 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modality-level Explainable Framework for Misinformation Checking in Social Networks
Dec 08, 2022


The widespread of false information is a rising concern worldwide with critical social impact, inspiring the emergence of fact-checking organizations to mitigate misinformation dissemination. However, human-driven verification leads to a time-consuming task and a bottleneck to have checked trustworthy information at the same pace they emerge. Since misinformation relates not only to the content itself but also to other social features, this paper addresses automatic misinformation checking in social networks from a multimodal perspective. Moreover, as simply naming a piece of news as incorrect may not convince the citizen and, even worse, strengthen confirmation bias, the proposal is a modality-level explainable-prone misinformation classifier framework. Our framework comprises a misinformation classifier assisted by explainable methods to generate modality-oriented explainable inferences. Preliminary findings show that the misinformation classifier does benefit from multimodal information encoding and the modality-oriented explainable mechanism increases both inferences' interpretability and completeness.
Learning Attention-based Representations from Multiple Patterns for Relation Prediction in Knowledge Graphs
Jun 07, 2022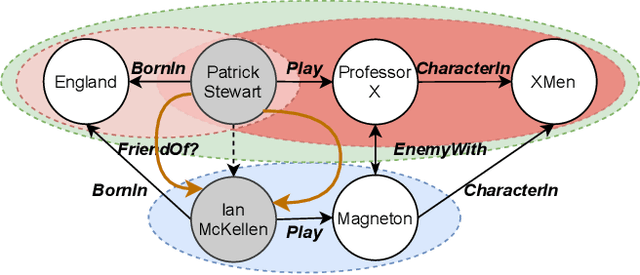
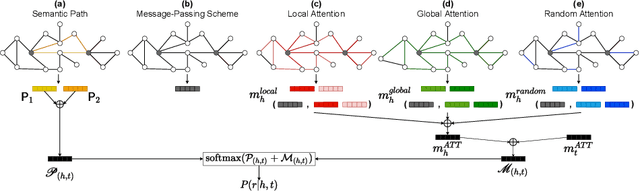
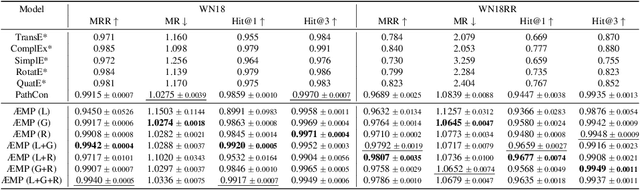
Knowledge bases, and their representations in the form of knowledge graphs (KGs), are naturally incomplete. Since scientific and industrial applications have extensively adopted them, there is a high demand for solutions that complete their information. Several recent works tackle this challenge by learning embeddings for entities and relations, then employing them to predict new relations among the entities. Despite their aggrandizement, most of those methods focus only on the local neighbors of a relation to learn the embeddings. As a result, they may fail to capture the KGs' context information by neglecting long-term dependencies and the propagation of entities' semantics. In this manuscript, we propose {\AE}MP (Attention-based Embeddings from Multiple Patterns), a novel model for learning contextualized representations by: (i) acquiring entities' context information through an attention-enhanced message-passing scheme, which captures the entities' local semantics while focusing on different aspects of their neighborhood; and (ii) capturing the semantic context, by leveraging the paths and their relationships between entities. Our empirical findings draw insights into how attention mechanisms can improve entities' context representation and how combining entities and semantic path contexts improves the general representation of entities and the relation predictions. Experimental results on several large and small knowledge graph benchmarks show that {\AE}MP either outperforms or competes with state-of-the-art relation prediction methods.
Workflow Provenance in the Lifecycle of Scientific Machine Learning
Sep 30, 2020

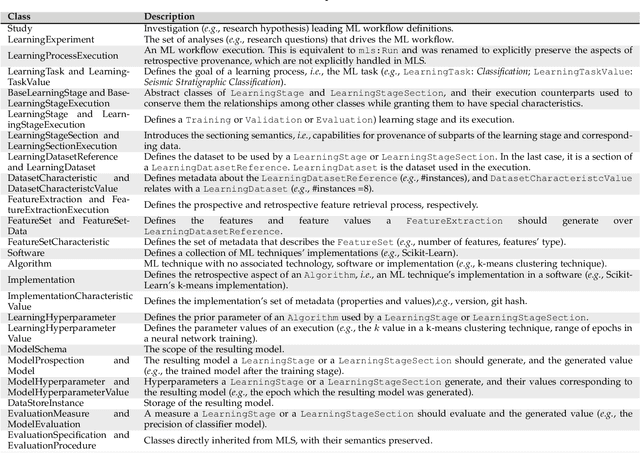

Machine Learning (ML) has already fundamentally changed several businesses. More recently, it has also been profoundly impacting the computational science and engineering domains, like geoscience, climate science, and health science. In these domains, users need to perform comprehensive data analyses combining scientific data and ML models to provide for critical requirements, such as reproducibility, model explainability, and experiment data understanding. However, scientific ML is multidisciplinary, heterogeneous, and affected by the physical constraints of the domain, making such analyses even more challenging. In this work, we leverage workflow provenance techniques to build a holistic view to support the lifecycle of scientific ML. We contribute with (i) characterization of the lifecycle and taxonomy for data analyses; (ii) design principles to build this view, with a W3C PROV compliant data representation and a reference system architecture; and (iii) lessons learned after an evaluation in an Oil & Gas case using an HPC cluster with 393 nodes and 946 GPUs. The experiments show that the principles enable queries that integrate domain semantics with ML models while keeping low overhead (<1%), high scalability, and an order of magnitude of query acceleration under certain workloads against without our representation.
Managing Machine Learning Workflow Components
Dec 10, 2019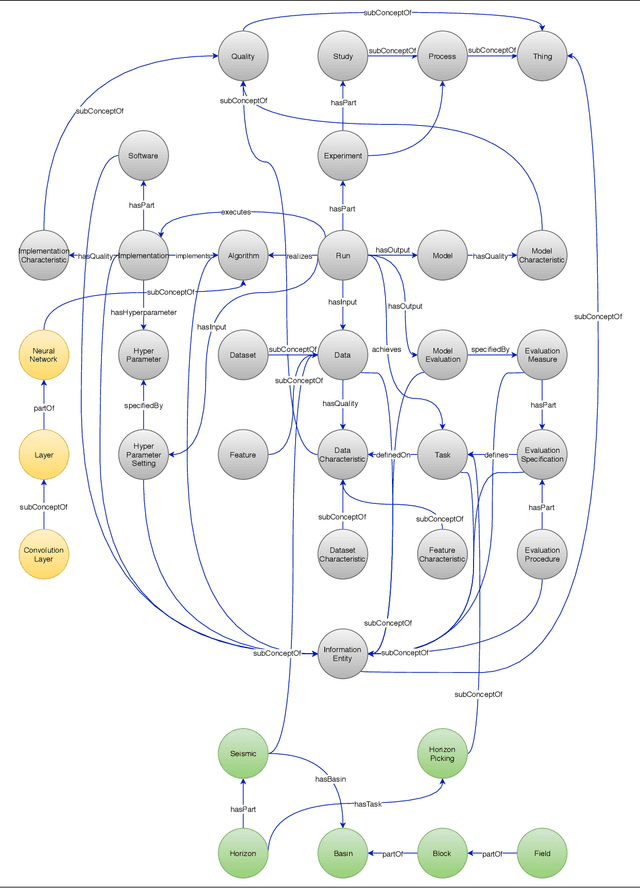
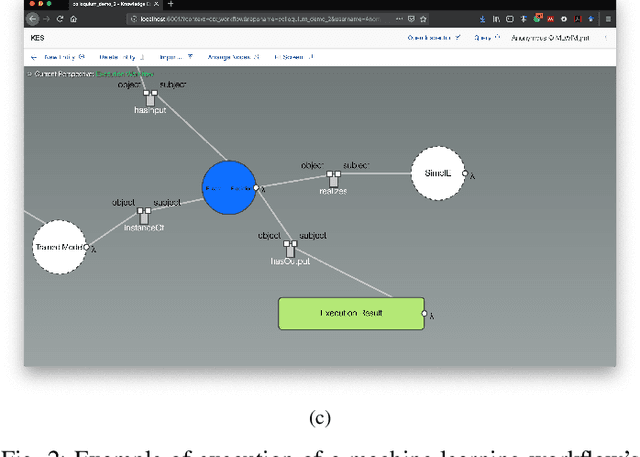
Machine Learning Workflows~(MLWfs) have become essential and a disruptive approach in problem-solving over several industries. However, the development process of MLWfs may be complicated, hard to achieve, time-consuming, and error-prone. To handle this problem, in this paper, we introduce \emph{machine learning workflow management}~(MLWfM) as a technique to aid the development and reuse of MLWfs and their components through three aspects: representation, execution, and creation. More precisely, we discuss our approach to structure the MLWfs' components and their metadata to aid retrieval and reuse of components in new MLWfs. Also, we consider the execution of these components within a tool. The hybrid knowledge representation, called Hyperknowledge, frames our methodology, supporting the three MLWfM's aspects. To validate our approach, we show a practical use case in the Oil \& Gas industry.
Provenance Data in the Machine Learning Lifecycle in Computational Science and Engineering
Oct 21, 2019
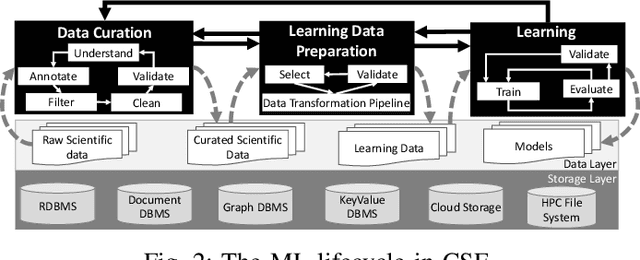
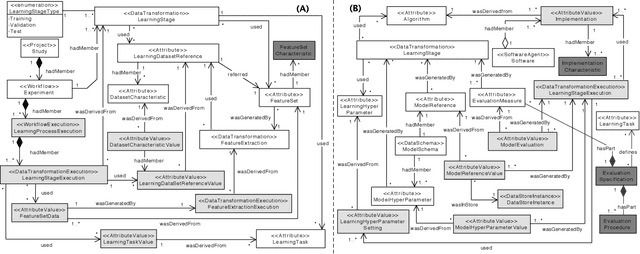
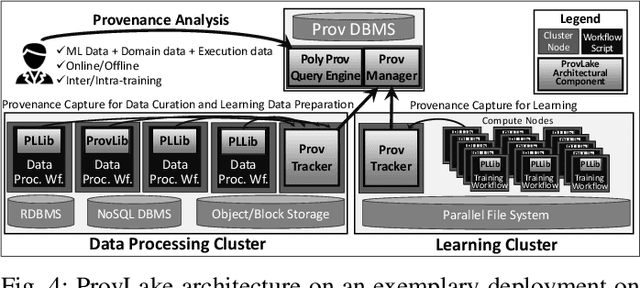
Machine Learning (ML) has become essential in several industries. In Computational Science and Engineering (CSE), the complexity of the ML lifecycle comes from the large variety of data, scientists' expertise, tools, and workflows. If data are not tracked properly during the lifecycle, it becomes unfeasible to recreate a ML model from scratch or to explain to stakeholders how it was created. The main limitation of provenance tracking solutions is that they cannot cope with provenance capture and integration of domain and ML data processed in the multiple workflows in the lifecycle while keeping the provenance capture overhead low. To handle this problem, in this paper we contribute with a detailed characterization of provenance data in the ML lifecycle in CSE; a new provenance data representation, called PROV-ML, built on top of W3C PROV and ML Schema; and extensions to a system that tracks provenance from multiple workflows to address the characteristics of ML and CSE, and to allow for provenance queries with a standard vocabulary. We show a practical use in a real case in the Oil and Gas industry, along with its evaluation using 48 GPUs in parallel.