 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointSt3R: Point Tracking through 3D Grounded Correspondence
Oct 30, 2025



Recent advances in foundational 3D reconstruction models, such as DUSt3R and MASt3R, have shown great potential in 2D and 3D correspondence in static scenes. In this paper, we propose to adapt them for the task of point tracking through 3D grounded correspondence. We first demonstrate that these models are competitive point trackers when focusing on static points, present in current point tracking benchmarks ($+33.5\%$ on EgoPoints vs. CoTracker2). We propose to combine the reconstruction loss with training for dynamic correspondence along with a visibility head, and fine-tuning MASt3R for point tracking using a relatively small amount of synthetic data. Importantly, we only train and evaluate on pairs of frames where one contains the query point, effectively removing any temporal context. Using a mix of dynamic and static point correspondences, we achieve competitive or superior point tracking results on four datasets (e.g. competitive on TAP-Vid-DAVIS 73.8 $\delta_{avg}$ / 85.8\% occlusion acc. for PointSt3R compared to 75.7 / 88.3\% for CoTracker2; and significantly outperform CoTracker3 on EgoPoints 61.3 vs 54.2 and RGB-S 87.0 vs 82.8). We also present results on 3D point tracking along with several ablations on training datasets and percentage of dynamic correspondences.
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
Feb 06, 2025
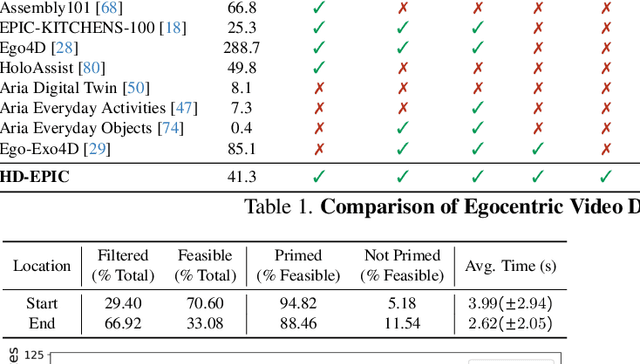


We present a validation dataset of newly-collected kitchen-based egocentric videos, manually annotated with highly detailed and interconnected ground-truth labels covering: recipe steps, fine-grained actions, ingredients with nutritional values, moving objects, and audio annotations. Importantly, all annotations are grounded in 3D through digital twinning of the scene, fixtures, object locations, and primed with gaze. Footage is collected from unscripted recordings in diverse home environments, making HDEPIC the first dataset collected in-the-wild but with detailed annotations matching those in controlled lab environments. We show the potential of our highly-detailed annotations through a challenging VQA benchmark of 26K questions assessing the capability to recognise recipes, ingredients, nutrition, fine-grained actions, 3D perception, object motion, and gaze direction. The powerful long-context Gemini Pro only achieves 38.5% on this benchmark, showcasing its difficulty and highlighting shortcomings in current VLMs. We additionally assess action recognition, sound recognition, and long-term video-object segmentation on HD-EPIC. HD-EPIC is 41 hours of video in 9 kitchens with digital twins of 413 kitchen fixtures, capturing 69 recipes, 59K fine-grained actions, 51K audio events, 20K object movements and 37K object masks lifted to 3D. On average, we have 263 annotations per minute of our unscripted videos.
EgoPoints: Advancing Point Tracking for Egocentric Videos
Dec 05, 2024



We introduce EgoPoints, a benchmark for point tracking in egocentric videos. We annotate 4.7K challenging tracks in egocentric sequences. Compared to the popular TAP-Vid-DAVIS evaluation benchmark, we include 9x more points that go out-of-view and 59x more points that require re-identification (ReID) after returning to view. To measure the performance of models on these challenging points, we introduce evaluation metrics that specifically monitor tracking performance on points in-view, out-of-view, and points that require re-identification. We then propose a pipeline to create semi-real sequences, with automatic ground truth. We generate 11K such sequences by combining dynamic Kubric objects with scene points from EPIC Fields. When fine-tuning point tracking methods on these sequences and evaluating on our annotated EgoPoints sequences, we improve CoTracker across all metrics, including the tracking accuracy $\delta^\star_{\text{avg}}$ by 2.7 percentage points and accuracy on ReID sequences (ReID$\delta_{\text{avg}}$) by 2.4 points. We also improve $\delta^\star_{\text{avg}}$ and ReID$\delta_{\text{avg}}$ of PIPs++ by 0.3 and 2.8 respectively.