 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Length Adaptation in Sentiment Classification
Sep 18, 2019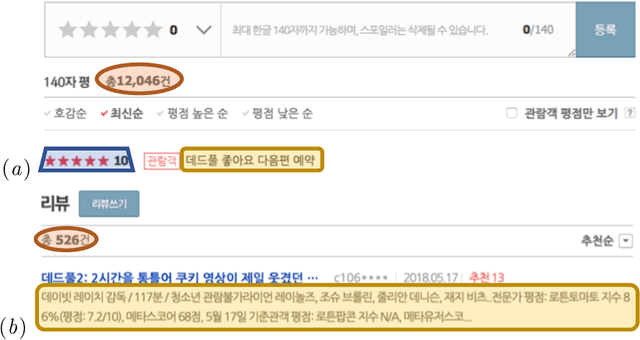
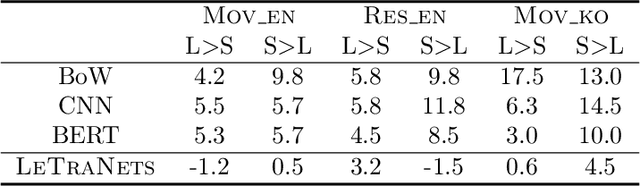
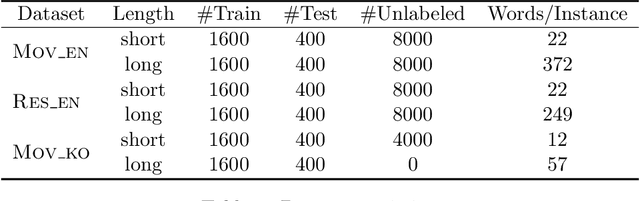
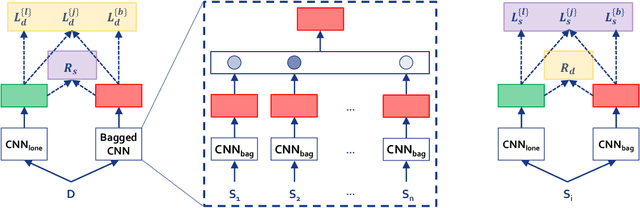
Can a text classifier generalize well for datasets where the text length is different? For example, when short reviews are sentiment-labeled, can these transfer to predict the sentiment of long reviews (i.e., short to long transfer), or vice versa? While unsupervised transfer learning has been well-studied for cross domain/lingual transfer tasks, Cross Length Transfer (CLT) has not yet been explored. One reason is the assumption that length difference is trivially transferable in classification. We show that it is not, because short/long texts differ in context richness and word intensity. We devise new benchmark datasets from diverse domains and languages, and show that existing models from similar tasks cannot deal with the unique challenge of transferring across text lengths. We introduce a strong baseline model called BaggedCNN that treats long texts as bags containing short texts. We propose a state-of-the-art CLT model called Length Transfer Networks (LeTraNets) that introduces a two-way encoding scheme for short and long texts using multiple training mechanisms. We test our models and find that existing models perform worse than the BaggedCNN baseline, while LeTraNets outperforms all models.
Entity Commonsense Representation for Neural Abstractive Summarization
Jun 14, 2018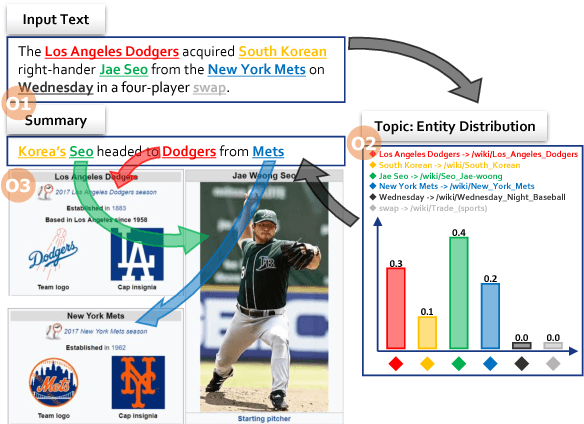
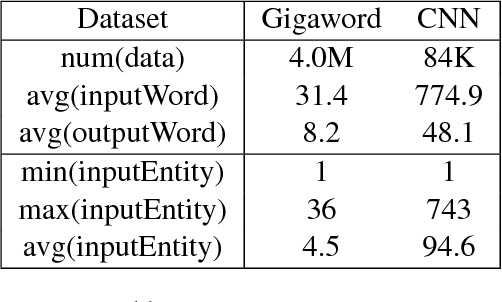
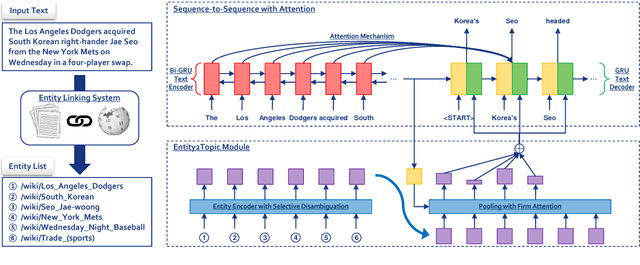
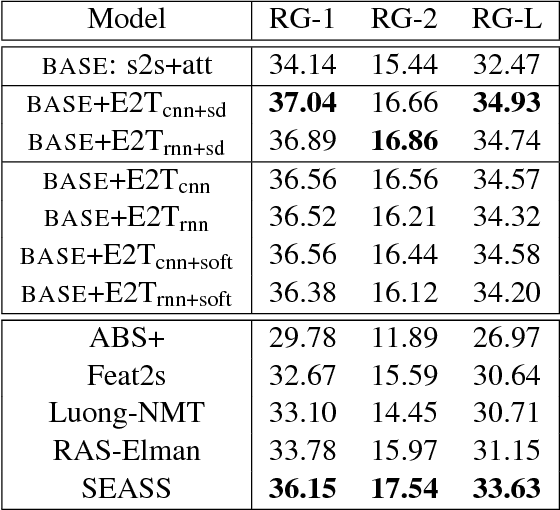
A major proportion of a text summary includes important entities found in the original text. These entities build up the topic of the summary. Moreover, they hold commonsense information once they are linked to a knowledge base. Based on these observations, this paper investigates the usage of linked entities to guide the decoder of a neural text summarizer to generate concise and better summaries. To this end, we leverage on an off-the-shelf entity linking system (ELS) to extract linked entities and propose Entity2Topic (E2T), a module easily attachable to a sequence-to-sequence model that transforms a list of entities into a vector representation of the topic of the summary. Current available ELS's are still not sufficiently effective, possibly introducing unresolved ambiguities and irrelevant entities. We resolve the imperfections of the ELS by (a) encoding entities with selective disambiguation, and (b) pooling entity vectors using firm attention. By applying E2T to a simple sequence-to-sequence model with attention mechanism as base model, we see significant improvements of the performance in the Gigaword (sentence to title) and CNN (long document to multi-sentence highlights) summarization datasets by at least 2 ROUGE points.
* NAACL 2018