 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePinCLIP: Large-scale Foundational Multimodal Representation at Pinterest
Mar 03, 2026While multi-modal Visual Language Models (VLMs) have demonstrated significant success across various domains, the integration of VLMs into recommendation and retrieval systems remains a challenge, due to issues like training objective discrepancies and serving efficiency bottlenecks. This paper introduces PinCLIP, a large-scale visual representation learning approach developed to enhance retrieval and ranking models at Pinterest by leveraging VLMs to learn image-text alignment. We propose a novel hybrid Vision Transformer architecture that utilizes a VLM backbone and a hybrid fusion mechanism to capture multi-modality content representation at varying granularities. Beyond standard image-to-text alignment objectives, we introduce a neighbor alignment objective to model the cross-fusion of multi-modal representations within the Pinterest Pin-Board graph. Offline evaluations show that PinCLIP outperforms state-of-the-art baselines, such as Qwen, by 20% in multi-modal retrieval tasks. Online A/B testing demonstrates significant business impact, including substantial engagement gains across all major surfaces in Pinterest. Notably, PinCLIP significantly addresses the "cold-start" problem, enhancing fresh content distribution with a 15% Repin increase in organic content and 8.7% higher click for new Ads.
Video Moment Retrieval via Natural Language Queries
Sep 10, 2020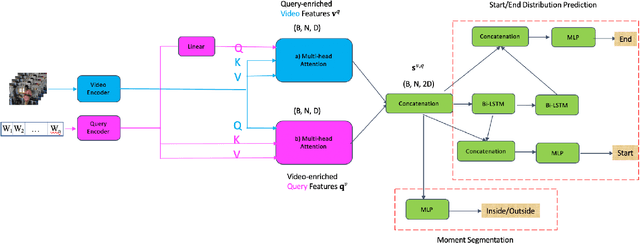
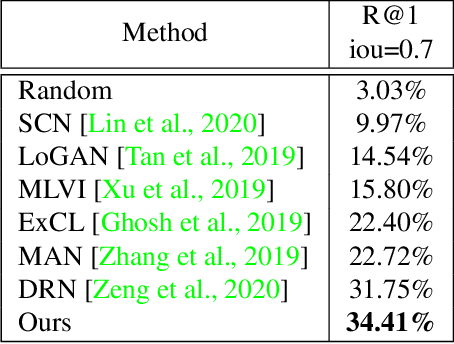
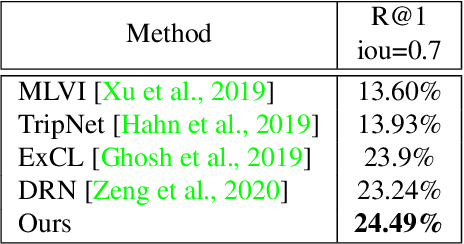
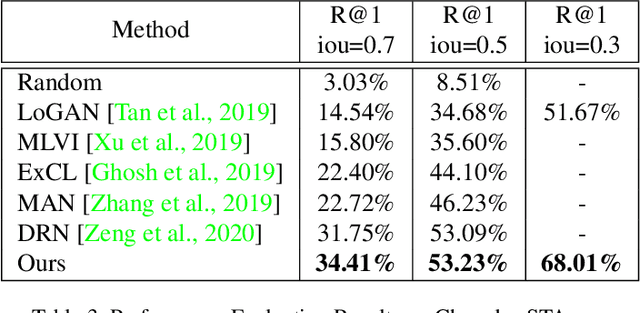
In this paper, we propose a novel method for video moment retrieval (VMR) that achieves state of the arts (SOTA) performance on R@1 metrics and surpassing the SOTA on the high IoU metric (R@1, IoU=0.7). First, we propose to use a multi-head self-attention mechanism, and further a cross-attention scheme to capture video/query interaction and long-range query dependencies from video context. The attention-based methods can develop frame-to-query interaction and query-to-frame interaction at arbitrary positions and the multi-head setting ensures the sufficient understanding of complicated dependencies. Our model has a simple architecture, which enables faster training and inference while maintaining . Second, We also propose to use multiple task training objective consists of moment segmentation task, start/end distribution prediction and start/end location regression task. We have verified that start/end prediction are noisy due to annotator disagreement and joint training with moment segmentation task can provide richer information since frames inside the target clip are also utilized as positive training examples. Third, we propose to use an early fusion approach, which achieves better performance at the cost of inference time. However, the inference time will not be a problem for our model since our model has a simple architecture which enables efficient training and inference.