 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2FAST-2LAMAA: A Lidar-Inertial Localisation and Mapping Framework for Non-Static Environments
Oct 07, 2024



This document presents a framework for lidar-inertial localisation and mapping named 2Fast-2Lamaa. The method revolves around two main steps which are the inertial-aided undistortion of the lidar data and the scan-to-map registration using a distance-field representation of the environment. The initialisation-free undistortion uses inertial data to constrain the continuous trajectory of the sensor during the lidar scan. The eleven DoFs that fully characterise the trajectory are estimated by minimising lidar point-to-line and point-to-plane distances in a non-linear least-square formulation. The registration uses a map that provides a distance field for the environment based on Gaussian Process regression. The pose of an undistorted lidar scan is optimised to minimise the distance field queries of its points with respect to the map. After registration, the new geometric information is efficiently integrated into the map. The soundness of 2Fast-2Lamaa is demonstrated over several datasets (qualitative evaluation only). The real-time implementation is made publicly available at https://github.com/UTS-RI/2fast2lamaa.
Real-Time Truly-Coupled Lidar-Inertial Motion Correction and Spatiotemporal Dynamic Object Detection
Oct 07, 2024



Over the past decade, lidars have become a cornerstone of robotics state estimation and perception thanks to their ability to provide accurate geometric information about their surroundings in the form of 3D scans. Unfortunately, most of nowadays lidars do not take snapshots of the environment but sweep the environment over a period of time (typically around 100 ms). Such a rolling-shutter-like mechanism introduces motion distortion into the collected lidar scan, thus hindering downstream perception applications. In this paper, we present a novel method for motion distortion correction of lidar data by tightly coupling lidar with Inertial Measurement Unit (IMU) data. The motivation of this work is a map-free dynamic object detection based on lidar. The proposed lidar data undistortion method relies on continuous preintegrated of IMU measurements that allow parameterising the sensors' continuous 6-DoF trajectory using solely eleven discrete state variables (biases, initial velocity, and gravity direction). The undistortion consists of feature-based distance minimisation of point-to-line and point-to-plane residuals in a non-linear least-square formulation. Given undistorted geometric data over a short temporal window, the proposed pipeline computes the spatiotemporal normal vector of each of the lidar points. The temporal component of the normals is a proxy for the corresponding point's velocity, therefore allowing for learning-free dynamic object classification without the need for registration in a global reference frame. We demonstrate the soundness of the proposed method and its different components using public datasets and compare them with state-of-the-art lidar-inertial state estimation and dynamic object detection algorithms.
Dynamic Object Detection in Range data using Spatiotemporal Normals
Oct 20, 2023



On the journey to enable robots to interact with the real world where humans, animals, and unpredictable elements are acting as independent agents; it is crucial for robots to have the capability to detect dynamic objects. In this paper, we argue that the detection of dynamic objects can be solved by computing the spatiotemporal normals of a point cloud. In our experiments, we demonstrate that this simple method can be used robustly for LiDAR and depth cameras with performances similar to the state of the art while offering a significantly simpler method.
Semantic keypoint extraction for scanned animals using multi-depth-camera systems
Nov 16, 2022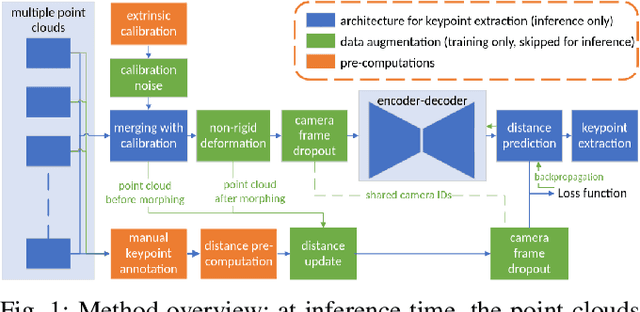
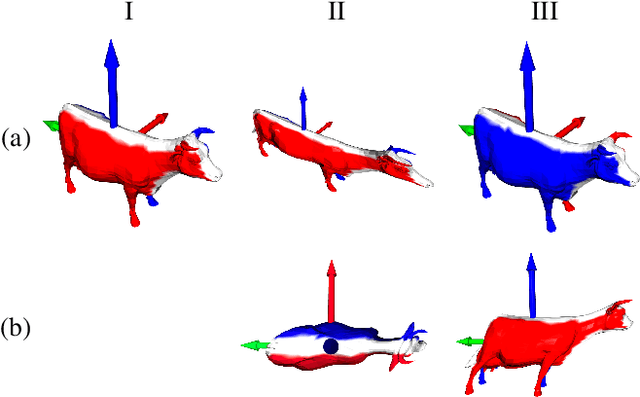
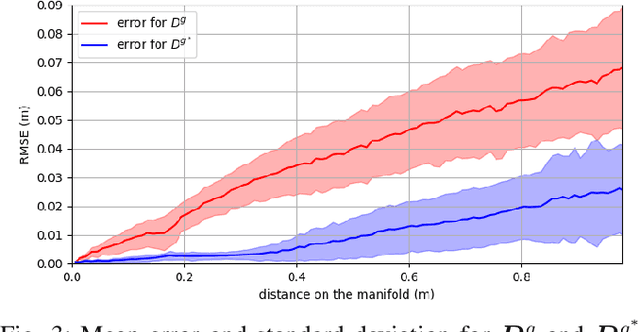

Keypoint annotation in point clouds is an important task for 3D reconstruction, object tracking and alignment, in particular in deformable or moving scenes. In the context of agriculture robotics, it is a critical task for livestock automation to work toward condition assessment or behaviour recognition. In this work, we propose a novel approach for semantic keypoint annotation in point clouds, by reformulating the keypoint extraction as a regression problem of the distance between the keypoints and the rest of the point cloud. We use the distance on the point cloud manifold mapped into a radial basis function (RBF), which is then learned using an encoder-decoder architecture. Special consideration is given to the data augmentation specific to multi-depth-camera systems by considering noise over the extrinsic calibration and camera frame dropout. Additionally, we investigate computationally efficient non-rigid deformation methods that can be applied to animal point clouds. Our method is tested on data collected in the field, on moving beef cattle, with a calibrated system of multiple hardware-synchronised RGB-D cameras.