 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFishers Harvest Parallel Unlearning in Inherited Model Networks
Aug 16, 2024



Unlearning in various learning frameworks remains challenging, with the continuous growth and updates of models exhibiting complex inheritance relationships. This paper presents a novel unlearning framework, which enables fully parallel unlearning among models exhibiting inheritance. A key enabler is the new Unified Model Inheritance Graph (UMIG), which captures the inheritance using a Directed Acyclic Graph (DAG).Central to our framework is the new Fisher Inheritance Unlearning (FIUn) algorithm, which utilizes the Fisher Information Matrix (FIM) from initial unlearning models to pinpoint impacted parameters in inherited models. By employing FIM, the FIUn method breaks the sequential dependencies among the models, facilitating simultaneous unlearning and reducing computational overhead. We further design to merge disparate FIMs into a single matrix, synchronizing updates across inherited models. Experiments confirm the effectiveness of our unlearning framework. For single-class tasks, it achieves complete unlearning with 0\% accuracy for unlearned labels while maintaining 94.53\% accuracy for retained labels on average. For multi-class tasks, the accuracy is 1.07\% for unlearned labels and 84.77\% for retained labels on average. Our framework accelerates unlearning by 99\% compared to alternative methods.
Decentralized Federated Unlearning on Blockchain
Feb 26, 2024



Blockchained Federated Learning (FL) has been gaining traction for ensuring the integrity and traceability of FL processes. Blockchained FL involves participants training models locally with their data and subsequently publishing the models on the blockchain, forming a Directed Acyclic Graph (DAG)-like inheritance structure that represents the model relationship. However, this particular DAG-based structure presents challenges in updating models with sensitive data, due to the complexity and overhead involved. To address this, we propose Blockchained Federated Unlearning (BlockFUL), a generic framework that redesigns the blockchain structure using Chameleon Hash (CH) technology to mitigate the complexity of model updating, thereby reducing the computational and consensus costs of unlearning tasks.Furthermore, BlockFUL supports various federated unlearning methods, ensuring the integrity and traceability of model updates, whether conducted in parallel or serial. We conduct a comprehensive study of two typical unlearning methods, gradient ascent and re-training, demonstrating the efficient unlearning workflow in these two categories with minimal CH and block update operations. Additionally, we compare the computation and communication costs of these methods.
FedGroup: Ternary Cosine Similarity-based Clustered Federated Learning Framework toward High Accuracy in Heterogeneous Data
Oct 15, 2020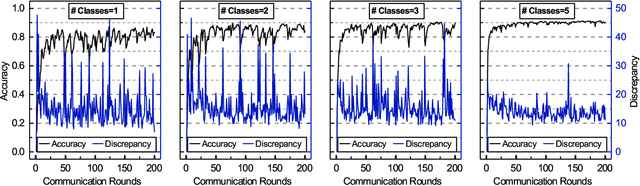
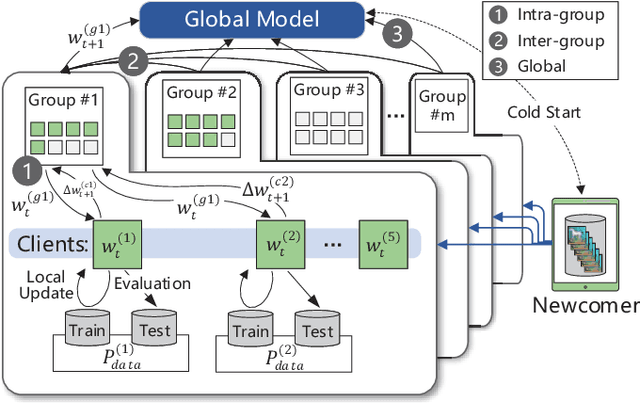
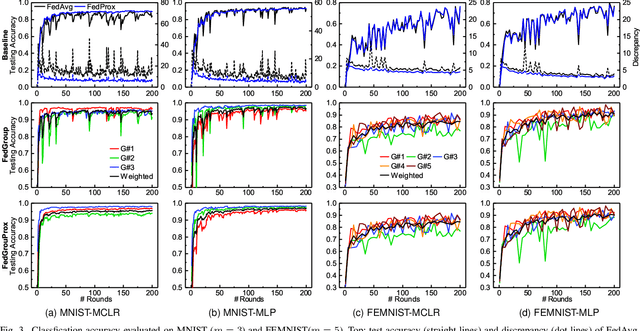
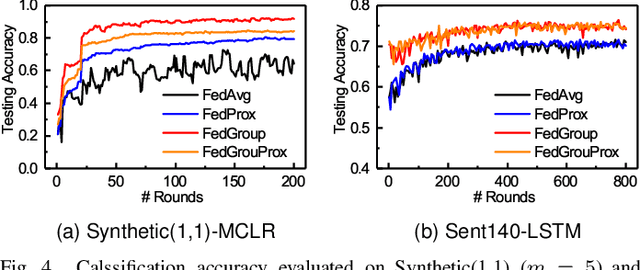
Federated Learning (FL) enables the multiple participating devices to collaboratively contribute to a global neural network model while keeping the training data locally. Unlike the centralized training setting, the non-IID and imbalanced (statistical heterogeneity) training data of FL is distributed in the federated network, which will increase the divergences between the local models and global model and further degrade the performance. In this paper, we propose a novel federated learning framework FedGroup based on a similarity-based clustering strategy, in which we 1) group the training of clients based on the similarities between the clients' optimize directions; 2) reduce the complexity of high-dimension low-sample size (HDLSS) parameter updates data clustering by decomposing the direction vectors to derive the ternary cosine similarity. FedGroup can achieve improvements by dividing joint optimization into groups of sub-optimization, and can be combined with FedProx, the state-of-the-art federated optimization algorithm. We evaluate FedGroup and FedGrouProx (combined with FedProx) on several open datasets. The experimental results show that our proposed frameworks significantly improving absolute test accuracy by +14.7% on FEMNIST compared to FedAvg, +5.4% on Sentiment140 compared to FedProx.