 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSite-Specific Finetuning of Neural Receivers with Real-World 5G NR Measurements
Mar 10, 2026Finetuning wireless receivers to a specific deployment scenario can yield significant error-rate performance improvements without increasing processing complexity. However, site-specific finetuning has so far only been demonstrated on synthetic channel data and lacks real-world benchmarks. In this work, we empirically study site-specific finetuning of neural receivers using real-world 5G NR physical uplink shared channel (PUSCH) data collected with an over-the-air testbed at ETH Zurich across three scenarios: (i) a small laboratory, (ii) a large office floor, and (iii) a high-mobility outdoor environment. Our results confirm substantial error-rate performance improvements from site-specific finetuning, consistent with earlier findings based on synthetic channel data. Moreover, we demonstrate that these improvements generalize across different user-equipment hardware and deployment scenarios.
A 14ns-Latency 9Gb/s 0.44mm$^2$ 62pJ/b Short-Blocklength LDPC Decoder ASIC in 22FDX
Dec 19, 2025Ultra-reliable low latency communication (URLLC) is a key part of 5G wireless systems. Achieving low latency necessitates codes with short blocklengths for which polar codes with successive cancellation list (SCL) decoding typically outperform message-passing (MP)-based decoding of low-density parity-check (LDPC) codes. However, SCL decoders are known to exhibit high latency and poor area efficiency. In this paper, we propose a new short-blocklength multi-rate binary LDPC code that outperforms the 5G-LDPC code for the same blocklength and is suitable for URLLC applications using fully parallel MP. To demonstrate our code's efficacy, we present a 0.44mm$^2$ GlobalFoundries 22FDX LDPC decoder ASIC which supports three rates and achieves the lowest-in-class decoding latency of 14ns while reaching an information throughput of 9Gb/s at 62pJ/b energy efficiency for a rate-1/2 code with 128-bit blocklength.
CSI-Based User Positioning, Channel Charting, and Device Classification with an NVIDIA 5G Testbed
Dec 11, 2025Channel-state information (CSI)-based sensing will play a key role in future cellular systems. However, no CSI dataset has been published from a real-world 5G NR system that facilitates the development and validation of suitable sensing algorithms. To close this gap, we publish three real-world wideband multi-antenna multi-open RAN radio unit (O-RU) CSI datasets from the 5G NR uplink channel: an indoor lab/office room dataset, an outdoor campus courtyard dataset, and a device classification dataset with six commercial-off-the-shelf (COTS) user equipments (UEs). These datasets have been recorded using a software-defined 5G NR testbed based on NVIDIA Aerial RAN CoLab Over-the-Air (ARC-OTA) with COTS hardware, which we have deployed at ETH Zurich. We demonstrate the utility of these datasets for three CSI-based sensing tasks: neural UE positioning, channel charting in real-world coordinates, and closed-set device classification. For all these tasks, our results show high accuracy: neural UE positioning achieves 0.6cm (indoor) and 5.7cm (outdoor) mean absolute error, channel charting in real-world coordinates achieves 73cm mean absolute error (outdoor), and device classification achieves 99% (same day) and 95% (next day) accuracy. The CSI datasets, ground-truth UE position labels, CSI features, and simulation code are publicly available at https://caez.ethz.ch
Optimizing Puncturing Patterns of 5G NR LDPC Codes for Few-Iteration Decoding
Oct 28, 2024



Rate-matching of low-density parity-check (LDPC) codes enables a single code description to support a wide range of code lengths and rates. In 5G NR, rate matching is accomplished by extending (lifting) a base code to a desired target length and by puncturing (not transmitting) certain code bits. LDPC codes and rate matching are typically designed for the asymptotic performance limit with an ideal decoder. Practical LDPC decoders, however, carry out tens or fewer message-passing decoding iterations to achieve the target throughput and latency of modern wireless systems. We show that one can optimize LDPC code puncturing patterns for such few-iteration-constrained decoders using a method we call swapping of punctured and transmitted blocks (SPAT). Our simulation results show that SPAT yields from 0.20 dB up to 0.55 dB improved signal-to-noise ratio performance compared to the standard 5G NR LDPC code puncturing pattern for a wide range of code lengths and rates.
Design of a Standard-Compliant Real-Time Neural Receiver for 5G NR
Sep 04, 2024We detail the steps required to deploy a multi-user multiple-input multiple-output (MU-MIMO) neural receiver (NRX) in an actual cellular communication system. This raises several exciting research challenges, including the need for real-time inference and compatibility with the 5G NR standard. As the network configuration in a practical setup can change dynamically within milliseconds, we propose an adaptive NRX architecture capable of supporting dynamic modulation and coding scheme (MCS) configurations without the need for any re-training and without additional inference cost. We optimize the latency of the neural network (NN) architecture to achieve inference times of less than 1ms on an NVIDIA A100 GPU using the TensorRT inference library. These latency constraints effectively limit the size of the NN and we quantify the resulting signal-to-noise ratio (SNR) degradation as less than 0.7 dB when compared to a preliminary non-real-time NRX architecture. Finally, we explore the potential for site-specific adaptation of the receiver by investigating the required size of the training dataset and the number of fine-tuning iterations to optimize the NRX for specific radio environments using a ray tracing-based channel model. The resulting NRX is ready for deployment in a real-time 5G NR system and the source code including the TensorRT experiments is available online.
PyJama: Differentiable Jamming and Anti-Jamming with NVIDIA Sionna
Jul 22, 2024



Despite extensive research on jamming attacks on wireless communication systems, the potential of machine learning for amplifying the threat of such attacks, or our ability to mitigate them, remains largely untapped. A key obstacle to such research has been the absence of a suitable framework. To resolve this obstacle, we release PyJama, a fully-differentiable open-source library that adds jamming and anti-jamming functionality to NVIDIA Sionna. We demonstrate the utility of PyJama (i) for realistic MIMO simulations by showing examples that involve forward error correction, OFDM waveforms in time and frequency, realistic channel models, and mobility; and (ii) for learning to jam. Specifically, we use stochastic gradient descent to optimize jamming power allocation over an OFDM resource grid. The learned strategies are non-trivial, intelligible, and effective.
LoFi User Scheduling for Multiuser MIMO Wireless Systems
Jan 08, 2024



We propose new low-fidelity (LoFi) user equipment (UE) scheduling algorithms for multiuser multiple-input multiple-output (MIMO) wireless communication systems. The proposed methods rely on an efficient guess-and-check procedure that, given an objective function, performs paired comparisons between random subsets of UEs that should be scheduled in certain time slots. The proposed LoFi scheduling methods are computationally efficient, highly parallelizable, and gradient-free, which enables the use of almost arbitrary, non-differentiable objective functions. System simulations in a millimeter-wave (mmWave) multiuser MIMO scenario demonstrate that the proposed LoFi schedulers outperform a range of state-of-the-art user scheduling algorithms in terms of bit error-rate and/or computational complexity.
DUIDD: Deep-Unfolded Interleaved Detection and Decoding for MIMO Wireless Systems
Dec 15, 2022



Iterative detection and decoding (IDD) is known to achieve near-capacity performance in multi-antenna wireless systems. We propose deep-unfolded interleaved detection and decoding (DUIDD), a new paradigm that reduces the complexity of IDD while achieving even lower error rates. DUIDD interleaves the inner stages of the data detector and channel decoder, which expedites convergence and reduces complexity. Furthermore, DUIDD applies deep unfolding to automatically optimize algorithmic hyperparameters, soft-information exchange, message damping, and state forwarding. We demonstrate the efficacy of DUIDD using NVIDIA's Sionna link-level simulator in a 5G-near multi-user MIMO-OFDM wireless system with a novel low-complexity soft-input soft-output data detector, an optimized low-density parity-check decoder, and channel vectors from a commercial ray-tracer. Our results show that DUIDD outperforms classical IDD both in terms of block error rate and computational complexity.
Bit Error and Block Error Rate Training for ML-Assisted Communication
Oct 25, 2022



Even though machine learning (ML) techniques are being widely used in communications, the question of how to train communication systems has received surprisingly little attention. In this paper, we show that the commonly used binary cross-entropy (BCE) loss is a sensible choice in uncoded systems, e.g., for training ML-assisted data detectors, but may not be optimal in coded systems. We propose new loss functions targeted at minimizing the block error rate and SNR de-weighting, a novel method that trains communication systems for optimal performance over a range of signal-to-noise ratios. The utility of the proposed loss functions as well as of SNR de-weighting is shown through simulations in NVIDIA Sionna.
Distributed Joint Multi-cell Optimization of IRS Parameters with Linear Precoders
Oct 28, 2021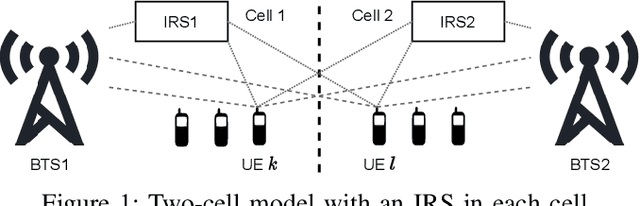
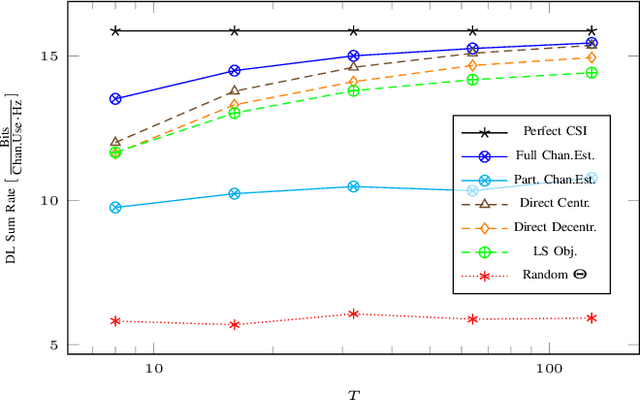
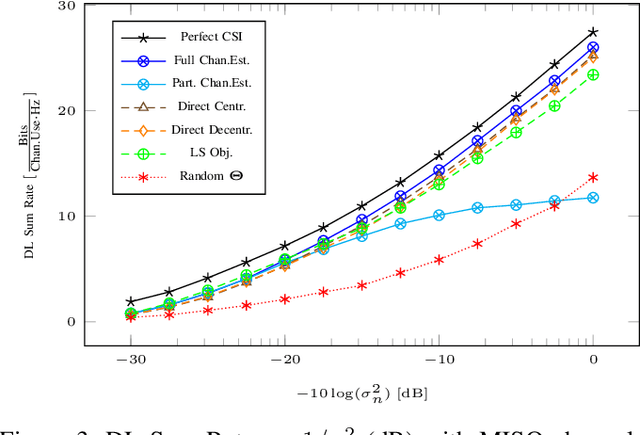
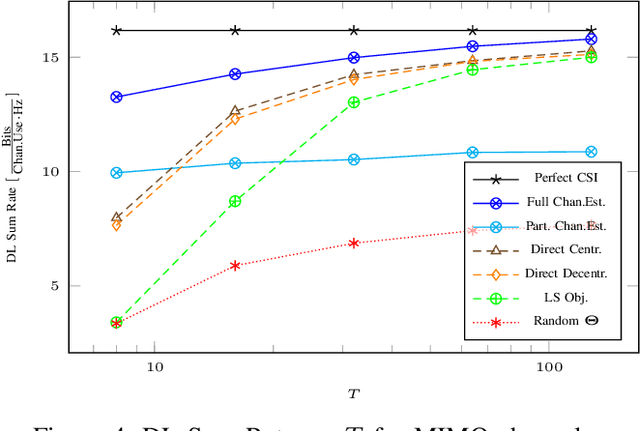
We present distributed methods for jointly optimizing Intelligent Reflecting Surface (IRS) phase-shifts and beamformers in a cellular network. The proposed schemes require knowledge of only the intra-cell training sequences and corresponding received signals without explicit channel estimation. Instead, an SINR objective is estimated via sample means and maximized directly. This automatically includes and mitigates both intra- and inter-cell interference provided that the uplink training is synchronized across cells. Different schemes are considered that limit the set of known training sequences from interferers. With MIMO links an iterative synchronous bi-directional training scheme jointly optimizes the IRS parameters with the beamformers and combiners. Simulation results show that the proposed distributed methods show a modest performance degradation compared to centralized channel estimation schemes, which estimate and exchange all cross-channels between cells, and perform significantly better than channel estimation schemes which ignore the inter-cell interference.