 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Machine Learning for Public Policy: Use Cases, Gaps, and Research Directions
Oct 27, 2020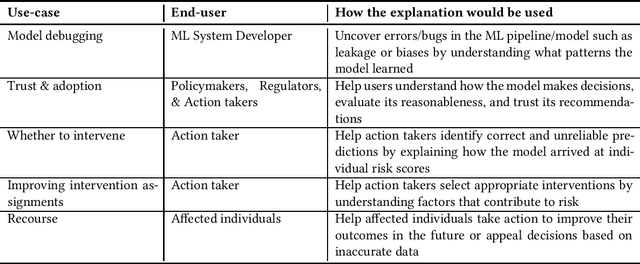
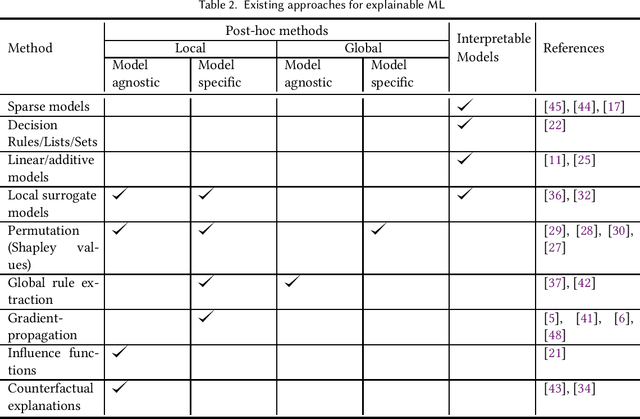
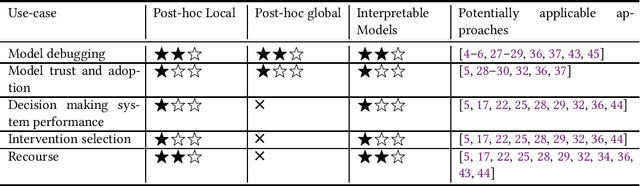
In Machine Learning (ML) models used for supporting decisions in high-stakes domains such as public policy, explainability is crucial for adoption and effectiveness. While the field of explainable ML has expanded in recent years, much of this work does not take real-world needs into account. A majority of proposed methods use benchmark ML problems with generic explainability goals without clear use-cases or intended end-users. As a result, the effectiveness of this large body of theoretical and methodological work on real-world applications is unclear. This paper focuses on filling this void for the domain of public policy. We develop a taxonomy of explainability use-cases within public policy problems; for each use-case, we define the end-users of explanations and the specific goals explainability has to fulfill; third, we map existing work to these use-cases, identify gaps, and propose research directions to fill those gaps in order to have practical policy impact through ML.
Bandit Data-driven Optimization: AI for Social Good and Beyond
Aug 26, 2020
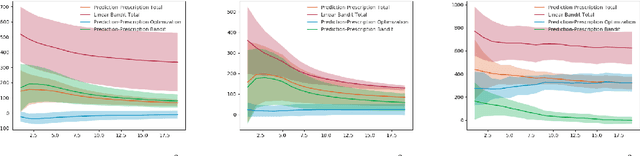
The use of machine learning (ML) systems in real-world applications entails more than just a prediction algorithm. AI for social good applications, and many real-world ML tasks in general, feature an iterative process which joins prediction, optimization, and data acquisition happen in a loop. We introduce bandit data-driven optimization, the first iterative prediction-prescription framework to formally analyze this practical routine. Bandit data-driven optimization combines the advantages of online bandit learning and offline predictive analytics in an integrated framework. It offers a flexible setup to reason about unmodeled policy objectives and unforeseen consequences. We propose PROOF, the first algorithm for this framework and show that it achieves no-regret. Using numerical simulations, we show that PROOF achieves superior performance over existing baseline.
A Recommendation and Risk Classification System for Connecting Rough Sleepers to Essential Outreach Services
Jul 30, 2020

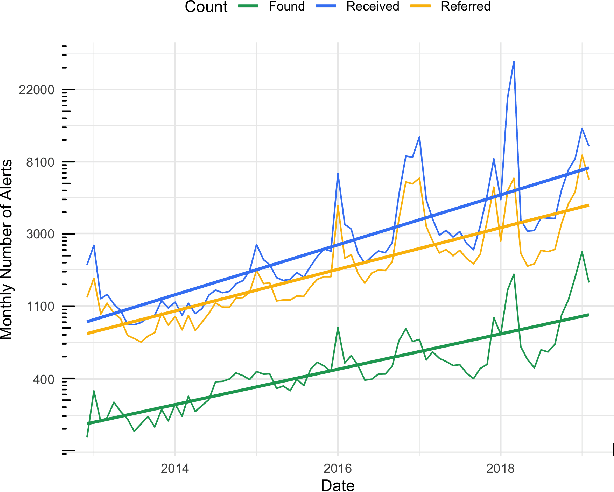

Rough sleeping is a chronic problem faced by some of the most disadvantaged people in modern society. This paper describes work carried out in partnership with Homeless Link, a UK-based charity, in developing a data-driven approach to assess the quality of incoming alerts from members of the public aimed at connecting people sleeping rough on the streets with outreach service providers. Alerts are prioritised based on the predicted likelihood of successfully connecting with the rough sleeper, helping to address capacity limitations and to quickly, effectively, and equitably process all of the alerts that they receive. Initial evaluation concludes that our approach increases the rate at which rough sleepers are found following a referral by at least 15\% based on labelled data, implying a greater overall increase when the alerts with unknown outcomes are considered, and suggesting the benefit in a trial taking place over a longer period to assess the models in practice. The discussion and modelling process is done with careful considerations of ethics, transparency and explainability due to the sensitive nature of the data in this context and the vulnerability of the people that are affected.
A Machine Learning System for Retaining Patients in HIV Care
Jun 01, 2020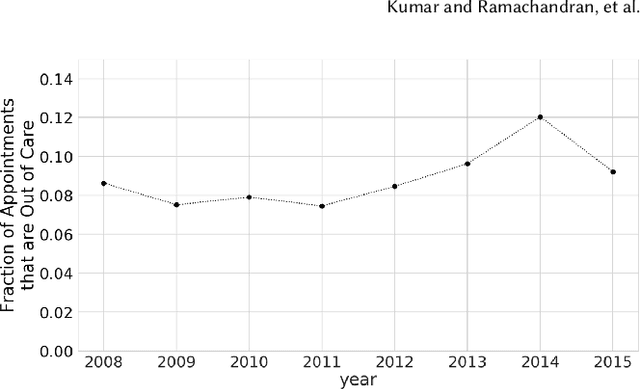
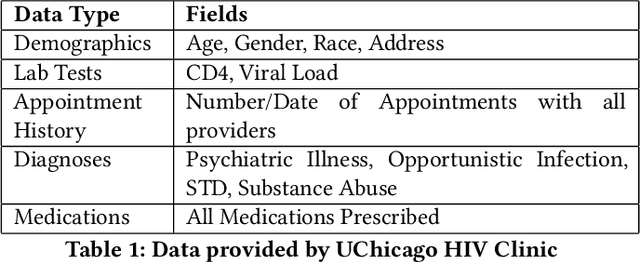

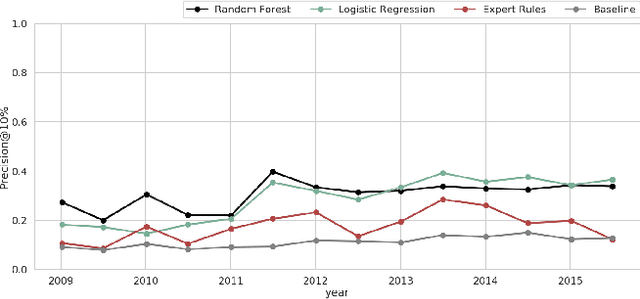
Retaining persons living with HIV (PLWH) in medical care is paramount to preventing new transmissions of the virus and allowing PLWH to live normal and healthy lifespans. Maintaining regular appointments with an HIV provider and taking medication daily for a lifetime is exceedingly difficult. 51% of PLWH are non-adherent with their medications and eventually drop out of medical care. Current methods of re-linking individuals to care are reactive (after a patient has dropped-out) and hence not very effective. We describe our system to predict who is most at risk to drop-out-of-care for use by the University of Chicago HIV clinic and the Chicago Department of Public Health. Models were selected based on their predictive performance under resource constraints, stability over time, as well as fairness. Our system is applicable as a point-of-care system in a clinical setting as well as a batch prediction system to support regular interventions at the city level. Our model performs 3x better than the baseline for the clinical model and 2.3x better than baseline for the city-wide model. The code has been released on github and we hope this methodology, particularly our focus on fairness, will be adopted by other clinics and public health agencies in order to curb the HIV epidemic.
Case Study: Predictive Fairness to Reduce Misdemeanor Recidivism Through Social Service Interventions
Jan 24, 2020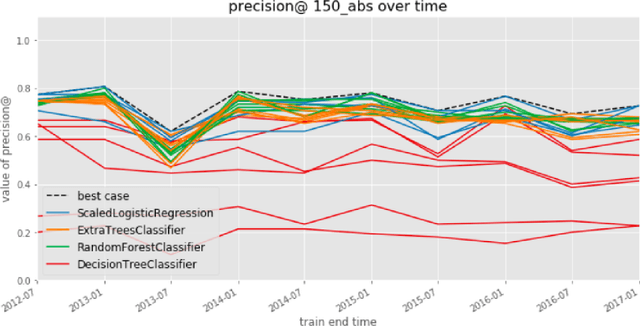
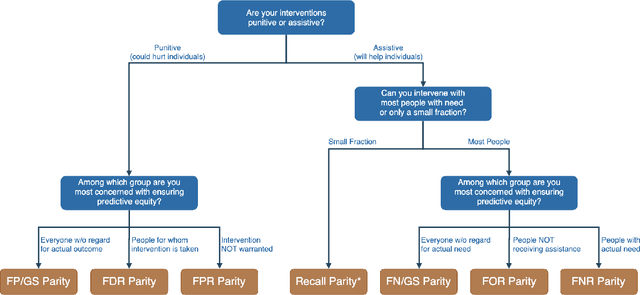
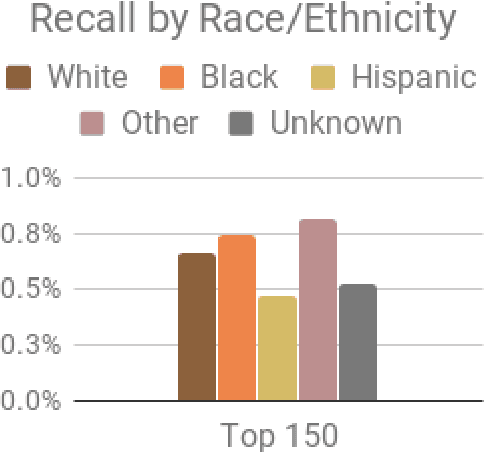
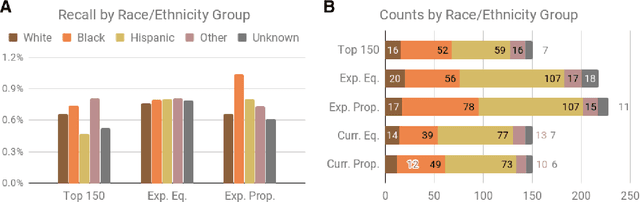
The criminal justice system is currently ill-equipped to improve outcomes of individuals who cycle in and out of the system with a series of misdemeanor offenses. Often due to constraints of caseload and poor record linkage, prior interactions with an individual may not be considered when an individual comes back into the system, let alone in a proactive manner through the application of diversion programs. The Los Angeles City Attorney's Office recently created a new Recidivism Reduction and Drug Diversion unit (R2D2) tasked with reducing recidivism in this population. Here we describe a collaboration with this new unit as a case study for the incorporation of predictive equity into machine learning based decision making in a resource-constrained setting. The program seeks to improve outcomes by developing individually-tailored social service interventions (i.e., diversions, conditional plea agreements, stayed sentencing, or other favorable case disposition based on appropriate social service linkage rather than traditional sentencing methods) for individuals likely to experience subsequent interactions with the criminal justice system, a time and resource-intensive undertaking that necessitates an ability to focus resources on individuals most likely to be involved in a future case. Seeking to achieve both efficiency (through predictive accuracy) and equity (improving outcomes in traditionally under-served communities and working to mitigate existing disparities in criminal justice outcomes), we discuss the equity outcomes we seek to achieve, describe the corresponding choice of a metric for measuring predictive fairness in this context, and explore a set of options for balancing equity and efficiency when building and selecting machine learning models in an operational public policy setting.
A Clinical Approach to Training Effective Data Scientists
May 15, 2019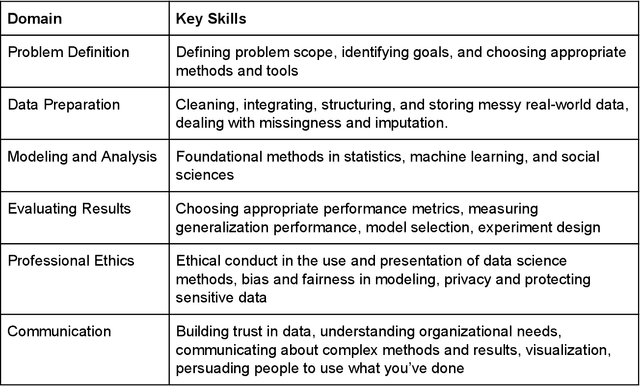
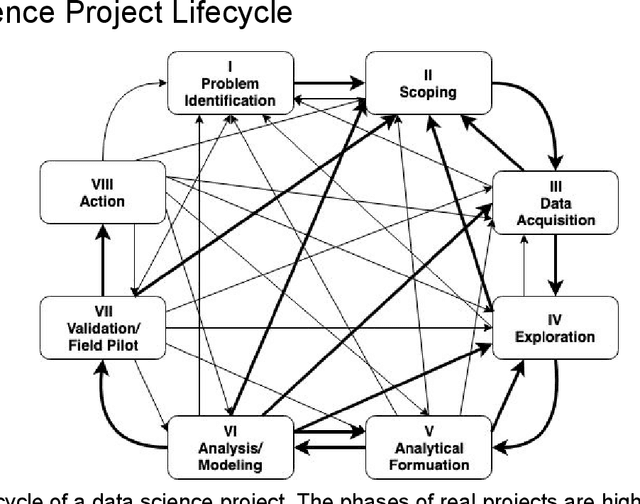
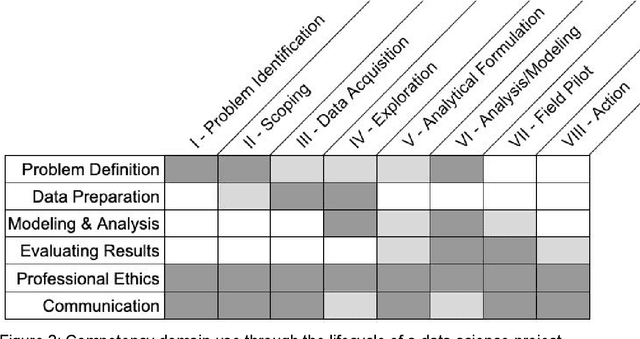
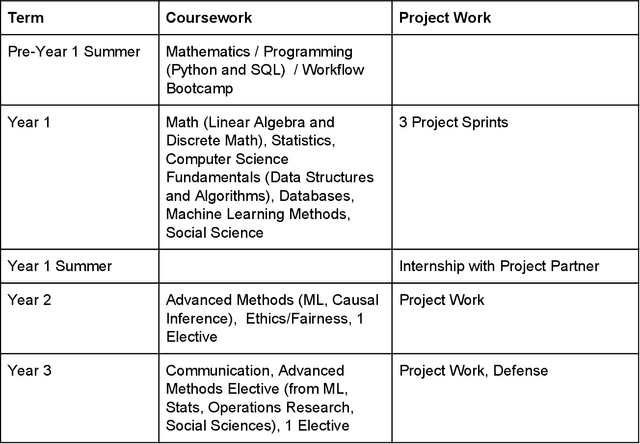
Like medicine, psychology, or education, data science is fundamentally an applied discipline, with most students who receive advanced degrees in the field going on to work on practical problems. Unlike these disciplines, however, data science education remains heavily focused on theory and methods, and practical coursework typically revolves around cleaned or simplified data sets that have little analog in professional applications. We believe that the environment in which new data scientists are trained should more accurately reflect that in which they will eventually practice and propose here a data science master's degree program that takes inspiration from the residency model used in medicine. Students in the suggested program would spend three years working on a practical problem with an industry, government, or nonprofit partner, supplemented with coursework in data science methods and theory. We also discuss how this program can also be implemented in shorter formats to augment existing professional masters programs in different disciplines. This approach to learning by doing is designed to fill gaps in our current approach to data science education and ensure that students develop the skills they need to practice data science in a professional context and under the many constraints imposed by that context.
Machine learning and AI research for Patient Benefit: 20 Critical Questions on Transparency, Replicability, Ethics and Effectiveness
Dec 21, 2018Machine learning (ML), artificial intelligence (AI) and other modern statistical methods are providing new opportunities to operationalize previously untapped and rapidly growing sources of data for patient benefit. Whilst there is a lot of promising research currently being undertaken, the literature as a whole lacks: transparency; clear reporting to facilitate replicability; exploration for potential ethical concerns; and, clear demonstrations of effectiveness. There are many reasons for why these issues exist, but one of the most important that we provide a preliminary solution for here is the current lack of ML/AI- specific best practice guidance. Although there is no consensus on what best practice looks in this field, we believe that interdisciplinary groups pursuing research and impact projects in the ML/AI for health domain would benefit from answering a series of questions based on the important issues that exist when undertaking work of this nature. Here we present 20 questions that span the entire project life cycle, from inception, data analysis, and model evaluation, to implementation, as a means to facilitate project planning and post-hoc (structured) independent evaluation. By beginning to answer these questions in different settings, we can start to understand what constitutes a good answer, and we expect that the resulting discussion will be central to developing an international consensus framework for transparent, replicable, ethical and effective research in artificial intelligence (AI-TREE) for health.
Aequitas: A Bias and Fairness Audit Toolkit
Nov 14, 2018
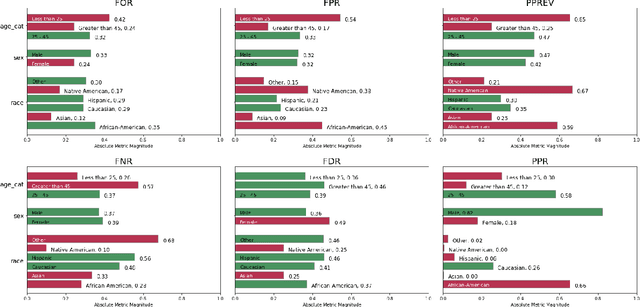
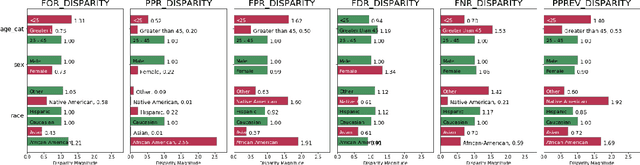
Recent work has raised concerns on the risk of unintended bias in algorithmic decision making systems being used nowadays that can affect individuals unfairly based on race, gender or religion, among other possible characteristics. While a lot of bias metrics and fairness definitions have been proposed in recent years, there is no consensus on which metric/definition should be used and there are very few available resources to operationalize them. Therefore, despite recent awareness, auditing for bias and fairness when developing and deploying algorithmic decision making systems is not yet a standard practice. We present Aequitas, an open source bias and fairness audit toolkit that is an intuitive and easy to use addition to the machine learning workflow, enabling users to seamlessly test models for several bias and fairness metrics in relation to multiple population sub-groups. We believe Aequitas will facilitate informed and equitable decisions around developing and deploying algorithmic decision making systems for both data scientists, machine learning researchers and policymakers.