 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Complexity of HEVC: A Deep Learning Approach
Mar 22, 2018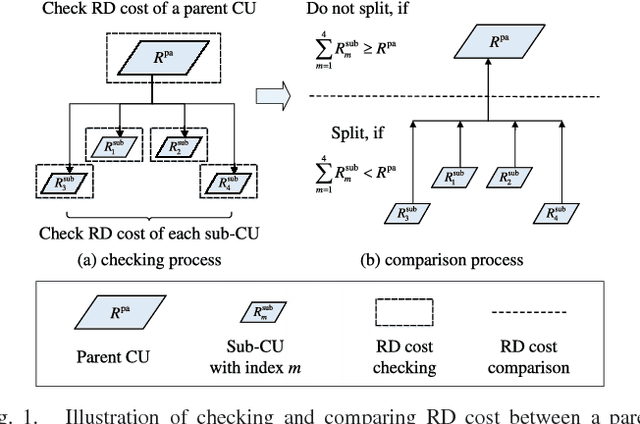
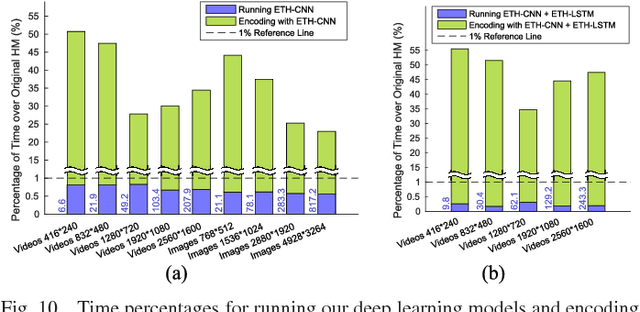
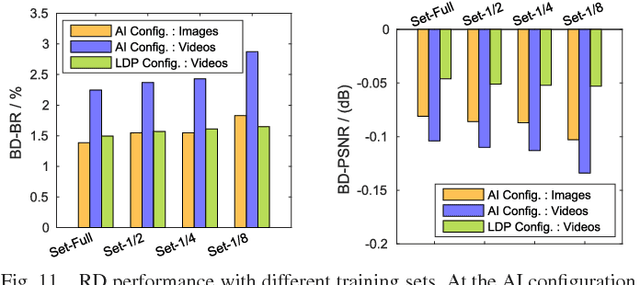
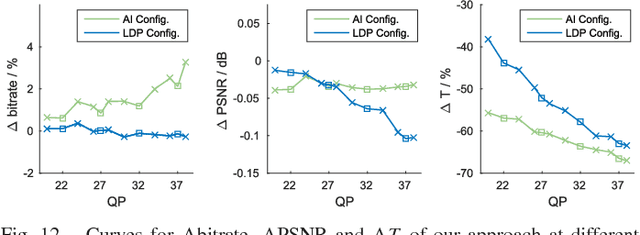
High Efficiency Video Coding (HEVC) significantly reduces bit-rates over the proceeding H.264 standard but at the expense of extremely high encoding complexity. In HEVC, the quad-tree partition of coding unit (CU) consumes a large proportion of the HEVC encoding complexity, due to the bruteforce search for rate-distortion optimization (RDO). Therefore, this paper proposes a deep learning approach to predict the CU partition for reducing the HEVC complexity at both intra- and inter-modes, which is based on convolutional neural network (CNN) and long- and short-term memory (LSTM) network. First, we establish a large-scale database including substantial CU partition data for HEVC intra- and inter-modes. This enables deep learning on the CU partition. Second, we represent the CU partition of an entire coding tree unit (CTU) in the form of a hierarchical CU partition map (HCPM). Then, we propose an early-terminated hierarchical CNN (ETH-CNN) for learning to predict the HCPM. Consequently, the encoding complexity of intra-mode HEVC can be drastically reduced by replacing the brute-force search with ETH-CNN to decide the CU partition. Third, an early-terminated hierarchical LSTM (ETH-LSTM) is proposed to learn the temporal correlation of the CU partition. Then, we combine ETH-LSTM and ETH-CNN to predict the CU partition for reducing the HEVC complexity for inter-mode. Finally, experimental results show that our approach outperforms other state-of-the-art approaches in reducing the HEVC complexity at both intra- and inter-modes.
Multi-Frame Quality Enhancement for Compressed Video
Mar 16, 2018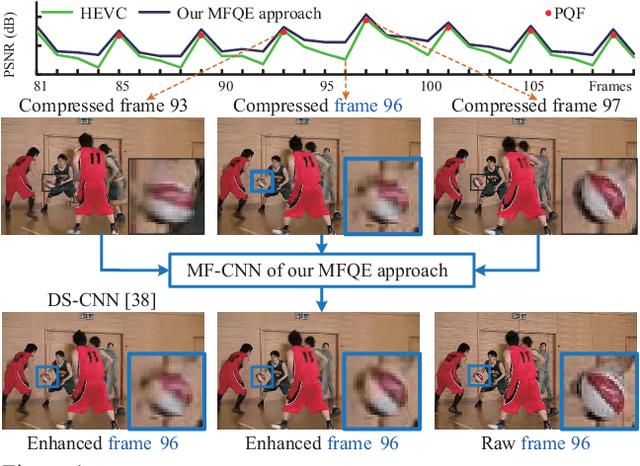
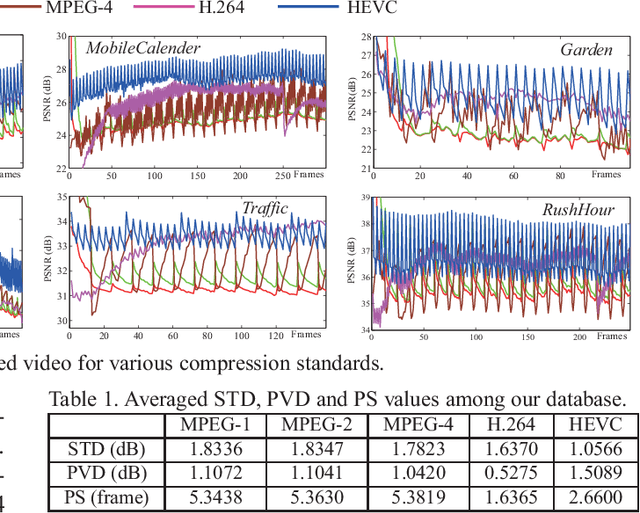
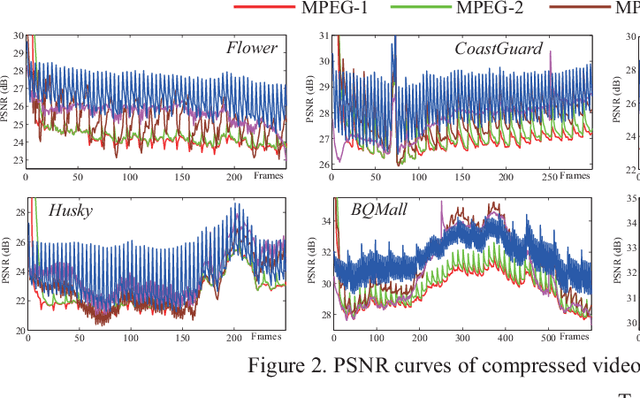
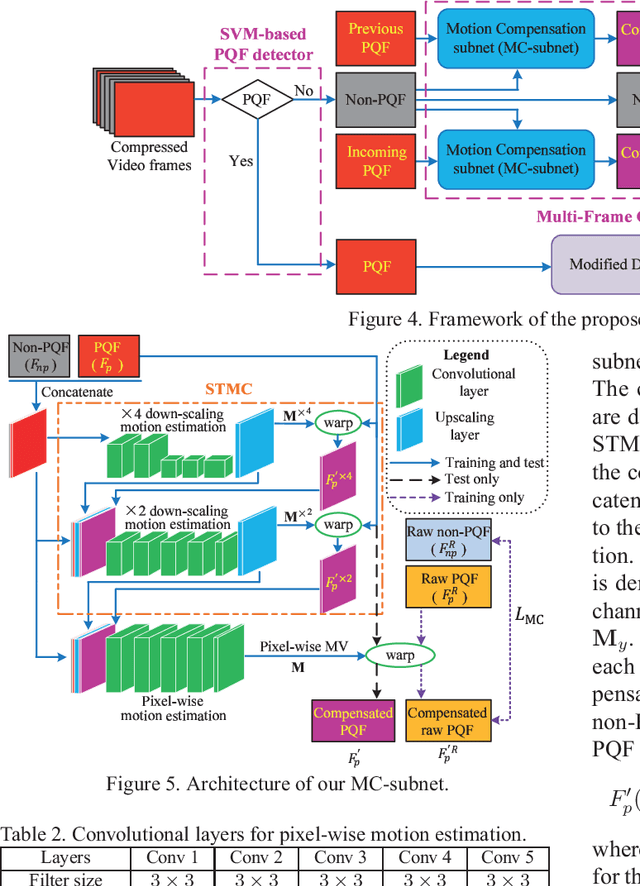
The past few years have witnessed great success in applying deep learning to enhance the quality of compressed image/video. The existing approaches mainly focus on enhancing the quality of a single frame, ignoring the similarity between consecutive frames. In this paper, we investigate that heavy quality fluctuation exists across compressed video frames, and thus low quality frames can be enhanced using the neighboring high quality frames, seen as Multi-Frame Quality Enhancement (MFQE). Accordingly, this paper proposes an MFQE approach for compressed video, as a first attempt in this direction. In our approach, we firstly develop a Support Vector Machine (SVM) based detector to locate Peak Quality Frames (PQFs) in compressed video. Then, a novel Multi-Frame Convolutional Neural Network (MF-CNN) is designed to enhance the quality of compressed video, in which the non-PQF and its nearest two PQFs are as the input. The MF-CNN compensates motion between the non-PQF and PQFs through the Motion Compensation subnet (MC-subnet). Subsequently, the Quality Enhancement subnet (QE-subnet) reduces compression artifacts of the non-PQF with the help of its nearest PQFs. Finally, the experiments validate the effectiveness and generality of our MFQE approach in advancing the state-of-the-art quality enhancement of compressed video. The code of our MFQE approach is available at https://github.com/ryangBUAA/MFQE.git