 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorello: Compiling Fast Neural Networks with Dynamic Programming and Spatial Compression
May 03, 2025

High-throughput neural network inference requires coordinating many optimization decisions, including parallel tiling, microkernel selection, and data layout. The product of these decisions forms a search space of programs which is typically intractably large. Existing approaches (e.g., auto-schedulers) often address this problem by sampling this space heuristically. In contrast, we introduce a dynamic-programming-based approach to explore more of the search space by iteratively decomposing large program specifications into smaller specifications reachable from a set of rewrites, then composing a final program from each rewrite that minimizes an affine cost model. To reduce memory requirements, we employ a novel memoization table representation, which indexes specifications by coordinates in $Z_{\geq 0}$ and compresses identical, adjacent solutions. This approach can visit a much larger set of programs than prior work. To evaluate the approach, we developed Morello, a compiler which lowers specifications roughly equivalent to a few-node XLA computation graph to x86. Notably, we found that an affine cost model is sufficient to surface high-throughput programs. For example, Morello synthesized a collection of matrix multiplication benchmarks targeting a Zen 1 CPU, including a 1x2048x16384, bfloat16-to-float32 vector-matrix multiply, which was integrated into Google's gemma.cpp.
Swift: Compiled Inference for Probabilistic Programming Languages
Jun 30, 2016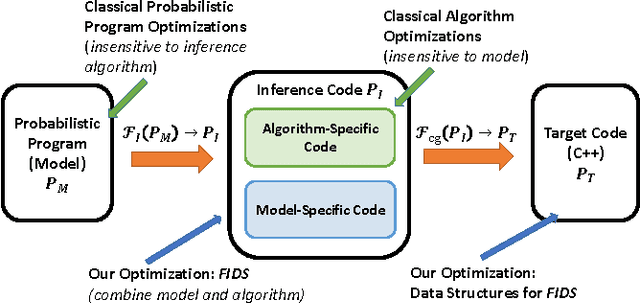
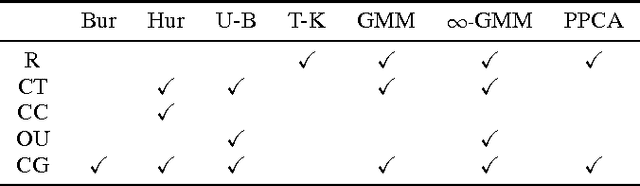

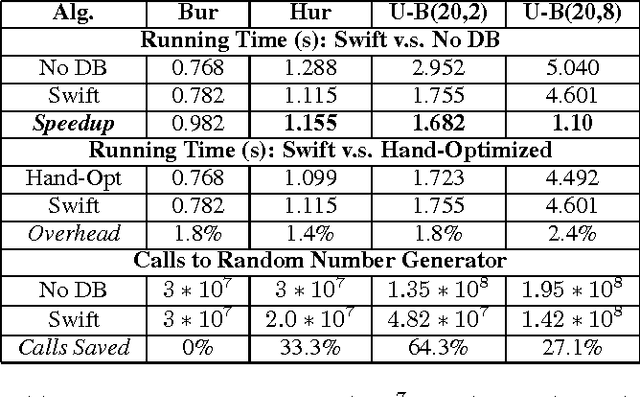
A probabilistic program defines a probability measure over its semantic structures. One common goal of probabilistic programming languages (PPLs) is to compute posterior probabilities for arbitrary models and queries, given observed evidence, using a generic inference engine. Most PPL inference engines---even the compiled ones---incur significant runtime interpretation overhead, especially for contingent and open-universe models. This paper describes Swift, a compiler for the BLOG PPL. Swift-generated code incorporates optimizations that eliminate interpretation overhead, maintain dynamic dependencies efficiently, and handle memory management for possible worlds of varying sizes. Experiments comparing Swift with other PPL engines on a variety of inference problems demonstrate speedups ranging from 12x to 326x.