 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Opinion Mining: Summarizing Opinions of Customer Reviews
Jun 03, 2022
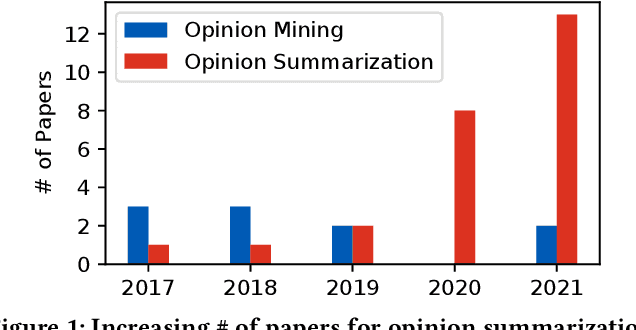
Customer reviews are vital for making purchasing decisions in the Information Age. Such reviews can be automatically summarized to provide the user with an overview of opinions. In this tutorial, we present various aspects of opinion summarization that are useful for researchers and practitioners. First, we will introduce the task and major challenges. Then, we will present existing opinion summarization solutions, both pre-neural and neural. We will discuss how summarizers can be trained in the unsupervised, few-shot, and supervised regimes. Each regime has roots in different machine learning methods, such as auto-encoding, controllable text generation, and variational inference. Finally, we will discuss resources and evaluation methods and conclude with the future directions. This three-hour tutorial will provide a comprehensive overview over major advances in opinion summarization. The listeners will be well-equipped with the knowledge that is both useful for research and practical applications.
Efficient Attribute Injection for Pretrained Language Models
Sep 16, 2021
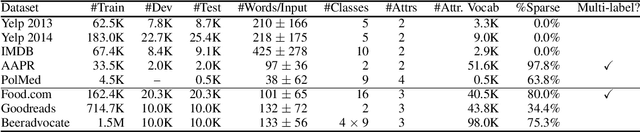
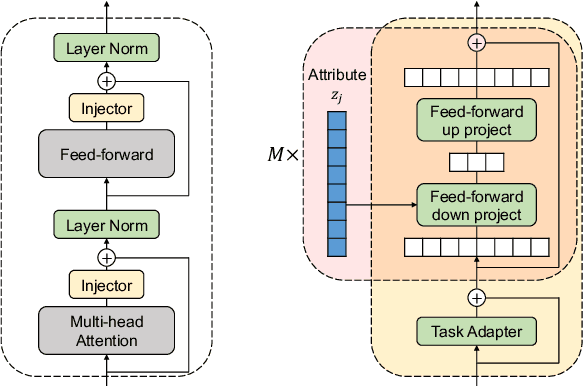
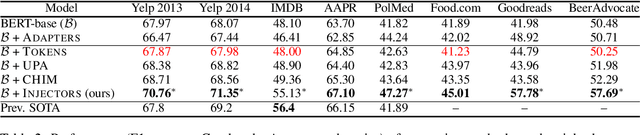
Metadata attributes (e.g., user and product IDs from reviews) can be incorporated as additional inputs to neural-based NLP models, by modifying the architecture of the models, in order to improve their performance. Recent models however rely on pretrained language models (PLMs), where previously used techniques for attribute injection are either nontrivial or ineffective. In this paper, we propose a lightweight and memory-efficient method to inject attributes to PLMs. We extend adapters, i.e. tiny plug-in feed-forward modules, to include attributes both independently of or jointly with the text. To limit the increase of parameters especially when the attribute vocabulary is large, we use low-rank approximations and hypercomplex multiplications, significantly decreasing the total parameters. We also introduce training mechanisms to handle domains in which attributes can be multi-labeled or sparse. Extensive experiments and analyses on eight datasets from different domains show that our method outperforms previous attribute injection methods and achieves state-of-the-art performance on various datasets.
Aspect-Controllable Opinion Summarization
Sep 07, 2021
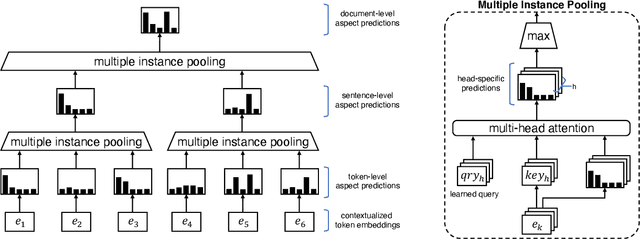
Recent work on opinion summarization produces general summaries based on a set of input reviews and the popularity of opinions expressed in them. In this paper, we propose an approach that allows the generation of customized summaries based on aspect queries (e.g., describing the location and room of a hotel). Using a review corpus, we create a synthetic training dataset of (review, summary) pairs enriched with aspect controllers which are induced by a multi-instance learning model that predicts the aspects of a document at different levels of granularity. We fine-tune a pretrained model using our synthetic dataset and generate aspect-specific summaries by modifying the aspect controllers. Experiments on two benchmarks show that our model outperforms the previous state of the art and generates personalized summaries by controlling the number of aspects discussed in them.
Unsupervised Opinion Summarization with Content Planning
Dec 14, 2020
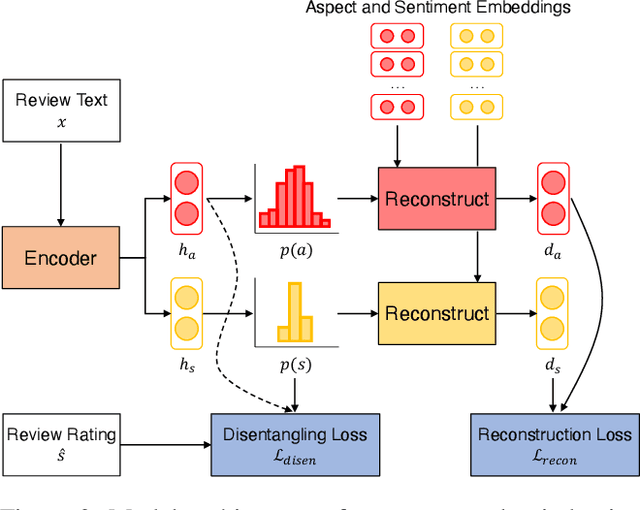
The recent success of deep learning techniques for abstractive summarization is predicated on the availability of large-scale datasets. When summarizing reviews (e.g., for products or movies), such training data is neither available nor can be easily sourced, motivating the development of methods which rely on synthetic datasets for supervised training. We show that explicitly incorporating content planning in a summarization model not only yields output of higher quality, but also allows the creation of synthetic datasets which are more natural, resembling real world document-summary pairs. Our content plans take the form of aspect and sentiment distributions which we induce from data without access to expensive annotations. Synthetic datasets are created by sampling pseudo-reviews from a Dirichlet distribution parametrized by our content planner, while our model generates summaries based on input reviews and induced content plans. Experimental results on three domains show that our approach outperforms competitive models in generating informative, coherent, and fluent summaries that capture opinion consensus.
Extractive Opinion Summarization in Quantized Transformer Spaces
Dec 08, 2020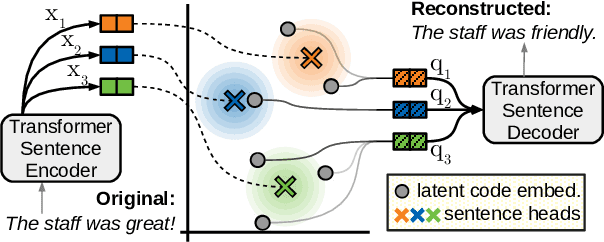

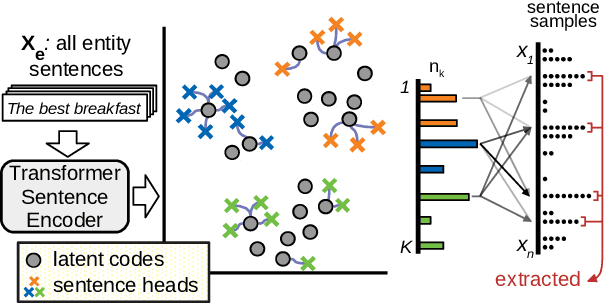
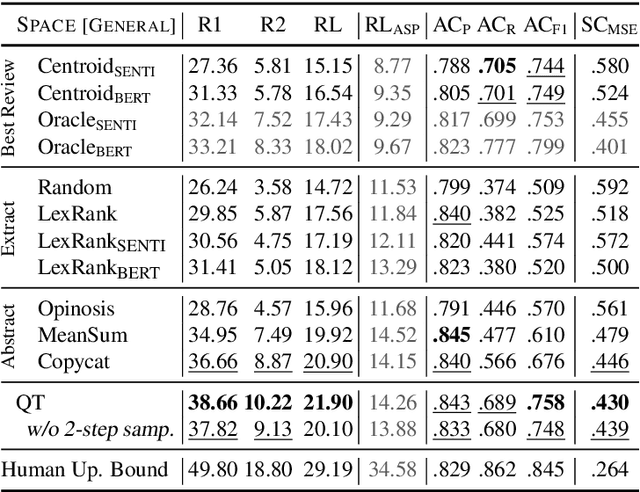
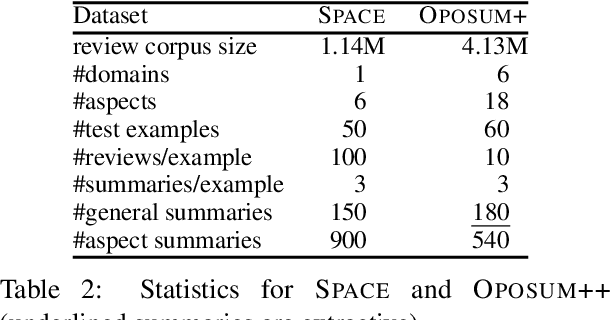
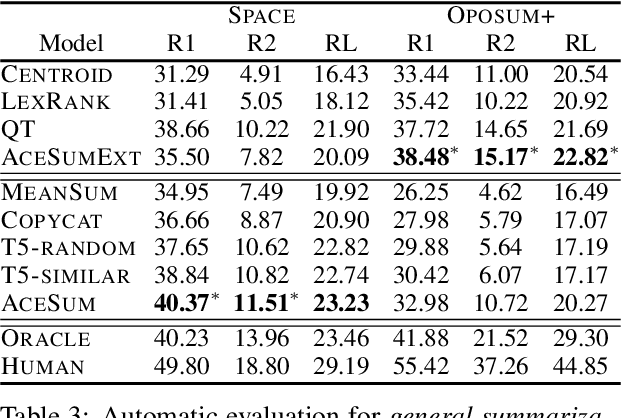
We present the Quantized Transformer (QT), an unsupervised system for extractive opinion summarization. QT is inspired by Vector-Quantized Variational Autoencoders, which we repurpose for popularity-driven summarization. It uses a clustering interpretation of the quantized space and a novel extraction algorithm to discover popular opinions among hundreds of reviews, a significant step towards opinion summarization of practical scope. In addition, QT enables controllable summarization without further training, by utilizing properties of the quantized space to extract aspect-specific summaries. We also make publicly available SPACE, a large-scale evaluation benchmark for opinion summarizers, comprising general and aspect-specific summaries for 50 hotels. Experiments demonstrate the promise of our approach, which is validated by human studies where judges showed clear preference for our method over competitive baselines.
Heads-up! Unsupervised Constituency Parsing via Self-Attention Heads
Oct 19, 2020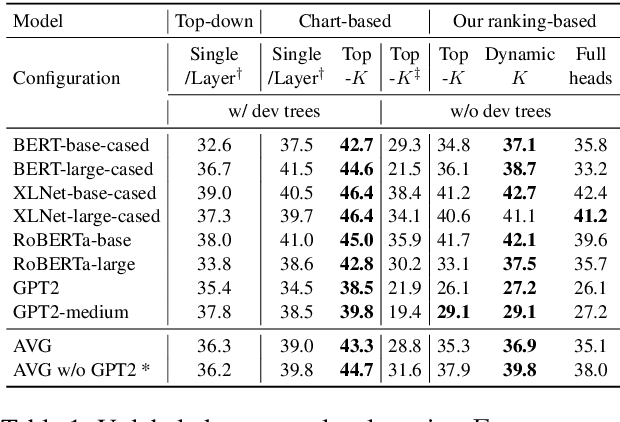
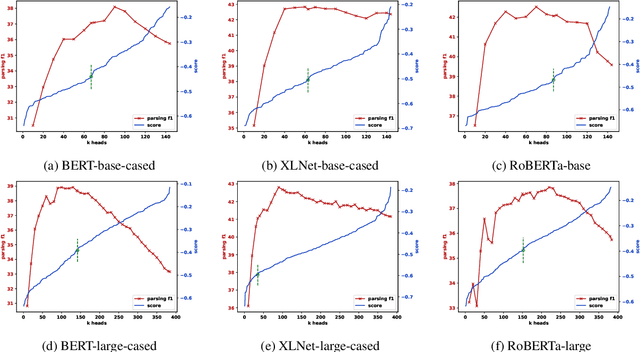
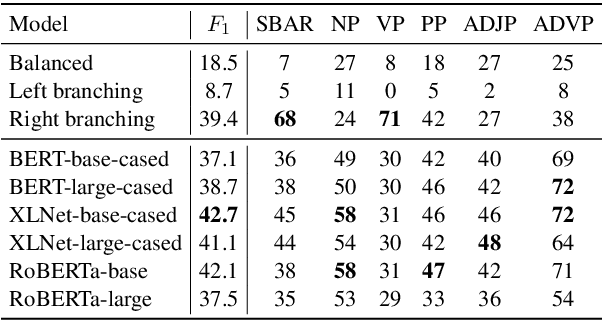
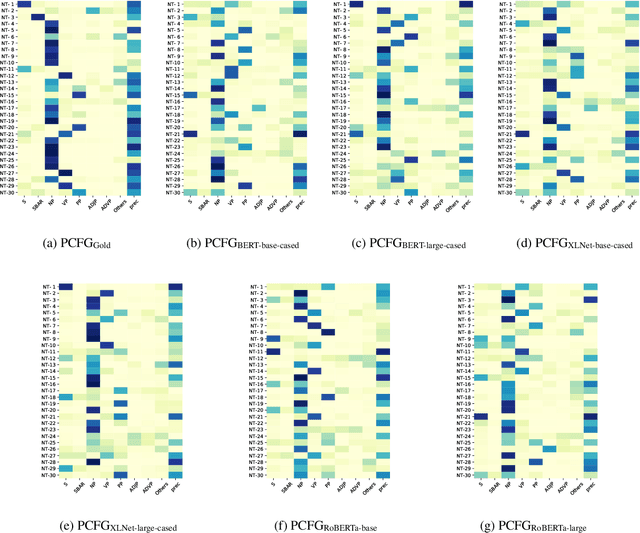
Transformer-based pre-trained language models (PLMs) have dramatically improved the state of the art in NLP across many tasks. This has led to substantial interest in analyzing the syntactic knowledge PLMs learn. Previous approaches to this question have been limited, mostly using test suites or probes. Here, we propose a novel fully unsupervised parsing approach that extracts constituency trees from PLM attention heads. We rank transformer attention heads based on their inherent properties, and create an ensemble of high-ranking heads to produce the final tree. Our method is adaptable to low-resource languages, as it does not rely on development sets, which can be expensive to annotate. Our experiments show that the proposed method often outperform existing approaches if there is no development set present. Our unsupervised parser can also be used as a tool to analyze the grammars PLMs learn implicitly. For this, we use the parse trees induced by our method to train a neural PCFG and compare it to a grammar derived from a human-annotated treebank.
Unsupervised Opinion Summarization with Noising and Denoising
Apr 21, 2020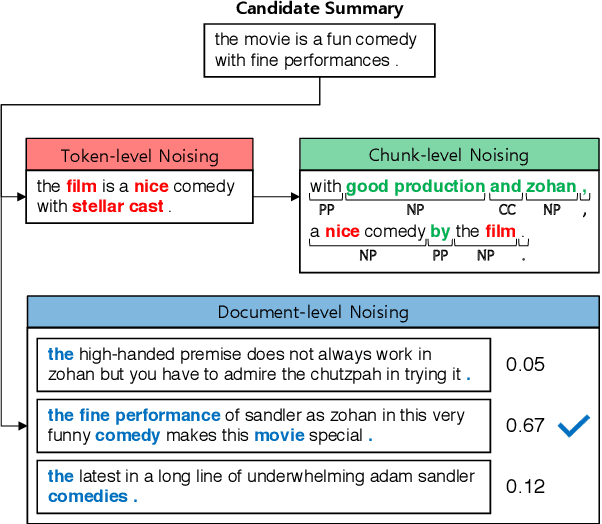
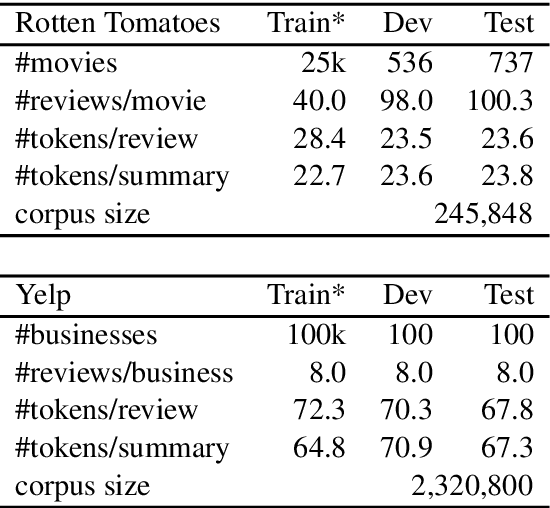
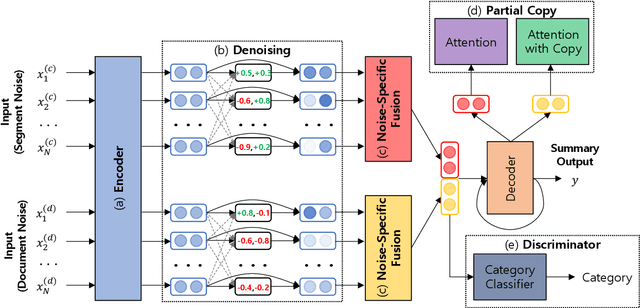
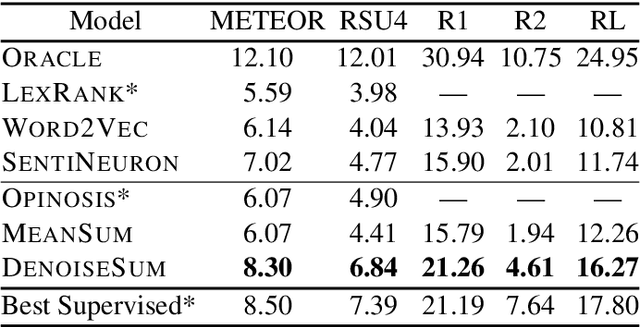
The supervised training of high-capacity models on large datasets containing hundreds of thousands of document-summary pairs is critical to the recent success of deep learning techniques for abstractive summarization. Unfortunately, in most domains (other than news) such training data is not available and cannot be easily sourced. In this paper we enable the use of supervised learning for the setting where there are only documents available (e.g.,~product or business reviews) without ground truth summaries. We create a synthetic dataset from a corpus of user reviews by sampling a review, pretending it is a summary, and generating noisy versions thereof which we treat as pseudo-review input. We introduce several linguistically motivated noise generation functions and a summarization model which learns to denoise the input and generate the original review. At test time, the model accepts genuine reviews and generates a summary containing salient opinions, treating those that do not reach consensus as noise. Extensive automatic and human evaluation shows that our model brings substantial improvements over both abstractive and extractive baselines.
Text Length Adaptation in Sentiment Classification
Sep 18, 2019
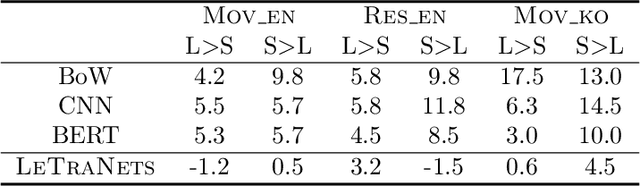
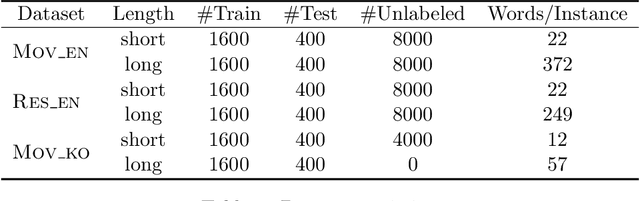
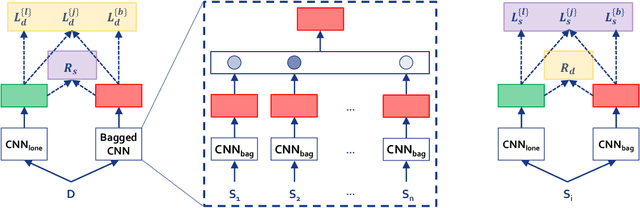
Can a text classifier generalize well for datasets where the text length is different? For example, when short reviews are sentiment-labeled, can these transfer to predict the sentiment of long reviews (i.e., short to long transfer), or vice versa? While unsupervised transfer learning has been well-studied for cross domain/lingual transfer tasks, Cross Length Transfer (CLT) has not yet been explored. One reason is the assumption that length difference is trivially transferable in classification. We show that it is not, because short/long texts differ in context richness and word intensity. We devise new benchmark datasets from diverse domains and languages, and show that existing models from similar tasks cannot deal with the unique challenge of transferring across text lengths. We introduce a strong baseline model called BaggedCNN that treats long texts as bags containing short texts. We propose a state-of-the-art CLT model called Length Transfer Networks (LeTraNets) that introduces a two-way encoding scheme for short and long texts using multiple training mechanisms. We test our models and find that existing models perform worse than the BaggedCNN baseline, while LeTraNets outperforms all models.
Informative and Controllable Opinion Summarization
Sep 05, 2019
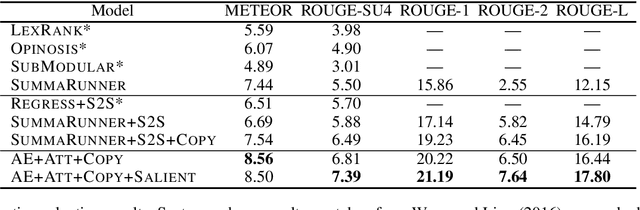
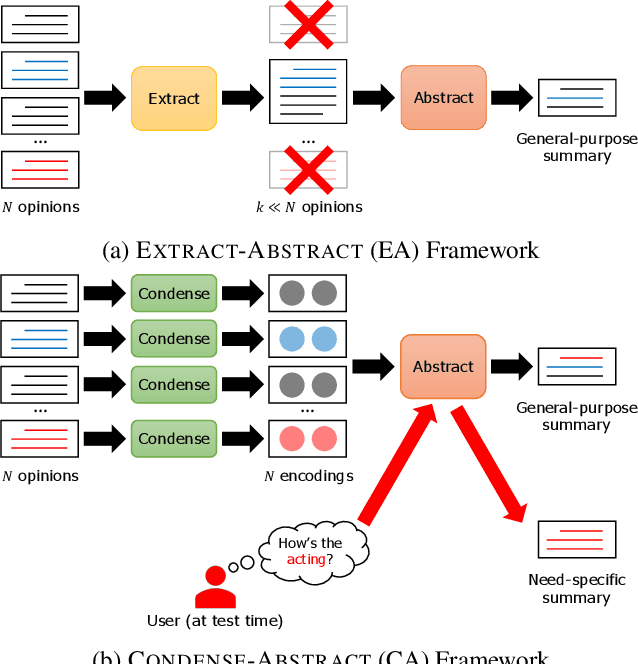

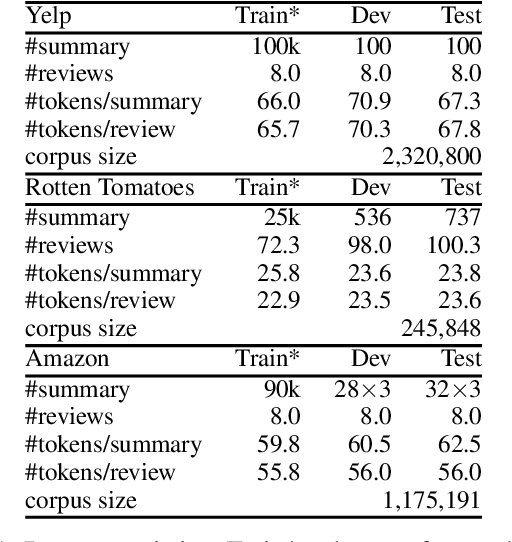
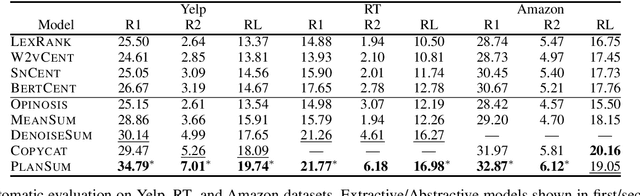
Opinion summarization is the task of automatically generating summaries for a set of opinions about a specific target (e.g., a movie or a product). Since the number of input documents can be prohibitively large, neural network-based methods sacrifice end-to-end elegance and follow a two-stage approach where an extractive model first pre-selects a subset of salient opinions and an abstractive model creates the summary while conditioning on the extracted subset. However, the extractive stage leads to information loss and inflexible generation capability. In this paper we propose a summarization framework that eliminates the need to pre-select salient content. We view opinion summarization as an instance of multi-source transduction, and make use of all input documents by condensing them into multiple dense vectors which serve as input to an abstractive model. Beyond producing more informative summaries, we demonstrate that our approach allows to take user preferences into account based on a simple zero-shot customization technique. Experimental results show that our model improves the state of the art on the Rotten Tomatoes dataset by a wide margin and generates customized summaries effectively.
Rethinking Attribute Representation and Injection for Sentiment Classification
Aug 26, 2019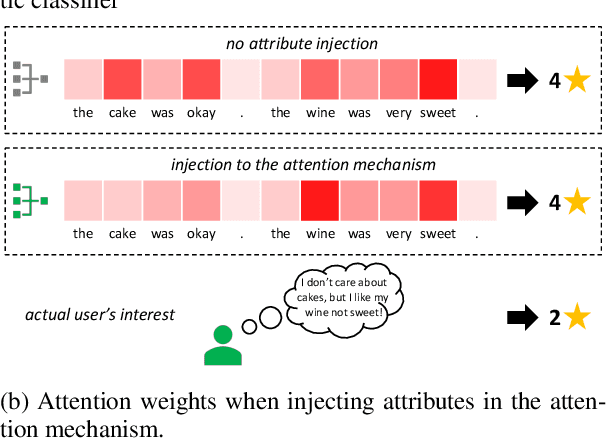

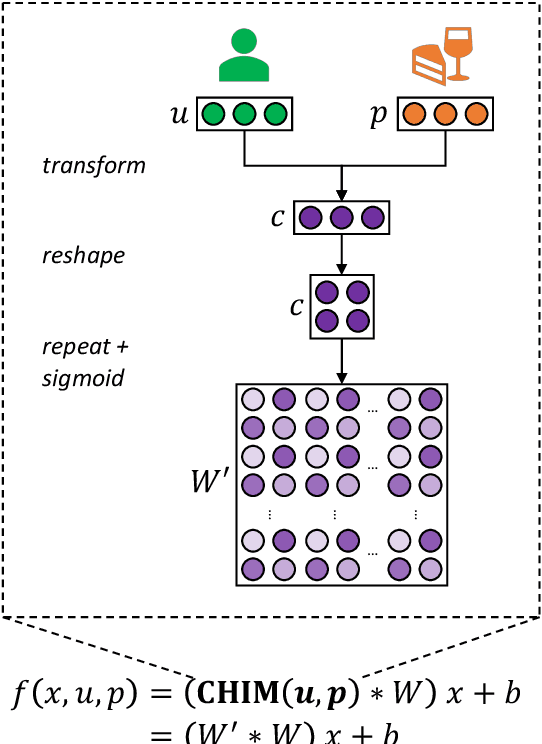
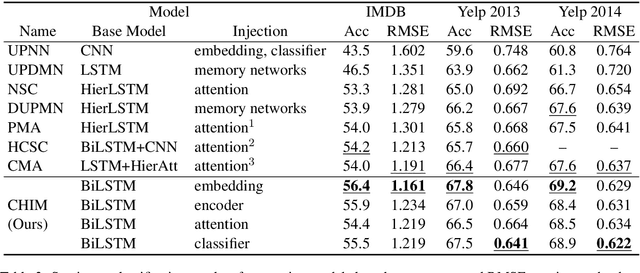
Text attributes, such as user and product information in product reviews, have been used to improve the performance of sentiment classification models. The de facto standard method is to incorporate them as additional biases in the attention mechanism, and more performance gains are achieved by extending the model architecture. In this paper, we show that the above method is the least effective way to represent and inject attributes. To demonstrate this hypothesis, unlike previous models with complicated architectures, we limit our base model to a simple BiLSTM with attention classifier, and instead focus on how and where the attributes should be incorporated in the model. We propose to represent attributes as chunk-wise importance weight matrices and consider four locations in the model (i.e., embedding, encoding, attention, classifier) to inject attributes. Experiments show that our proposed method achieves significant improvements over the standard approach and that attention mechanism is the worst location to inject attributes, contradicting prior work. We also outperform the state-of-the-art despite our use of a simple base model. Finally, we show that these representations transfer well to other tasks. Model implementation and datasets are released here: https://github.com/rktamplayo/CHIM.