 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Feature Modulator for Long-tailed Recognition
Aug 08, 2020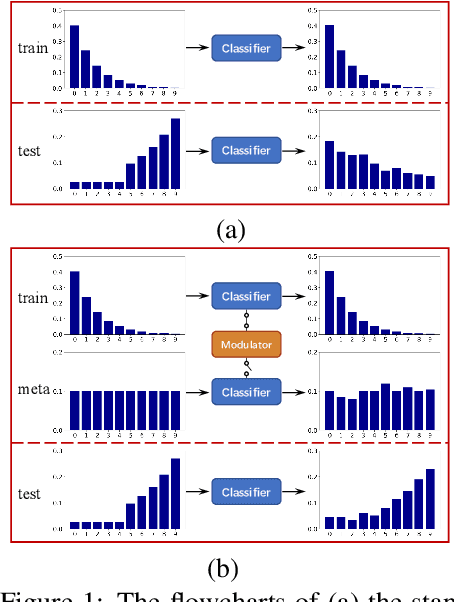
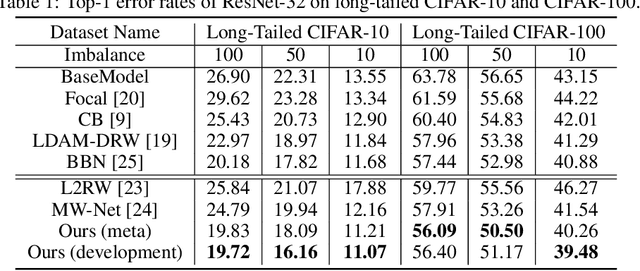
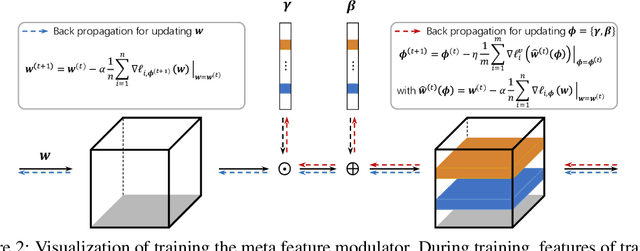

Deep neural networks often degrade significantly when training data suffer from class imbalance problems. Existing approaches, e.g., re-sampling and re-weighting, commonly address this issue by rearranging the label distribution of training data to train the networks fitting well to the implicit balanced label distribution. However, most of them hinder the representative ability of learned features due to insufficient use of intra/inter-sample information of training data. To address this issue, we propose meta feature modulator (MFM), a meta-learning framework to model the difference between the long-tailed training data and the balanced meta data from the perspective of representation learning. Concretely, we employ learnable hyper-parameters (dubbed modulation parameters) to adaptively scale and shift the intermediate features of classification networks, and the modulation parameters are optimized together with the classification network parameters guided by a small amount of balanced meta data. We further design a modulator network to guide the generation of the modulation parameters, and such a meta-learner can be readily adapted to train the classification network on other long-tailed datasets. Extensive experiments on benchmark vision datasets substantiate the superiority of our approach on long-tailed recognition tasks beyond other state-of-the-art methods.
LT-Net: Label Transfer by Learning Reversible Voxel-wise Correspondence for One-shot Medical Image Segmentation
Mar 20, 2020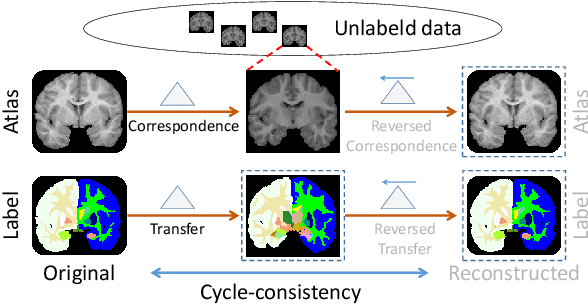
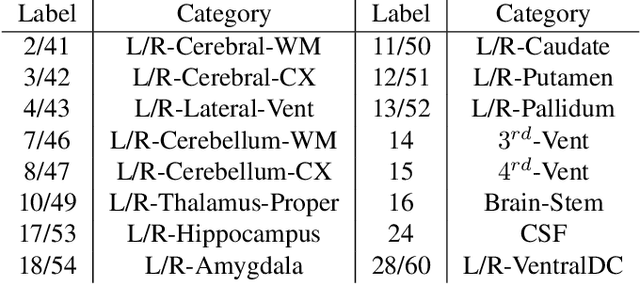
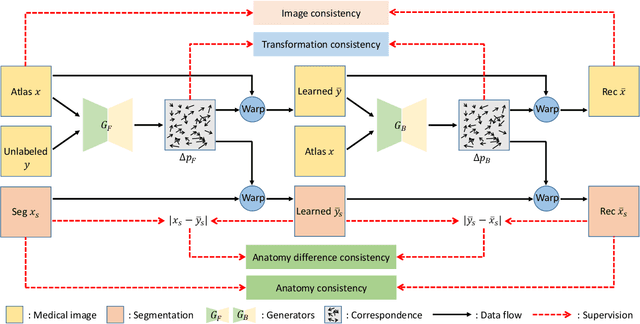
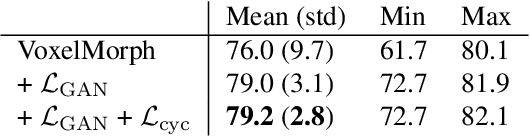
We introduce a one-shot segmentation method to alleviate the burden of manual annotation for medical images. The main idea is to treat one-shot segmentation as a classical atlas-based segmentation problem, where voxel-wise correspondence from the atlas to the unlabelled data is learned. Subsequently, segmentation label of the atlas can be transferred to the unlabelled data with the learned correspondence. However, since ground truth correspondence between images is usually unavailable, the learning system must be well-supervised to avoid mode collapse and convergence failure. To overcome this difficulty, we resort to the forward-backward consistency, which is widely used in correspondence problems, and additionally learn the backward correspondences from the warped atlases back to the original atlas. This cycle-correspondence learning design enables a variety of extra, cycle-consistency-based supervision signals to make the training process stable, while also boost the performance. We demonstrate the superiority of our method over both deep learning-based one-shot segmentation methods and a classical multi-atlas segmentation method via thorough experiments.