 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabicNLU 2024: The First Arabic Natural Language Understanding Shared Task
Jul 30, 2024



This paper presents an overview of the Arabic Natural Language Understanding (ArabicNLU 2024) shared task, focusing on two subtasks: Word Sense Disambiguation (WSD) and Location Mention Disambiguation (LMD). The task aimed to evaluate the ability of automated systems to resolve word ambiguity and identify locations mentioned in Arabic text. We provided participants with novel datasets, including a sense-annotated corpus for WSD, called SALMA with approximately 34k annotated tokens, and the IDRISI-DA dataset with 3,893 annotations and 763 unique location mentions. These are challenging tasks. Out of the 38 registered teams, only three teams participated in the final evaluation phase, with the highest accuracy being 77.8% for WSD and the highest MRR@1 being 95.0% for LMD. The shared task not only facilitated the evaluation and comparison of different techniques, but also provided valuable insights and resources for the continued advancement of Arabic NLU technologies.
ArAIEval Shared Task: Propagandistic Techniques Detection in Unimodal and Multimodal Arabic Content
Jul 05, 2024



We present an overview of the second edition of the ArAIEval shared task, organized as part of the ArabicNLP 2024 conference co-located with ACL 2024. In this edition, ArAIEval offers two tasks: (i) detection of propagandistic textual spans with persuasion techniques identification in tweets and news articles, and (ii) distinguishing between propagandistic and non-propagandistic memes. A total of 14 teams participated in the final evaluation phase, with 6 and 9 teams participating in Tasks 1 and 2, respectively. Finally, 11 teams submitted system description papers. Across both tasks, we observed that fine-tuning transformer models such as AraBERT was at the core of the majority of the participating systems. We provide a description of the task setup, including a description of the dataset construction and the evaluation setup. We further provide a brief overview of the participating systems. All datasets and evaluation scripts are released to the research community (https://araieval.gitlab.io/). We hope this will enable further research on these important tasks in Arabic.
ThatiAR: Subjectivity Detection in Arabic News Sentences
Jun 08, 2024



Detecting subjectivity in news sentences is crucial for identifying media bias, enhancing credibility, and combating misinformation by flagging opinion-based content. It provides insights into public sentiment, empowers readers to make informed decisions, and encourages critical thinking. While research has developed methods and systems for this purpose, most efforts have focused on English and other high-resourced languages. In this study, we present the first large dataset for subjectivity detection in Arabic, consisting of ~3.6K manually annotated sentences, and GPT-4o based explanation. In addition, we included instructions (both in English and Arabic) to facilitate LLM based fine-tuning. We provide an in-depth analysis of the dataset, annotation process, and extensive benchmark results, including PLMs and LLMs. Our analysis of the annotation process highlights that annotators were strongly influenced by their political, cultural, and religious backgrounds, especially at the beginning of the annotation process. The experimental results suggest that LLMs with in-context learning provide better performance. We aim to release the dataset and resources for the community.
Overview of the CLEF-2019 CheckThat!: Automatic Identification and Verification of Claims
Sep 25, 2021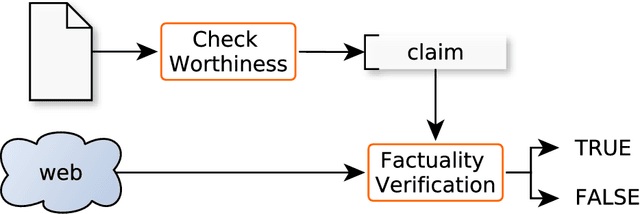


We present an overview of the second edition of the CheckThat! Lab at CLEF 2019. The lab featured two tasks in two different languages: English and Arabic. Task 1 (English) challenged the participating systems to predict which claims in a political debate or speech should be prioritized for fact-checking. Task 2 (Arabic) asked to (A) rank a given set of Web pages with respect to a check-worthy claim based on their usefulness for fact-checking that claim, (B) classify these same Web pages according to their degree of usefulness for fact-checking the target claim, (C) identify useful passages from these pages, and (D) use the useful pages to predict the claim's factuality. CheckThat! provided a full evaluation framework, consisting of data in English (derived from fact-checking sources) and Arabic (gathered and annotated from scratch) and evaluation based on mean average precision (MAP) and normalized discounted cumulative gain (nDCG) for ranking, and F1 for classification. A total of 47 teams registered to participate in this lab, and fourteen of them actually submitted runs (compared to nine last year). The evaluation results show that the most successful approaches to Task 1 used various neural networks and logistic regression. As for Task 2, learning-to-rank was used by the highest scoring runs for subtask A, while different classifiers were used in the other subtasks. We release to the research community all datasets from the lab as well as the evaluation scripts, which should enable further research in the important tasks of check-worthiness estimation and automatic claim verification.
* Check-worthiness Estimation, Fact-Checking, Veracity, Evidence-based Verification, Fake News Detection, Computational Journalism, Disinformation, Misinformation. arXiv admin note: text overlap with arXiv:2012.09263 by other authors
ArCOV19-Rumors: Arabic COVID-19 Twitter Dataset for Misinformation Detection
Oct 17, 2020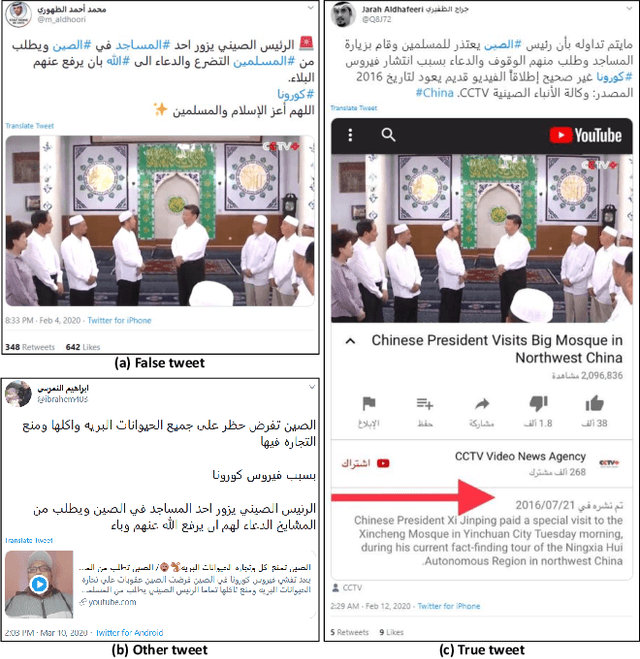
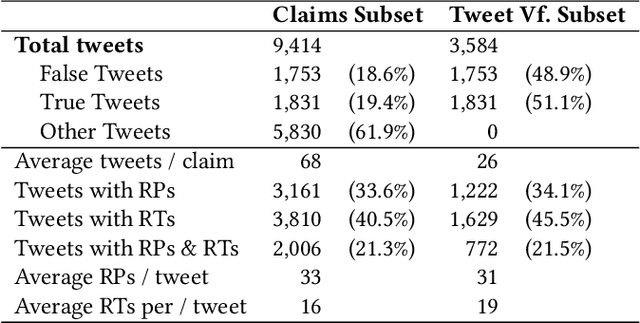
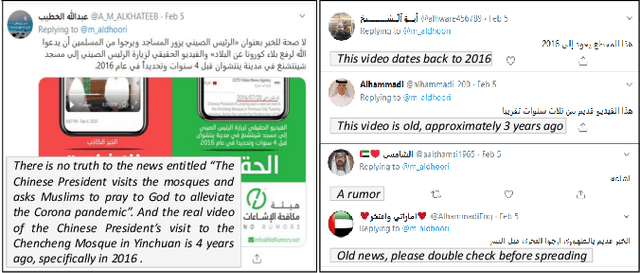
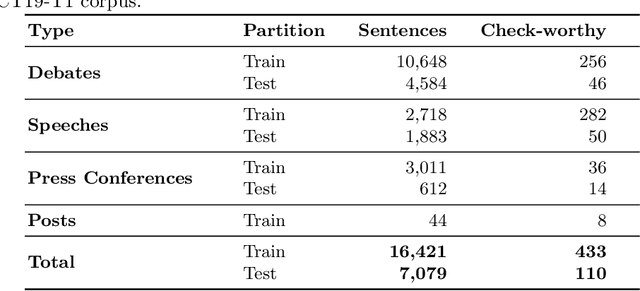
In this paper we introduce ArCOV19-Rumors, an Arabic COVID-19 Twitter dataset for misinformation detection composed of tweets containing claims from 27th January till the end of April 2020. We collected 138 verified claims, mostly from popular fact-checking websites, and identified 9.4K relevant tweets to those claims. We then manually-annotated the tweets by veracity to support research on misinformation detection, which is one of the major problems faced during a pandemic. We aim to support two classes of misinformation detection problems over Twitter: verifying free-text claims (called claim-level verification) and verifying claims expressed in tweets (called tweet-level verification). Our dataset covers, in addition to health, claims related to other topical categories that were influenced by COVID-19, namely, social, politics, sports, entertainment, and religious.
Overview of CheckThat! 2020: Automatic Identification and Verification of Claims in Social Media
Jul 15, 2020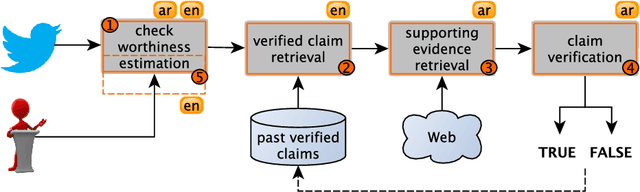
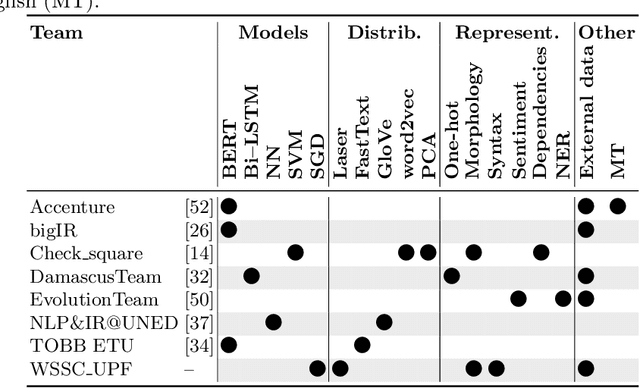
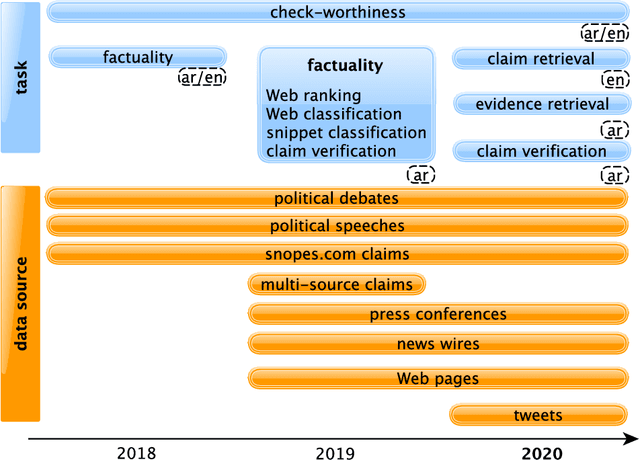
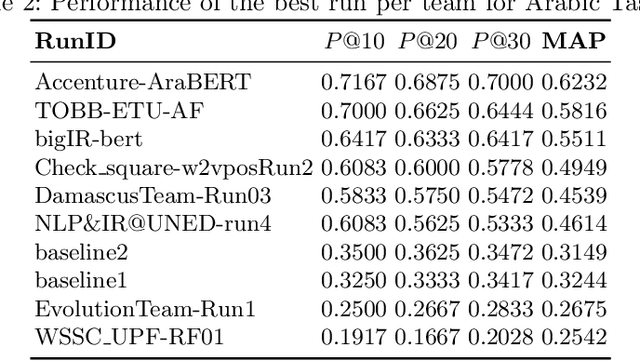
We present an overview of the third edition of the CheckThat! Lab at CLEF 2020. The lab featured five tasks in two different languages: English and Arabic. The first four tasks compose the full pipeline of claim verification in social media: Task 1 on check-worthiness estimation, Task 2 on retrieving previously fact-checked claims, Task 3 on evidence retrieval, and Task 4 on claim verification. The lab is completed with Task 5 on check-worthiness estimation in political debates and speeches. A total of 67 teams registered to participate in the lab (up from 47 at CLEF 2019), and 23 of them actually submitted runs (compared to 14 at CLEF 2019). Most teams used deep neural networks based on BERT, LSTMs, or CNNs, and achieved sizable improvements over the baselines on all tasks. Here we describe the tasks setup, the evaluation results, and a summary of the approaches used by the participants, and we discuss some lessons learned. Last but not least, we release to the research community all datasets from the lab as well as the evaluation scripts, which should enable further research in the important tasks of check-worthiness estimation and automatic claim verification.
* Check-Worthiness Estimation, Fact-Checking, Veracity, Evidence-based Verification, Detecting Previously Fact-Checked Claims, Social Media Verification, Computational Journalism, COVID-19
ArCOV-19: The First Arabic COVID-19 Twitter Dataset with Propagation Networks
Apr 18, 2020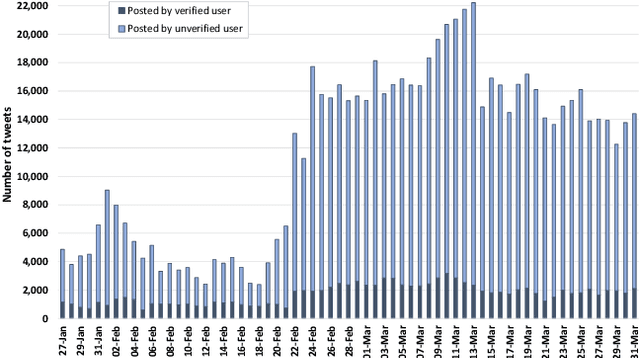
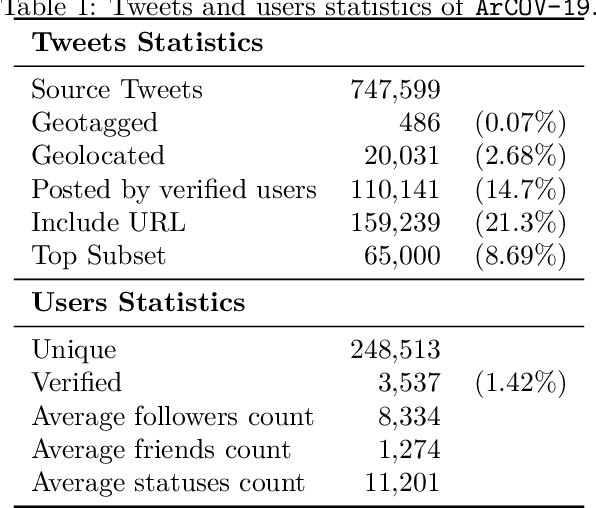
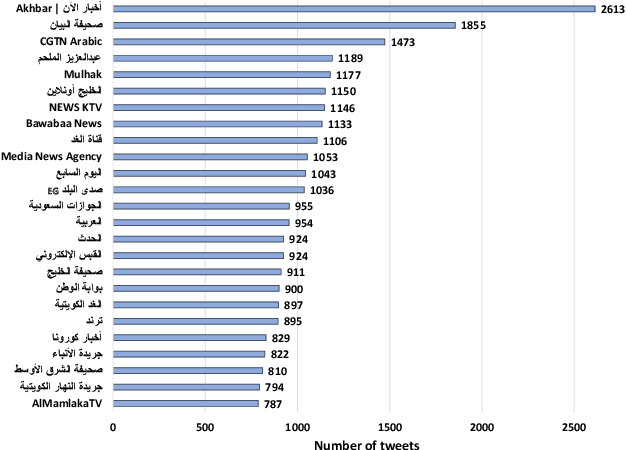
In this paper, we present ArCOV-19, an Arabic COVID-19 Twitter dataset that covers the period from 27th of January till 31st of March 2020. ArCOV-19 is the first publicly-available Arabic Twitter dataset covering COVID-19 pandemic that includes around 748k popular tweets (according to Twitter search criterion) alongside the propagation networks of the most-popular subset of them. The propagation networks include both retweets and conversational threads (i.e., threads of replies). ArCOV-19 is designed to enable research under several domains including natural language processing, information retrieval, and social computing, among others. Preliminary analysis shows that ArCOV-19 captures rising discussions associated with the first reported cases of the disease as they appeared in the Arab world. In addition to the source tweets and the propagation networks, we also release the search queries and the language-independent crawler used to collect the tweets to encourage the curation of similar datasets.
CheckThat! at CLEF 2020: Enabling the Automatic Identification and Verification of Claims in Social Media
Jan 21, 2020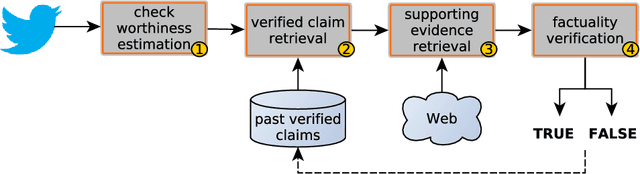
We describe the third edition of the CheckThat! Lab, which is part of the 2020 Cross-Language Evaluation Forum (CLEF). CheckThat! proposes four complementary tasks and a related task from previous lab editions, offered in English, Arabic, and Spanish. Task 1 asks to predict which tweets in a Twitter stream are worth fact-checking. Task 2 asks to determine whether a claim posted in a tweet can be verified using a set of previously fact-checked claims. Task 3 asks to retrieve text snippets from a given set of Web pages that would be useful for verifying a target tweet's claim. Task 4 asks to predict the veracity of a target tweet's claim using a set of Web pages and potentially useful snippets in them. Finally, the lab offers a fifth task that asks to predict the check-worthiness of the claims made in English political debates and speeches. CheckThat! features a full evaluation framework. The evaluation is carried out using mean average precision or precision at rank k for ranking tasks, and F1 for classification tasks.
* Computational journalism, Check-worthiness, Fact-checking, Veracity, CLEF-2020 CheckThat! Lab
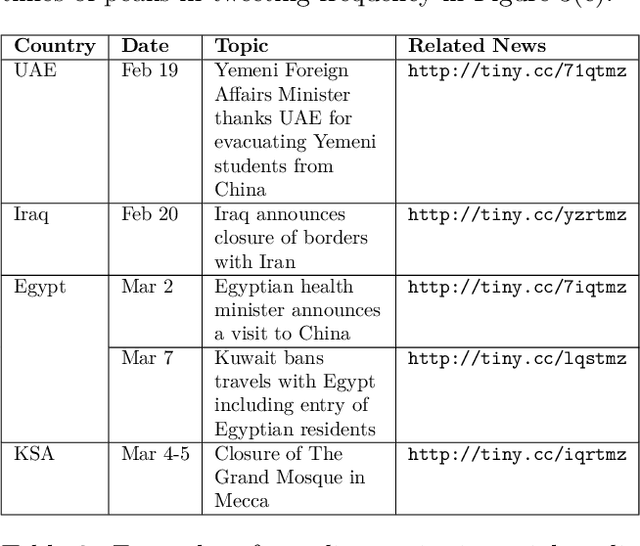
Overview of the CLEF-2018 CheckThat! Lab on Automatic Identification and Verification of Political Claims. Task 1: Check-Worthiness
Aug 08, 2018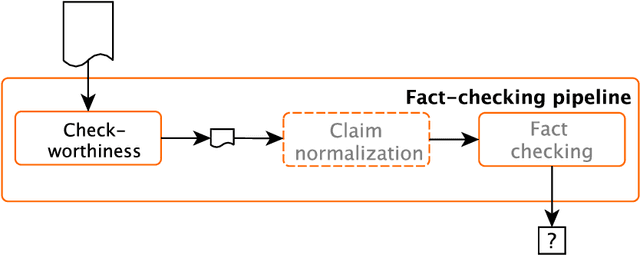
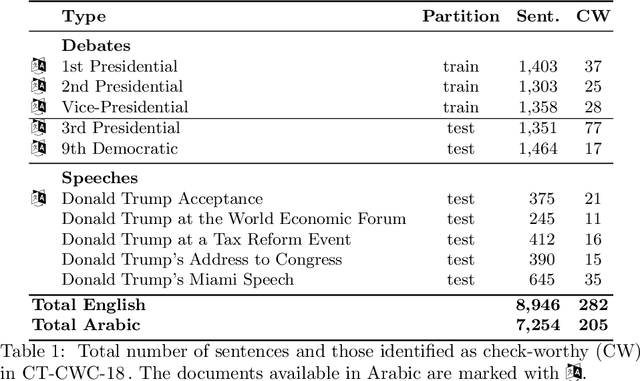

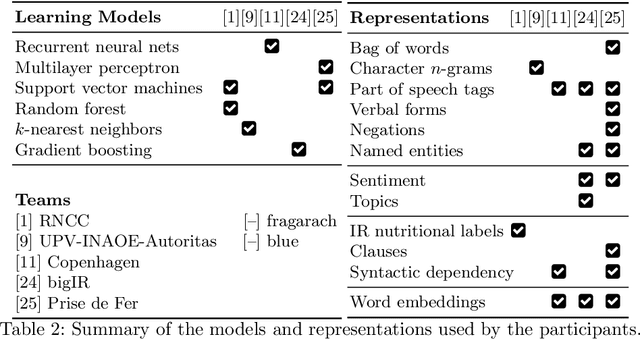
We present an overview of the CLEF-2018 CheckThat! Lab on Automatic Identification and Verification of Political Claims, with focus on Task 1: Check-Worthiness. The task asks to predict which claims in a political debate should be prioritized for fact-checking. In particular, given a debate or a political speech, the goal was to produce a ranked list of its sentences based on their worthiness for fact checking. We offered the task in both English and Arabic, based on debates from the 2016 US Presidential Campaign, as well as on some speeches during and after the campaign. A total of 30 teams registered to participate in the Lab and seven teams actually submitted systems for Task~1. The most successful approaches used by the participants relied on recurrent and multi-layer neural networks, as well as on combinations of distributional representations, on matchings claims' vocabulary against lexicons, and on measures of syntactic dependency. The best systems achieved mean average precision of 0.18 and 0.15 on the English and on the Arabic test datasets, respectively. This leaves large room for further improvement, and thus we release all datasets and the scoring scripts, which should enable further research in check-worthiness estimation.
* Computational journalism, Check-worthiness, Fact-checking, Veracity