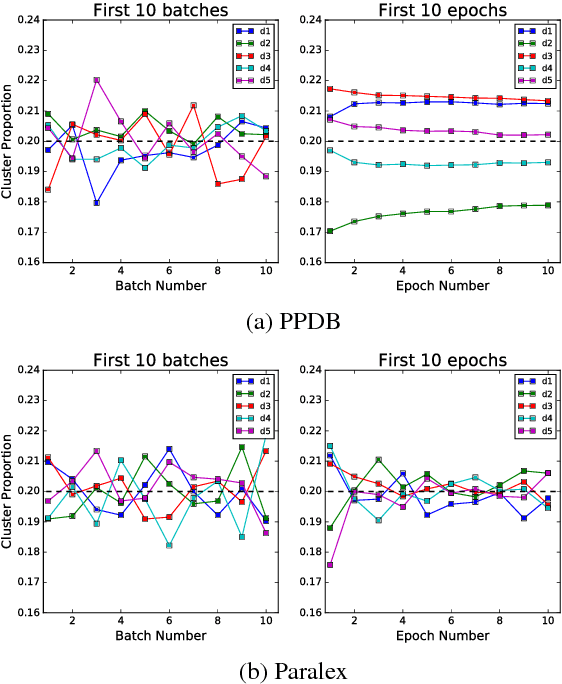
In this paper, we investigate the diversity aspect of paraphrase generation. Prior deep learning models employ either decoding methods or add random input noise for varying outputs. We propose a simple method Diverse Paraphrase Generation (D-PAGE), which extends neural machine translation (NMT) models to support the generation of diverse paraphrases with implicit rewriting patterns. Our experimental results on two real-world benchmark datasets demonstrate that our model generates at least one order of magnitude more diverse outputs than the baselines in terms of a new evaluation metric Jeffrey's Divergence. We have also conducted extensive experiments to understand various properties of our model with a focus on diversity.
Private Text Classification
Jun 19, 2018

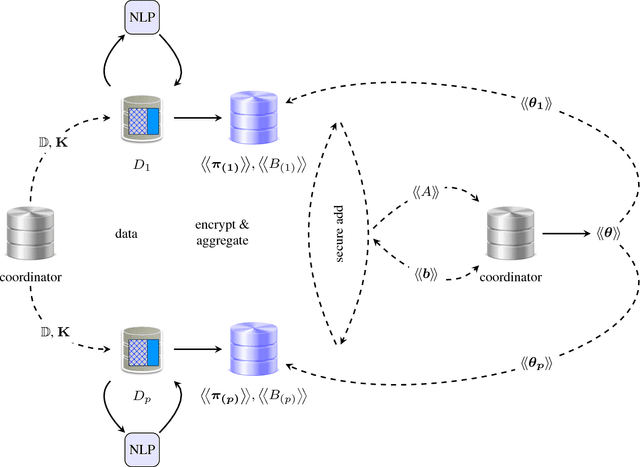
Confidential text corpora exist in many forms, but do not allow arbitrary sharing. We explore how to use such private corpora using privacy preserving text analytics. We construct typical text processing applications using appropriate privacy preservation techniques (including homomorphic encryption, Rademacher operators and secure computation). We set out the preliminary materials from Rademacher operators for binary classifiers, and then construct basic text processing approaches to match those binary classifiers.
Boosted Density Estimation Remastered
Jun 18, 2018
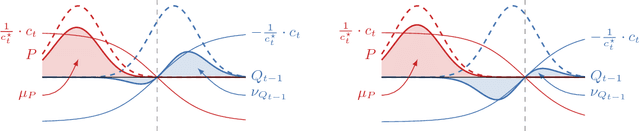
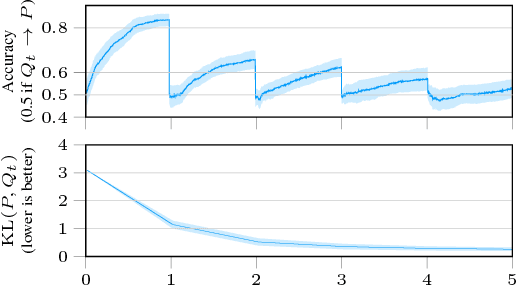
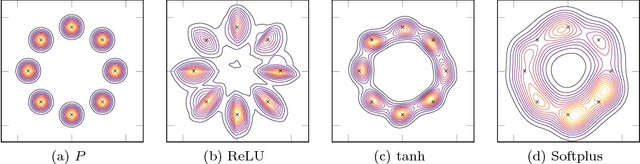
There has recently been a steady increase in the number iterative approaches to density estimation. However, an accompanying burst of formal convergence guarantees has not followed; all results pay the price of heavy assumptions which are often unrealistic or hard to check. The Generative Adversarial Network (GAN) literature --- seemingly orthogonal to the aforementioned pursuit --- has had the side effect of a renewed interest in variational divergence minimisation (notably $f$-GAN). We show that by introducing a weak learning assumption (in the sense of the classical boosting framework) we are able to import some recent results from the GAN literature to develop an iterative boosted density estimation algorithm, including formal convergence results with rates, that does not suffer the shortcomings other approaches. We show that the density fit is an exponential family, and as part of our analysis obtain an improved variational characterisation of $f$-GAN.
Entity Resolution and Federated Learning get a Federated Resolution
Mar 20, 2018
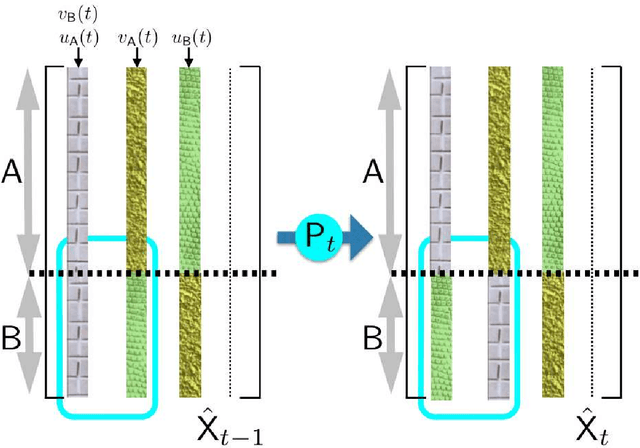
Consider two data providers, each maintaining records of different feature sets about common entities. They aim to learn a linear model over the whole set of features. This problem of federated learning over vertically partitioned data includes a crucial upstream issue: entity resolution, i.e. finding the correspondence between the rows of the datasets. It is well known that entity resolution, just like learning, is mistake-prone in the real world. Despite the importance of the problem, there has been no formal assessment of how errors in entity resolution impact learning. In this paper, we provide a thorough answer to this question, answering how optimal classifiers, empirical losses, margins and generalisation abilities are affected. While our answer spans a wide set of losses --- going beyond proper, convex, or classification calibrated ---, it brings simple practical arguments to upgrade entity resolution as a preprocessing step to learning. One of these suggests that entity resolution should be aimed at controlling or minimizing the number of matching errors between examples of distinct classes. In our experiments, we modify a simple token-based entity resolution algorithm so that it indeed aims at avoiding matching rows belonging to different classes, and perform experiments in the setting where entity resolution relies on noisy data, which is very relevant to real world domains. Notably, our approach covers the case where one peer \textit{does not} have classes, or a noisy record of classes. Experiments display that using the class information during entity resolution can buy significant uplift for learning at little expense from the complexity standpoint.
Evolving a Vector Space with any Generating Set
Dec 31, 2017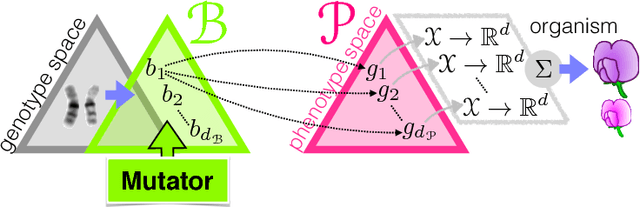
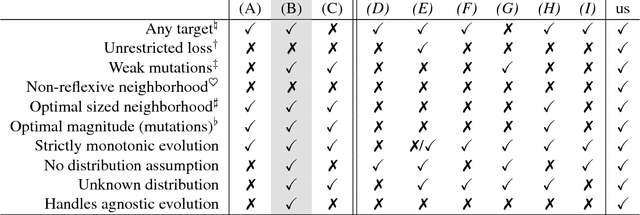
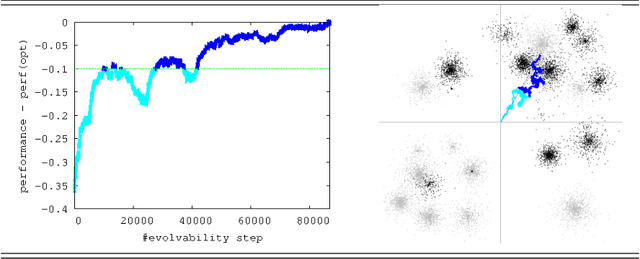
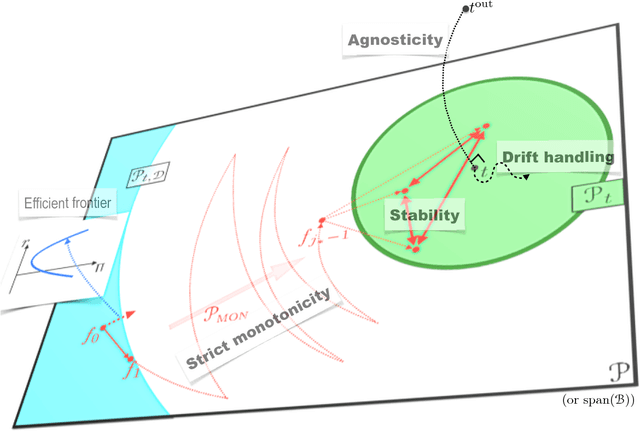
In Valiant's model of evolution, a class of representations is evolvable iff a polynomial-time process of random mutations guided by selection converges with high probability to a representation as $\epsilon$-close as desired from the optimal one, for any required $\epsilon>0$. Several previous positive results exist that can be related to evolving a vector space, but each former result imposes disproportionate representations or restrictions on (re)initialisations, distributions, performance functions and/or the mutator. In this paper, we show that all it takes to evolve a normed vector space is merely a set that generates the space. Furthermore, it takes only $\tilde{O}(1/\epsilon^2)$ steps and it is essentially stable, agnostic and handles target drifts that rival some proven in fairly restricted settings. Our algorithm can be viewed as a close relative to a popular fifty-years old gradient-free optimization method for which little is still known from the convergence standpoint: Nelder-Mead simplex method.
Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption
Nov 29, 2017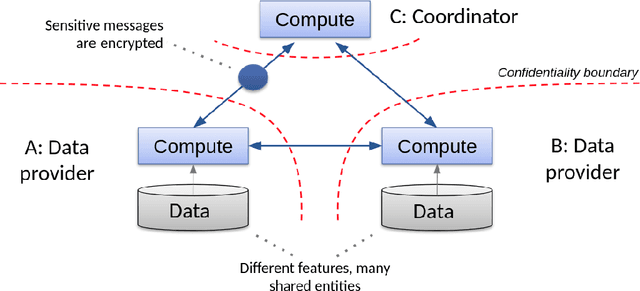


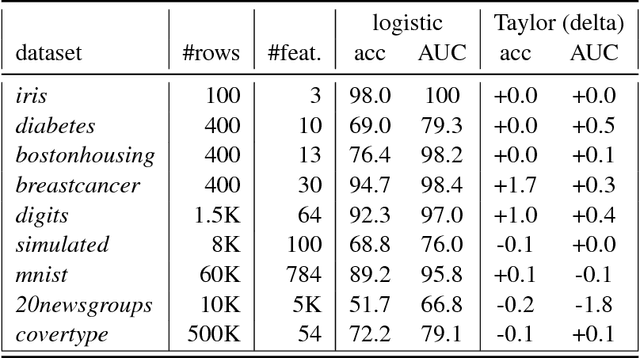
Consider two data providers, each maintaining private records of different feature sets about common entities. They aim to learn a linear model jointly in a federated setting, namely, data is local and a shared model is trained from locally computed updates. In contrast with most work on distributed learning, in this scenario (i) data is split vertically, i.e. by features, (ii) only one data provider knows the target variable and (iii) entities are not linked across the data providers. Hence, to the challenge of private learning, we add the potentially negative consequences of mistakes in entity resolution. Our contribution is twofold. First, we describe a three-party end-to-end solution in two phases ---privacy-preserving entity resolution and federated logistic regression over messages encrypted with an additively homomorphic scheme---, secure against a honest-but-curious adversary. The system allows learning without either exposing data in the clear or sharing which entities the data providers have in common. Our implementation is as accurate as a naive non-private solution that brings all data in one place, and scales to problems with millions of entities with hundreds of features. Second, we provide what is to our knowledge the first formal analysis of the impact of entity resolution's mistakes on learning, with results on how optimal classifiers, empirical losses, margins and generalisation abilities are affected. Our results bring a clear and strong support for federated learning: under reasonable assumptions on the number and magnitude of entity resolution's mistakes, it can be extremely beneficial to carry out federated learning in the setting where each peer's data provides a significant uplift to the other.
On $w$-mixtures: Finite convex combinations of prescribed component distributions
Aug 02, 2017
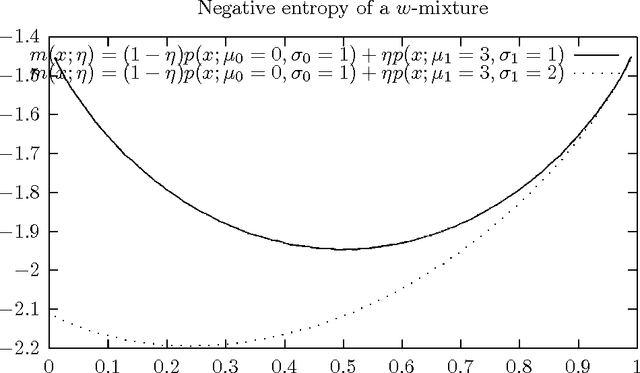
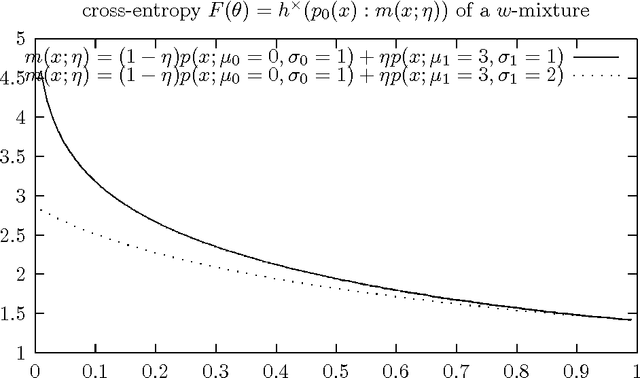

We consider the space of $w$-mixtures that is the set of finite statistical mixtures sharing the same prescribed component distributions. The geometry induced by the Kullback-Leibler (KL) divergence on this family of $w$-mixtures is a dually flat space in information geometry called the mixture family manifold. It follows that the KL divergence between two $w$-mixtures is equivalent to a Bregman Divergence (BD) defined for the negative Shannon entropy generator. Thus the KL divergence between two Gaussian Mixture Models (GMMs) sharing the same components is (theoretically) a Bregman divergence. This KL-BD equivalence implies that we can perform optimal KL-averaging aggregation of $w$-mixtures without information loss. More generally, we prove that the skew Jensen-Shannon divergence between $w$-mixtures is equivalent to a skew Jensen divergence on their parameters. Finally, we state several divergence identity and inequalities relating $w$-mixtures.
f-GANs in an Information Geometric Nutshell
Jul 14, 2017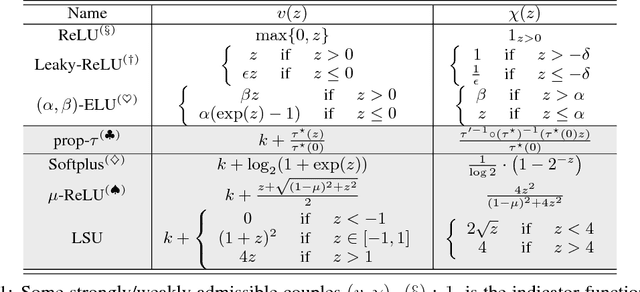

Nowozin \textit{et al} showed last year how to extend the GAN \textit{principle} to all $f$-divergences. The approach is elegant but falls short of a full description of the supervised game, and says little about the key player, the generator: for example, what does the generator actually converge to if solving the GAN game means convergence in some space of parameters? How does that provide hints on the generator's design and compare to the flourishing but almost exclusively experimental literature on the subject? In this paper, we unveil a broad class of distributions for which such convergence happens --- namely, deformed exponential families, a wide superset of exponential families --- and show tight connections with the three other key GAN parameters: loss, game and architecture. In particular, we show that current deep architectures are able to factorize a very large number of such densities using an especially compact design, hence displaying the power of deep architectures and their concinnity in the $f$-GAN game. This result holds given a sufficient condition on \textit{activation functions} --- which turns out to be satisfied by popular choices. The key to our results is a variational generalization of an old theorem that relates the KL divergence between regular exponential families and divergences between their natural parameters. We complete this picture with additional results and experimental insights on how these results may be used to ground further improvements of GAN architectures, via (i) a principled design of the activation functions in the generator and (ii) an explicit integration of proper composite losses' link function in the discriminator.