 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub-seasonal forecasting with a large ensemble of deep-learning weather prediction models
Feb 09, 2021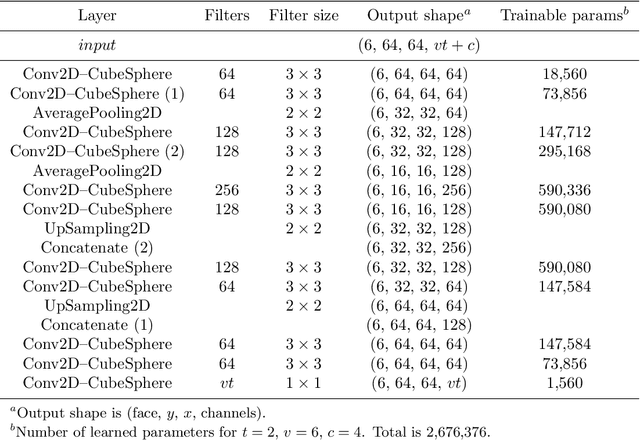
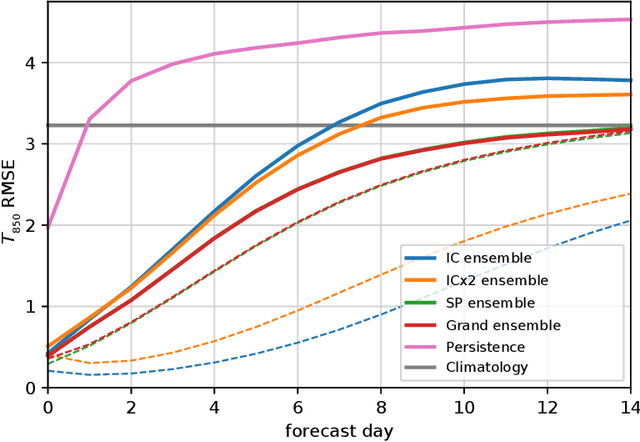
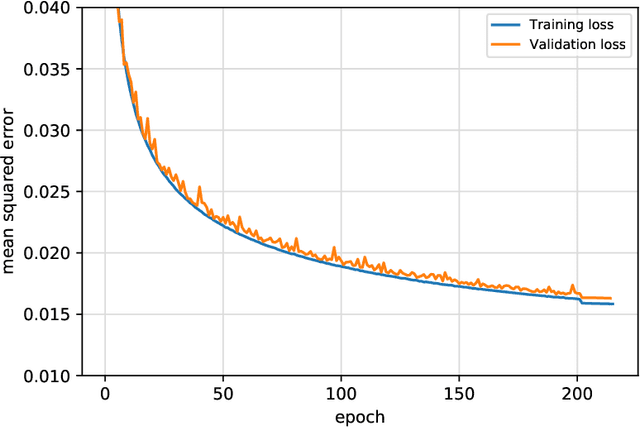
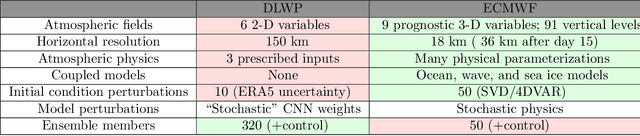
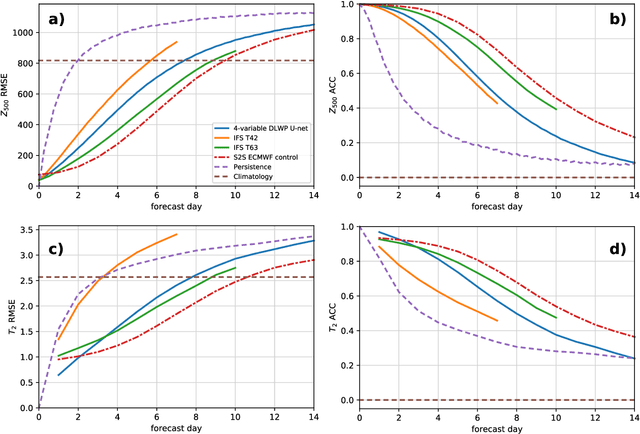
We present an ensemble prediction system using a Deep Learning Weather Prediction (DLWP) model that recursively predicts key atmospheric variables with six-hour time resolution. This model uses convolutional neural networks (CNNs) on a cubed sphere grid to produce global forecasts. The approach is computationally efficient, requiring just three minutes on a single GPU to produce a 320-member set of six-week forecasts at 1.4{\deg} resolution. Ensemble spread is primarily produced by randomizing the CNN training process to create a set of 32 DLWP models with slightly different learned weights. Although our DLWP model does not forecast precipitation, it does forecast total column water vapor, and it gives a reasonable 4.5-day deterministic forecast of Hurricane Irma. In addition to simulating mid-latitude weather systems, it spontaneously generates tropical cyclones in a one-year free-running simulation. Averaged globally and over a two-year test set, the ensemble mean RMSE retains skill relative to climatology beyond two-weeks, with anomaly correlation coefficients remaining above 0.6 through six days. Our primary application is to subseasonal-to-seasonal (S2S) forecasting at lead times from two to six weeks. Current forecast systems have low skill in predicting one- or 2-week-average weather patterns at S2S time scales. The continuous ranked probability score (CRPS) and the ranked probability skill score (RPSS) show that the DLWP ensemble is only modestly inferior in performance to the European Centre for Medium Range Weather Forecasts (ECMWF) S2S ensemble over land at lead times of 4 and 5-6 weeks. At shorter lead times, the ECMWF ensemble performs better than DLWP.
On Dropout, Overfitting, and Interaction Effects in Deep Neural Networks
Jul 02, 2020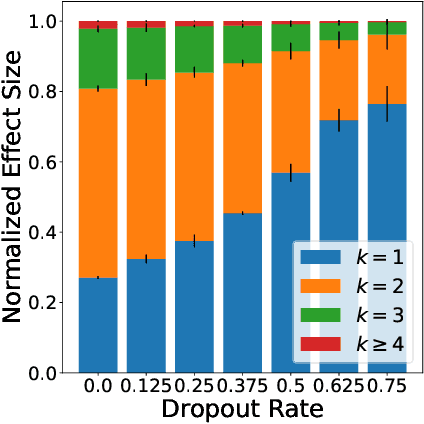

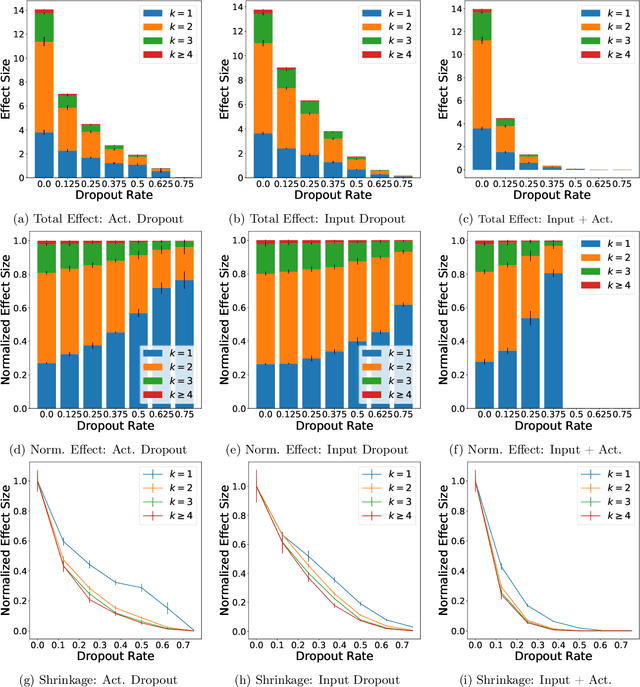
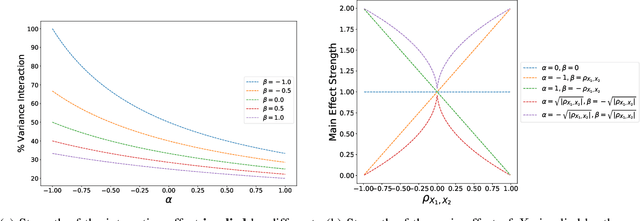
We examine Dropout through the perspective of interactions: learned effects that combine multiple input variables. Given $N$ variables, there are $O(N^2)$ possible pairwise interactions, $O(N^3)$ possible 3-way interactions, etc. We show that Dropout implicitly sets a learning rate for interaction effects that decays exponentially with the size of the interaction, corresponding to a regularizer that balances against the hypothesis space which grows exponentially with number of variables in the interaction. This understanding of Dropout has implications for the optimal Dropout rate: higher Dropout rates should be used when we need stronger regularization against spurious high-order interactions. This perspective also issues caution against using Dropout to measure term saliency because Dropout regularizes against terms for high-order interactions. Finally, this view of Dropout as a regularizer of interaction effects provides insight into the varying effectiveness of Dropout for different architectures and data sets. We also compare Dropout to regularization via weight decay and early stopping and find that it is difficult to obtain the same regularization effect for high-order interactions with these methods.
How Interpretable and Trustworthy are GAMs?
Jun 11, 2020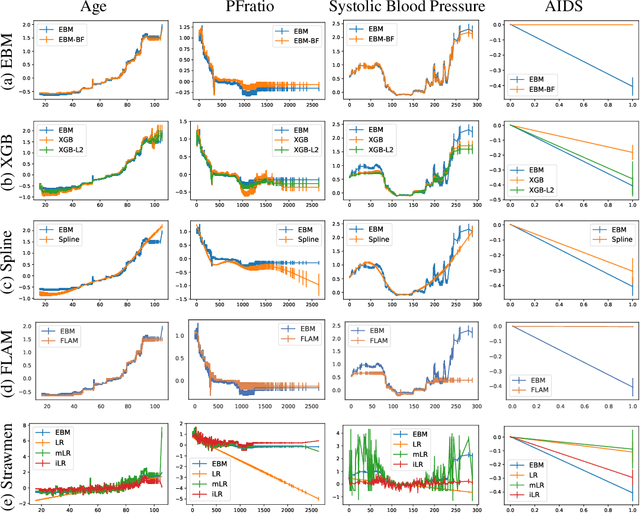
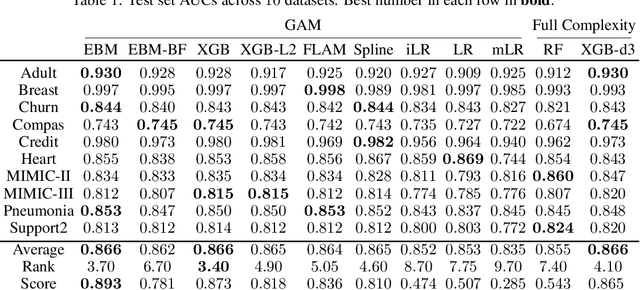

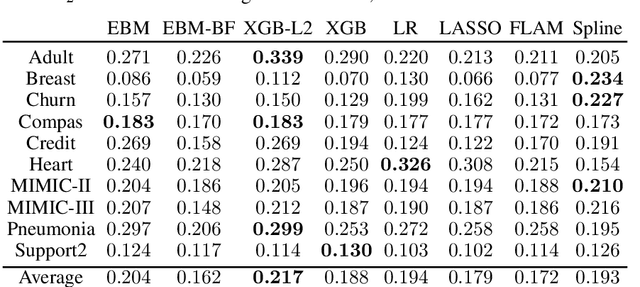
Generalized additive models (GAMs) have become a leading model class for data bias discovery and model auditing. However, there are a variety of algorithms for training GAMs, and these do not always learn the same things. Statisticians originally used splines to train GAMs, but more recently GAMs are being trained with boosted decision trees. It is unclear which GAM model(s) to believe, particularly when their explanations are contradictory. In this paper, we investigate a variety of different GAM algorithms both qualitatively and quantitatively on real and simulated datasets. Our results suggest that inductive bias plays a crucial role in model explanations and tree-based GAMs are to be recommended for the kinds of problems and dataset sizes we worked with.
Neural Additive Models: Interpretable Machine Learning with Neural Nets
Apr 29, 2020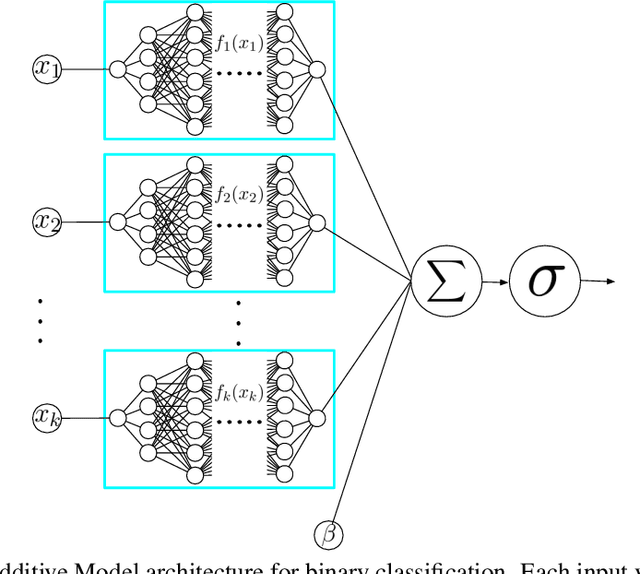
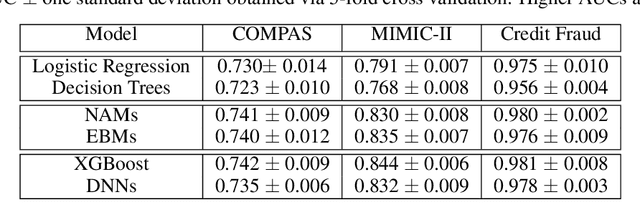
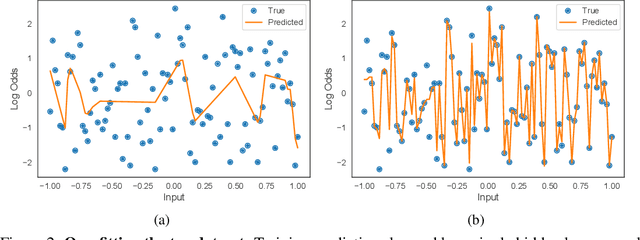
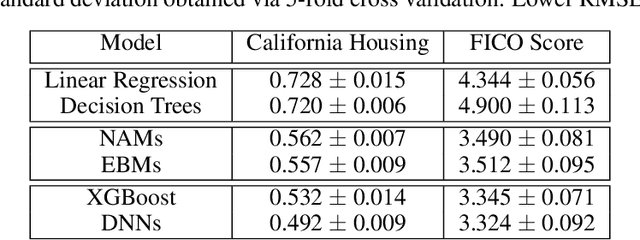
Deep neural networks (DNNs) are powerful black-box predictors that have achieved impressive performance on a wide variety of tasks. However, their accuracy comes at the cost of intelligibility: it is usually unclear how they make their decisions. This hinders their applicability to high stakes decision-making domains such as healthcare. We propose Neural Additive Models (NAMs) which combine some of the expressivity of DNNs with the inherent intelligibility of generalized additive models. NAMs learn a linear combination of neural networks that each attend to a single input feature. These networks are trained jointly and can learn arbitrarily complex relationships between their input feature and the output. Our experiments on regression and classification datasets show that NAMs are more accurate than widely used intelligible models such as logistic regression and shallow decision trees. They perform similarly to existing state-of-the-art generalized additive models in accuracy, but can be more easily applied to real-world problems.
Improving data-driven global weather prediction using deep convolutional neural networks on a cubed sphere
Mar 15, 2020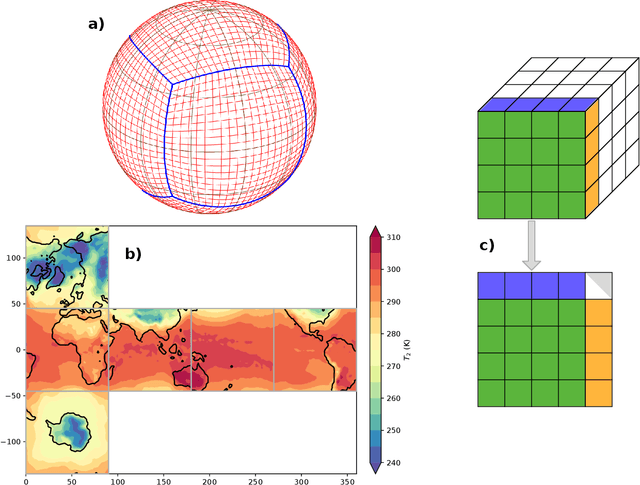
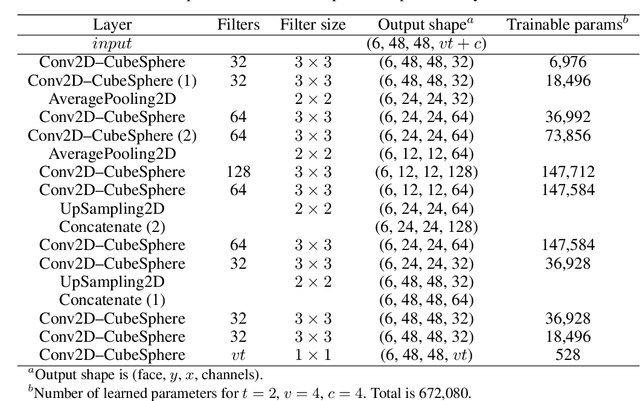
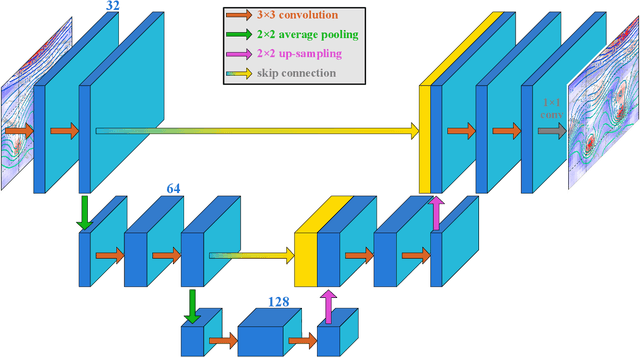
We present a significantly-improved data-driven global weather forecasting framework using a deep convolutional neural network (CNN) to forecast several basic atmospheric variables on a global grid. New developments in this framework include an offline volume-conservative mapping to a cubed-sphere grid, improvements to the CNN architecture, and the minimization of the loss function over multiple steps in a prediction sequence. The cubed-sphere remapping minimizes the distortion on the cube faces on which convolution operations are performed and provides natural boundary conditions for padding in the CNN. Our improved model produces weather forecasts that are indefinitely stable and produce realistic weather patterns at lead times of several weeks and longer. For short- to medium-range forecasting, our model significantly outperforms persistence, climatology, and a coarse-resolution dynamical numerical weather prediction (NWP) model. Unsurprisingly, our forecasts are worse than those from a high-resolution state-of-the-art operational NWP system. Our data-driven model is able to learn to forecast complex surface temperature patterns from few input atmospheric state variables. On annual time scales, our model produces a realistic seasonal cycle driven solely by the prescribed variation in top-of-atmosphere solar forcing. Although it is currently less accurate than operational weather forecasting models, our data-driven CNN executes much faster than those models, suggesting that machine learning could prove to be a valuable tool for large-ensemble forecasting.
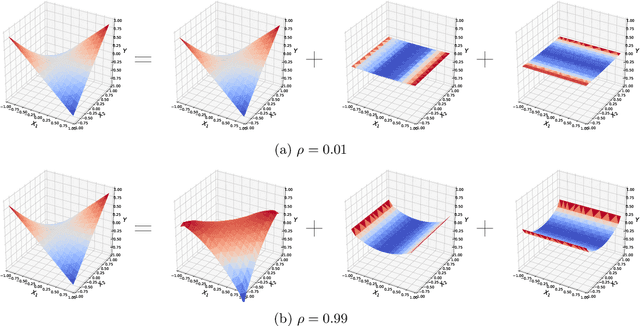
Purifying Interaction Effects with the Functional ANOVA: An Efficient Algorithm for Recovering Identifiable Additive Models
Nov 12, 2019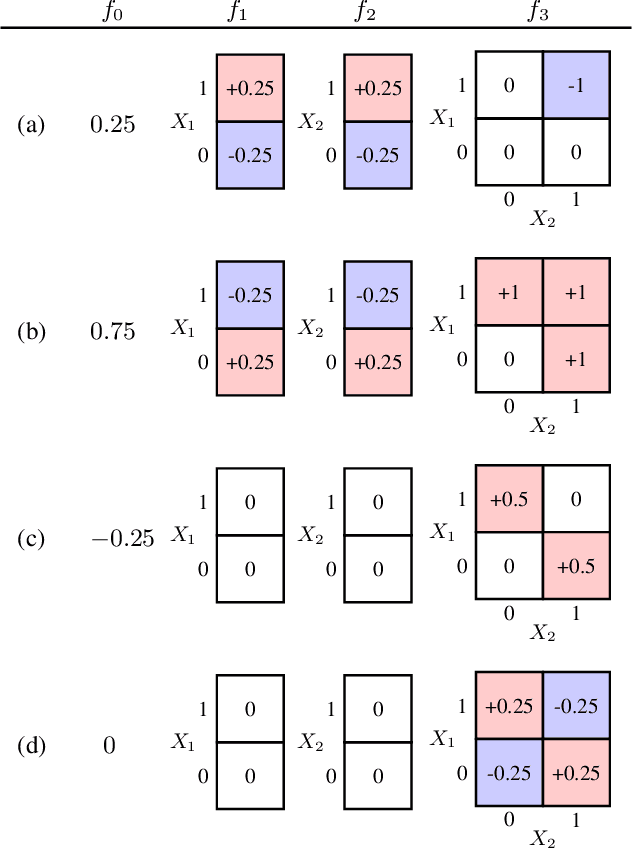

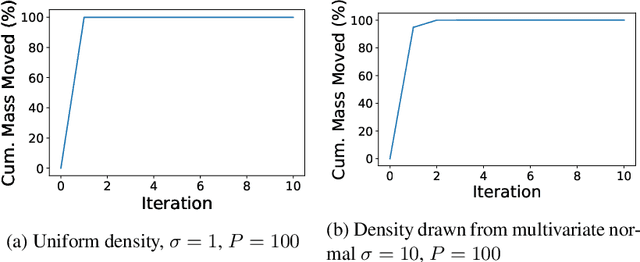
Recent methods for training generalized additive models (GAMs) with pairwise interactions achieve state-of-the-art accuracy on a variety of datasets. Adding interactions to GAMs, however, introduces an identifiability problem: effects can be freely moved between main effects and interaction effects without changing the model predictions. In some cases, this can lead to contradictory interpretations of the same underlying function. This is a critical problem because a central motivation of GAMs is model interpretability. In this paper, we use the Functional ANOVA decomposition to uniquely define interaction effects and thus produce identifiable additive models with purified interactions. To compute this decomposition, we present a fast, exact, mass-moving algorithm that transforms any piecewise-constant function (such as a tree-based model) into a purified, canonical representation. We apply this algorithm to several datasets and show large disparity, including contradictions, between the apparent and the purified effects.
InterpretML: A Unified Framework for Machine Learning Interpretability
Sep 19, 2019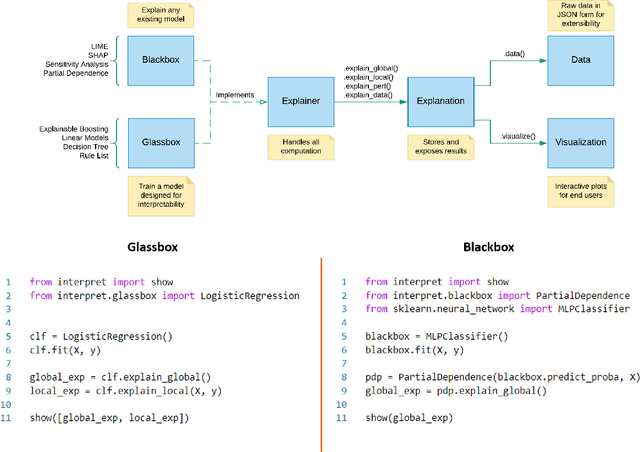
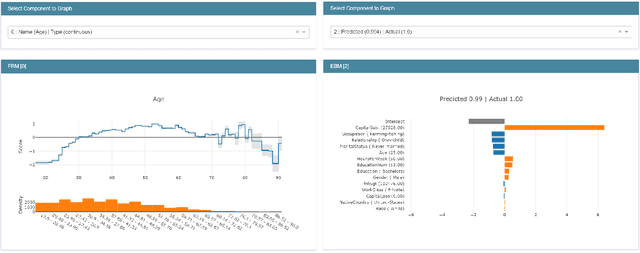
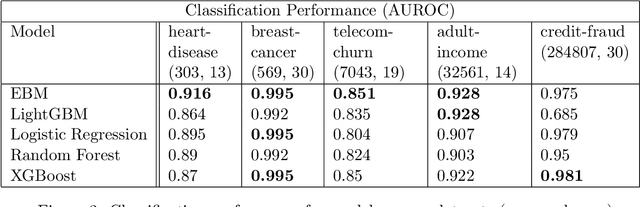
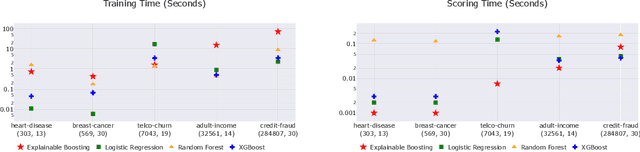
InterpretML is an open-source Python package which exposes machine learning interpretability algorithms to practitioners and researchers. InterpretML exposes two types of interpretability - glassbox models, which are machine learning models designed for interpretability (ex: linear models, rule lists, generalized additive models), and blackbox explainability techniques for explaining existing systems (ex: Partial Dependence, LIME). The package enables practitioners to easily compare interpretability algorithms by exposing multiple methods under a unified API, and by having a built-in, extensible visualization platform. InterpretML also includes the first implementation of the Explainable Boosting Machine, a powerful, interpretable, glassbox model that can be as accurate as many blackbox models. The MIT licensed source code can be downloaded from github.com/microsoft/interpret.
Efficient Forward Architecture Search
May 31, 2019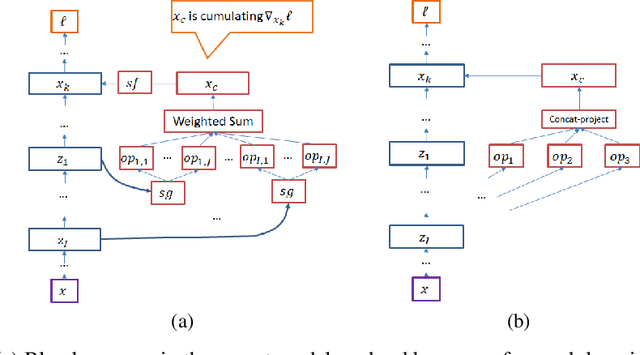
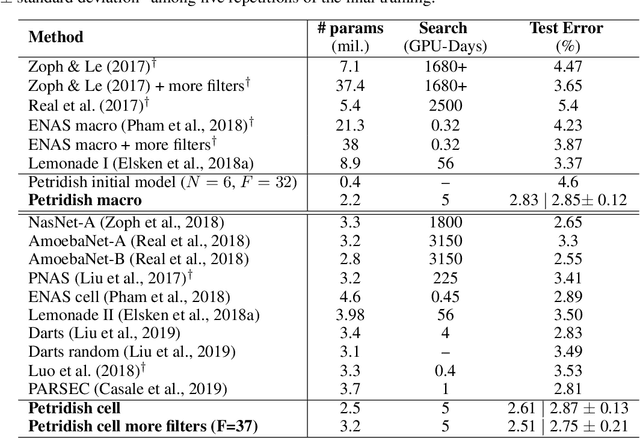
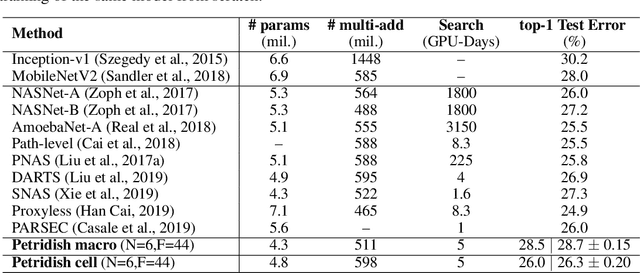
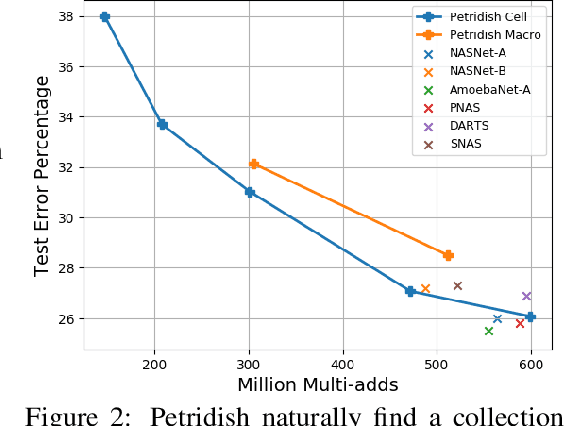
We propose a neural architecture search (NAS) algorithm, Petridish, to iteratively add shortcut connections to existing network layers. The added shortcut connections effectively perform gradient boosting on the augmented layers. The proposed algorithm is motivated by the feature selection algorithm forward stage-wise linear regression, since we consider NAS as a generalization of feature selection for regression, where NAS selects shortcuts among layers instead of selecting features. In order to reduce the number of trials of possible connection combinations, we train jointly all possible connections at each stage of growth while leveraging feature selection techniques to choose a subset of them. We experimentally show this process to be an efficient forward architecture search algorithm that can find competitive models using few GPU days in both the search space of repeatable network modules (cell-search) and the space of general networks (macro-search). Petridish is particularly well-suited for warm-starting from existing models crucial for lifelong-learning scenarios.
Interpretability is Harder in the Multiclass Setting: Axiomatic Interpretability for Multiclass Additive Models
Oct 22, 2018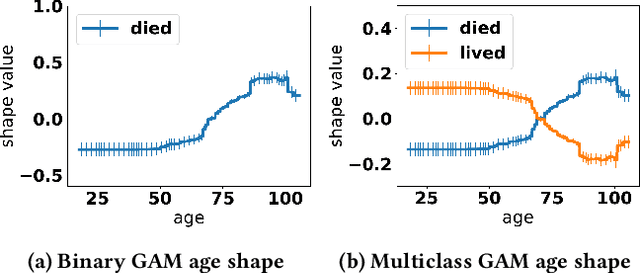
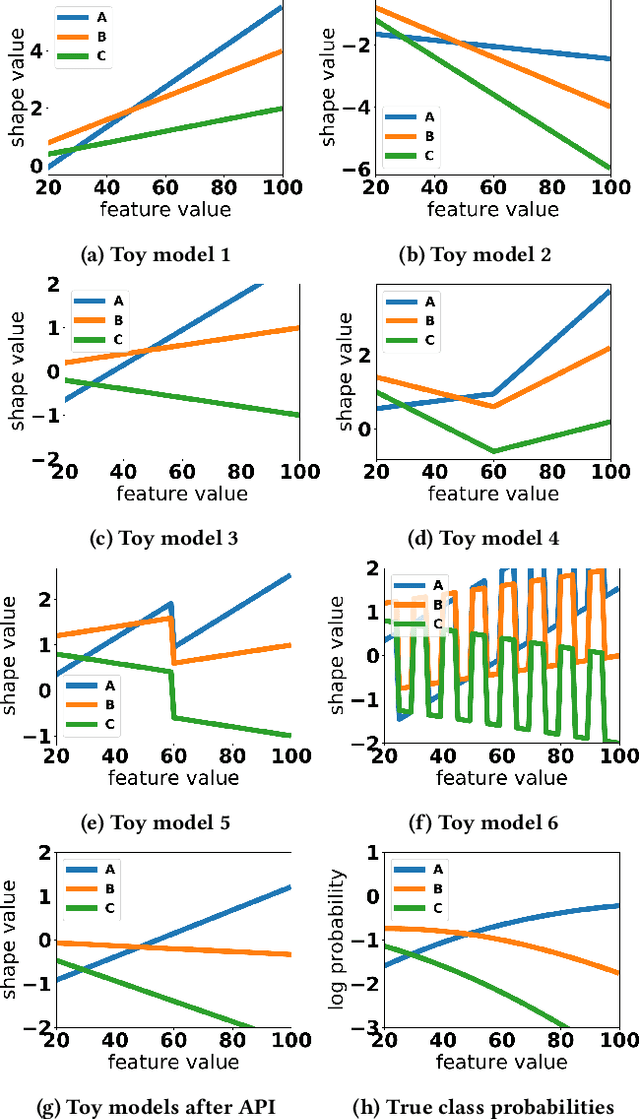
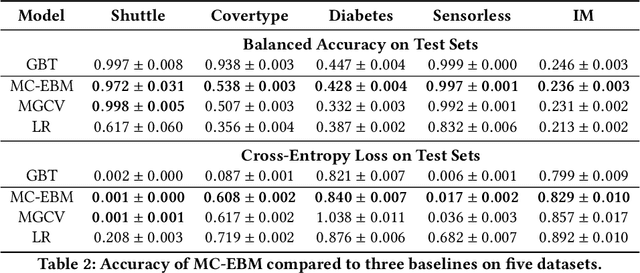
Generalized additive models (GAMs) are favored in many regression and binary classification problems because they are able to fit complex, nonlinear functions while still remaining interpretable. In the first part of this paper, we generalize a state-of-the-art GAM learning algorithm based on boosted trees to the multiclass setting, and show that this multiclass algorithm outperforms existing GAM fitting algorithms and sometimes matches the performance of full complex models. In the second part, we turn our attention to the interpretability of GAMs in the multiclass setting. Surprisingly, the natural interpretability of GAMs breaks down when there are more than two classes. Drawing inspiration from binary GAMs, we identify two axioms that any additive model must satisfy to not be visually misleading. We then develop a post-processing technique (API) that provably transforms pretrained additive models to satisfy the interpretability axioms without sacrificing accuracy. The technique works not just on models trained with our algorithm, but on any multiclass additive model. We demonstrate API on a 12-class infant-mortality dataset.
Distill-and-Compare: Auditing Black-Box Models Using Transparent Model Distillation
Oct 11, 2018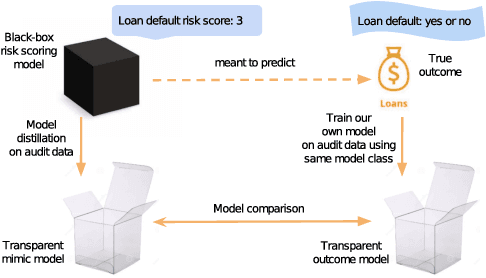
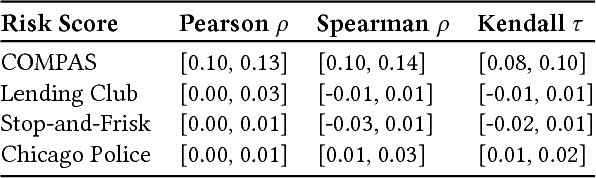
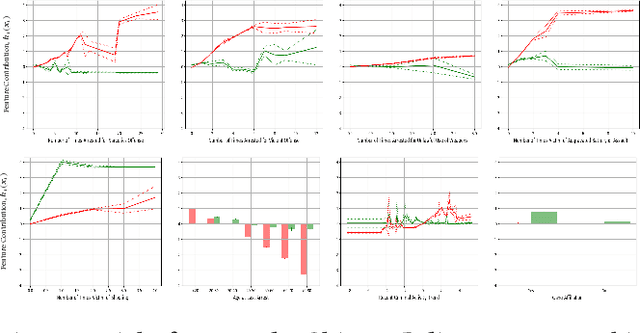
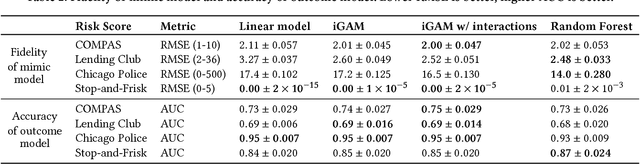
Black-box risk scoring models permeate our lives, yet are typically proprietary or opaque. We propose Distill-and-Compare, a model distillation and comparison approach to audit such models. To gain insight into black-box models, we treat them as teachers, training transparent student models to mimic the risk scores assigned by black-box models. We compare the student model trained with distillation to a second un-distilled transparent model trained on ground-truth outcomes, and use differences between the two models to gain insight into the black-box model. Our approach can be applied in a realistic setting, without probing the black-box model API. We demonstrate the approach on four public data sets: COMPAS, Stop-and-Frisk, Chicago Police, and Lending Club. We also propose a statistical test to determine if a data set is missing key features used to train the black-box model. Our test finds that the ProPublica data is likely missing key feature(s) used in COMPAS.